目前开源的消息中间件可谓是琳琅满目,能让大家耳熟能详的就有很多,比如ActiveMQ、RabbitMQ、Kafka、RocketMQ、ZeroMQ等。
一:各类消息队列简述:
1、ActiveMQ是Apache出品的、采用Java语言编写的完全基于JMS1.1规范的面向消息的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。不过由于历史原因包袱太重,目前市场份额没有后面三种消息中间件多。
2、RabbitMQ是采用Erlang语言实现的AMQP协议的消息中间件,最初起源于金融系统,用于在分布式系统中存储转发消息。RabbitMQ发展到今天,被越来越多的人认可,这和它在可靠性、可用性、扩展性、功能丰富等方面的卓越表现是分不开的。
3、Kafka起初是由LinkedIn公司采用Scala语言开发的一个分布式、多分区、多副本且基于zookeeper协调的分布式消息系统,现已捐献给Apache基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark、Flink等都支持与Kafka集成。
4、RocketMQ是阿里开源的消息中间件,目前已经捐献个Apache基金会,它是由Java语言开发的,具备高吞吐量、高可用性、适合大规模分布式系统应用等特点,经历过双11的洗礼,实力不容小觑。
目前市面上的消息中间件还有很多,比如腾讯系的PhxQueue、CMQ、CKafka,又比如基于Go语言的NSQ,有时人们也把类似Redis的产品也看做消息中间件的一种,当然它们都很优秀。
二:消息选型要点概述
1、功能维度
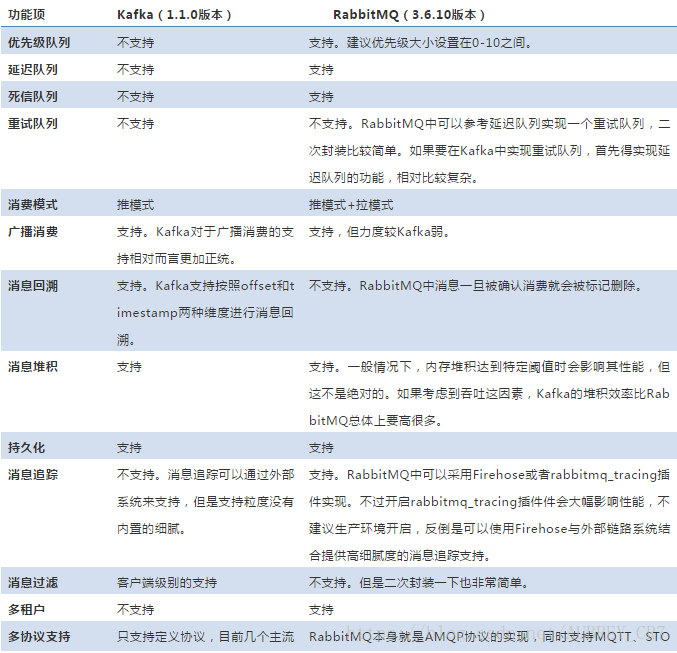
(1)、优先级队列
优先级队列不同于先进先出队列,优先级高的消息具备优先被消费的特权,这样可以为下游提供不同消息级别的保证。不过这个优先级也是需要有一个前提的:如果消费者的消费速度大于生产者的速度,并且消息中间件服务器(一般简单的称之为Broker)中没有消息堆积,那么对于发送的消息设置优先级也就没有什么实质性的意义了,因为生产者刚发送完一条消息就被消费者消费了,那么就相当于Broker中至多只有一条消息,对于单条消息来说优先级是没有什么意义的。
(2)、延迟队列
当你在网上购物的时候是否会遇到这样的提示:“三十分钟之内未付款,订单自动取消”?这个是延迟队列的一种典型应用场景。延迟队列存储的是对应的延迟消息,所谓“延迟消息”是指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。延迟队列一般分为两种:基于消息的延迟和基于队列的延迟。基于消息的延迟是指为每条消息设置不同的延迟时间,那么每当队列中有新消息进入的时候就会重新根据延迟时间排序,当然这也会对性能造成极大的影响。实际应用中大多采用基于队列的延迟,设置不同延迟级别的队列,比如5s、10s、30s、1min、5mins、10mins等,每个队列中消息的延迟时间都是相同的,这样免去了延迟排序所要承受的性能之苦,通过一定的扫描策略(比如定时)即可投递超时的消息。
(3)、重试队列
重试队列其实可以看成是一种回退队列,具体指消费端消费消息失败时,为防止消息无故丢失而重新将消息回滚到Broker中。与回退队列不同的是重试队列一般分成多个重试等级,每个重试等级一般也会设置重新投递延时,重试次数越多投递延时就越大。举个例子:消息第一次消费失败入重试队列Q1,Q1的重新投递延迟为5s,在5s过后重新投递该消息;如果消息再次消费失败则入重试队列Q2,Q2的重新投递延迟为10s,在10s过后再次投递该消息。以此类推,重试越多次重新投递的时间就越久。
