mq使用的目的
- 应用解耦:屏蔽实现细节、异步通信,升级、扩容互不影响
- 流量消峰:生产速率>消息速率、消息积压能力、秒杀系统、批量导入
- 消息广播
- 最终一致性
kafka多实例、多分区、多副本:
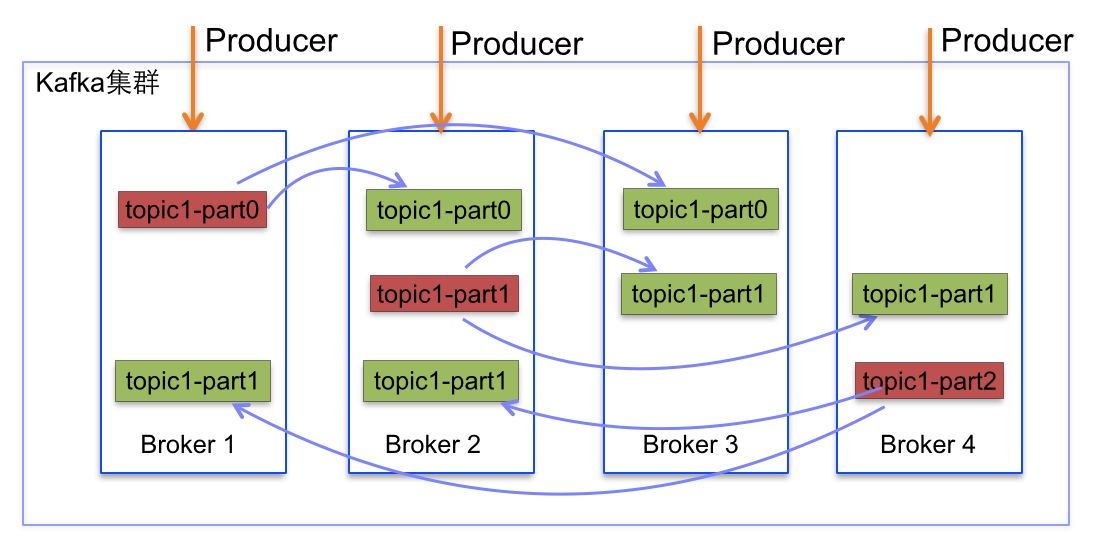
1、说明:
kafka实例:有四个Broker(四个kafka实例),多实例保证一个broker挂了,整个集群还能继续使用,高可用;
该topic有三个分区:part0,part1,part2,多分区,可以并行、并发比如写入消息到某一个topic,高吞吐量;
每个分区有两个副本,比如part0,在Broker2和Broker3中有两个副本(follower),在Broker1中的part0是leader,负责与生产者、消费者进行消息的生产和消费;leader分区还有一个任务就是将自己收到的消费同步到他的两个副本中;多副本保障的也是高可用,不至于因为一个副本的丢失导致整个消息的丢失;
2、意义:
一个topic,为什么要有多个part:为了方便多个生产者忘多个part并发写入消息,提供吞吐量;
一个part,为什么要有多个副本:为了防止某个broker宕机,导致消息的丢失,提高可用性;
几个名词
ISR(In-Sync Replicas):副本 同步队列,
OSR(Outof-Sync Replicas):副本 非同步队列
AR(Assigned Replicas)= ISR+OSR
我们知道副本数对Kafka的吞吐率是有一定的影响,但极大的增强了可用性。所有的副本(replicas)统称为Assigned Replicas,即AR。ISR是AR中的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟,任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中,即AR=ISR+OSR。
HW(HighWatermark):consumer能够看到的此partition的位置,即消费者能消费到的消息,消费者可见的消息,这个涉及到多副本的概念,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。
LEO(LogEndOffset):表示每个partition的log最后一条Message的位置。
下图详细的说明了当producer生产消息至broker后,ISR以及HW和LEO的流转过程:
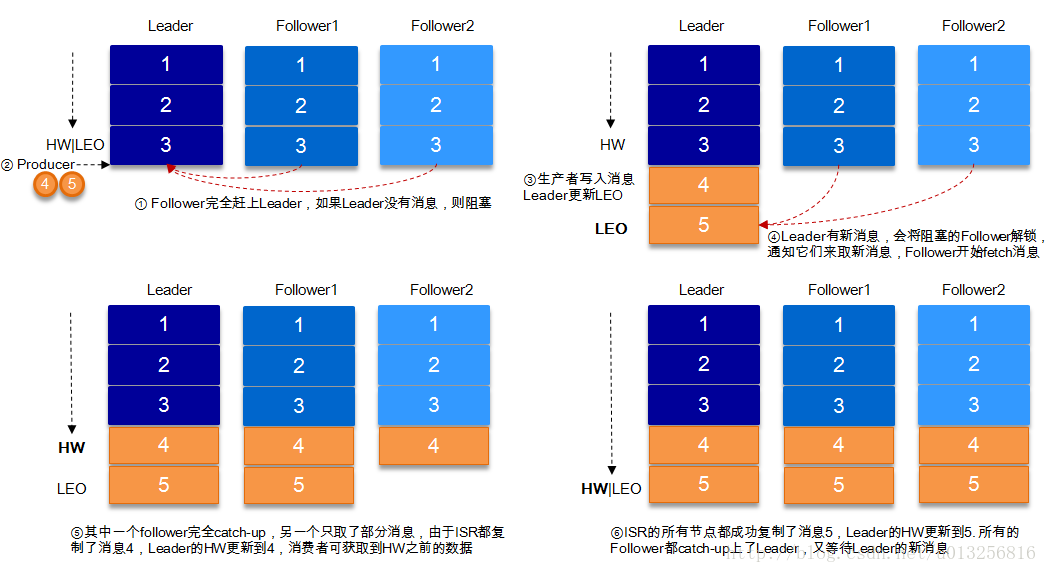
由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。一条消息只有被ISR中的所有follower都从leader复制过去才会被认为已提交。这样就避免了部分数据被写进了leader,还没来得及被任何follower复制就宕机了,而造成数据丢失。而对于producer而言,它可以选择是否等待消息commit,这可以通过request.required.acks来设置。这种机制确保了只要ISR中有一个或者以上的follower,一条被commit的消息就不会丢失。