(4)、消费模式
消费模式分为推(push)模式和拉(pull)模式。推模式是指由Broker主动推送消息至消费端,实时性较好,不过需要一定的流制机制来确保服务端推送过来的消息不会压垮消费端。而拉模式是指消费端主动向Broker端请求拉取(一般是定时或者定量)消息,实时性较推模式差,但是可以根据自身的处理能力而控制拉取的消息量。
(5)、广播消费
消息一般有两种传递模式:点对点(P2P,Point-to-Point)模式和发布/订阅(Pub/Sub)模式。对于点对点的模式而言,消息被消费以后,队列中不会再存储,所以消息消费者不可能消费到已经被消费的消息。虽然队列可以支持多个消费者,但是一条消息只会被一个消费者消费。发布订阅模式定义了如何向一个内容节点发布和订阅消息,这个内容节点称为主题(topic),主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者则从主题中订阅消息。主题使得消息的订阅者与消息的发布者互相保持独立,不需要进行接触即可保证消息的传递,发布/订阅模式在消息的一对多广播时采用。RabbitMQ是一种典型的点对点模式,而Kafka是一种典型的发布订阅模式。但是RabbitMQ中可以通过设置交换器类型来实现发布订阅模式而达到广播消费的效果,Kafka中也能以点对点的形式消费。
(6)、消息回溯
一般消息在消费完成之后就被处理了,之后再也不能消费到该条消息。消息回溯正好相反,是指消息在消费完成之后,还能消费到之前被消费掉的消息。对于消息而言,经常面临的问题是“消息丢失”,至于是真正由于消息中间件的缺陷丢失还是由于使用方的误用而丢失一般很难追查,如果消息中间件本身具备消息回溯功能的话,可以通过回溯消费复现“丢失的”消息进而查出问题的源头之所在。
(7)、消息堆积+持久化
流量削峰是消息中间件的一个非常重要的功能,而这个功能其实得益于其消息堆积能力。从某种意义上来讲,如果一个消息中间件不具备消息堆积的能力,那么就不能把它看做是一个合格的消息中间件。消息堆积分内存式堆积和磁盘式堆积。RabbitMQ是典型的内存式堆积,但这并非绝对,在某些条件触发后会有换页动作来将内存中的消息换页到磁盘(换页动作会影响吞吐),或者直接使用惰性队列来将消息直接持久化至磁盘中。Kafka是一种典型的磁盘式堆积,所有的消息都存储在磁盘中。一般来说,磁盘的容量会比内存的容量要大得多,对于磁盘式的堆积其堆积能力就是整个磁盘的大小。从另外一个角度讲,消息堆积也为消息中间件提供了冗余存储的功能。
(8)、消息过滤
消息过滤是指按照既定的过滤规则为下游用户提供指定类别的消息。就以kafka而言,完全可以将不同类别的消息发送至不同的topic中,由此可以实现某种意义的消息过滤,或者Kafka还可以根据分区对同一个topic中的消息进行分类。不过更加严格意义上的消息过滤应该是对既定的消息采取一定的方式按照一定的过滤规则进行过滤。同样以Kafka为例,可以通过客户端提供的ConsumerInterceptor接口或者Kafka Stream的filter功能进行消息过滤。
(9)、多协议支持
消息是信息的载体,为了让生产者和消费者都能理解所承载的信息(生产者需要知道如何构造消息,消费者需要知道如何解析消息),它们就需要按照一种统一的格式描述消息,这种统一的格式称之为消息协议。有效的消息一定具有某种格式,而没有格式的消息是没有意义的。一般消息层面的协议有AMQP、MQTT、STOMP、XMPP等,支持的协议越多其应用范围就会越广,通用性越强。
(10)、跨语言支持
对很多公司而言,其技术栈体系中会有多种编程语言,如C/C++、JAVA、Go、PHP等,消息中间件本身具备应用解耦的特性,如果能够进一步的支持多客户端语言,那么就可以将此特性的效能扩大。跨语言的支持力度也可以从侧面反映出一个消息中间件的流行程度。
(11)、流量控制
流量控制针对的是发送方和接收方速度不匹配的问题,提供一种速度匹配服务抑制发送速率使接收方应用程序的读取速率与之相适应。
(12)、安全机制
在Kafka 0.9版本之后就开始增加了身份认证和权限控制两种安全机制。身份认证是指客户端与服务端连接进行身份认证,包括客户端与Broker之间、Broker与Broker之间、Broker与ZooKeeper之间的连接认证,目前支持SSL、SASL等认证机制。权限控制是指对客户端的读写操作进行权限控制,包括对消息或Kafka集群操作权限控制。权限控制是可插拔的,并支持与外部的授权服务进行集成。对于RabbitMQ而言,其同样提供身份认证(TLS/SSL、SASL)和权限控制(读写操作)的安全机制。
下表是对Kafka与RabbitMQ功能的总结性对比及补充说明。

2、性能维度
消息中间件的性能一般是指其吞吐量,虽然从功能维度上来说,RabbitMQ的优势要大于Kafka,但是Kafka的吞吐量要比RabbitMQ高出1至2个数量级,一般RabbitMQ的单机QPS在万级别之内,而Kafka的单机QPS可以维持在十万级别,甚至可以达到百万级。
时延作为性能维度的一个重要指标,却往往在消息中间件领域所被忽视,因为一般使用消息中间件的场景对时效性的要求并不是很高,如果要求时效性完全可以采用RPC的方式实现。消息中间件具备消息堆积的能力,消息堆积越大也就意味着端到端的时延也就越长,与此同时延时队列也是某些消息中间件的一大特色。那么为什么还要关注消息中间件的时延问题呢?消息中间件能够解耦系统,对于一个时延较低的消息中间件而言,它可以让上游生产者发送消息之后可以迅速的返回,也可以让消费者更加快速的获取到消息,在没有堆积的情况下可以让整体上下游的应用之间的级联动作更加高效,虽然不建议在时效性很高的场景下使用消息中间件,但是如果所使用的消息中间件的时延方面比较优秀,那么对于整体系统的性能将会是一个不小的提升。
3、可靠性+可用性
消息丢失是使用消息中间件时所不得不面对的一个同点,其背后消息可靠性也是衡量消息中间件好坏的一个关键因素。尤其是在金融支付领域,消息可靠性尤为重要。然而说到可靠性必然要说到可用性,注意这两者之间的区别,消息中间件的可靠性是指对消息不丢失的保障程度;而消息中间件的可用性是指无故障运行的时间百分比,通常用几个9来衡量。
4、社区力度+生态发展
对于目前流行的编程语言而言,如Java、Python,如果你在使用过程中遇到了一些异常,基本上可以通过搜索引擎的帮助来得到解决,因为一个产品用的人越多,踩过的坑也就越多,对应的解决方案也就越多。对于消息中间件也同样适用,如果你选择了一种“生僻”的消息中间件,可能在某些方面运用的得心应手,但是版本更新缓慢、遇到棘手问题也难以得到社区的支持而越陷越深;相反如果你选择了一种“流行”的消息中间件,其更新力度大,不仅可以迅速的弥补之前的不足,而且也能顺应技术的快速发展来变更一些新的功能,这样可以让你以“站在巨人的肩膀上”。