Consumer Group:同样是逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)。
Consumer Group延伸论述:
什么是消费者组
什么是consumer group? 一言以蔽之,consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。理解consumer group记住下面这三个特性就好了:
- consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程
- group.id是一个字符串,唯一标识一个consumer group
- consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
消费者位置(consumer position)
消费者在消费的过程中需要记录自己消费了多少数据,即消费位置信息。在Kafka中这个位置信息有个专门的术语:位移(offset)。很多消息引擎都把这部分信息保存在服务器端(broker端)。这样做的好处当然是实现简单,但会有三个主要的问题:1. broker从此变成有状态的,会影响伸缩性;2. 需要引入应答机制(acknowledgement)来确认消费成功。3. 由于要保存很多consumer的offset信息,必然引入复杂的数据结构,造成资源浪费。而Kafka选择了不同的方式:每个consumer group保存自己的位移信息,那么只需要简单的一个整数表示位置就够了;同时可以引入checkpoint机制定期持久化,简化了应答机制的实现。
kafka日志文件结构:链接:Kafka文件存储机制那些事
下面示意图形象说明了partition中文件存储方式:
图1
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
partiton中segment文件存储结构
读者从2.2节了解到Kafka文件系统partition存储方式,本节深入分析partion中segment file组成和物理结构。
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
下面文件列表是笔者在Kafka broker上做的一个实验,创建一个topicXXX包含1 partition,设置每个segment大小为500MB,并启动producer向Kafka broker写入大量数据,如下图2所示segment文件列表形象说明了上述2个规则:
图2
以上述图2中一对segment file文件为例,说明segment中index<—->data file对应关系物理结构如下:
图3
上述图3中索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。
其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
参考:
深度分析kafka可靠性良心好文:kafka数据可靠性深度解读
深入分析消费组良心好文:消费组详解
消费组&&topic多分区的分配详解,真心好文好文,深入且易懂:kafka中partition和消费者对应关系
