一、目前市面上比较流行的注册中心有Zoopeeker、consul、Eureka、etcd。
1. Zoopeeker:Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination. Zoopeeper致力于开发和维护一个开源服务器,提供实现高效且可靠的分布式协调服务。是Hadoop和Hbase的重要组件。
需要了解更多可以参看wiki: https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
2. Consul:Consul is a tool for service discovery and configuration. Consul is distributed, highly available, and extremely scalable. Consul是用于服务发现和配置的工具,它是分布式的、高可用的、易扩展的。代码托管:https://github.com/hashicorp/consul
3. Eureka:Eureka is a REST based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers. Eureka是一种基于REST的服务,主要使用在AWS云(亚马逊云)上定位服务,以实现中间层服务器的负载均衡和故障转移。
Wiki: https://github.com/Netflix/eureka/wiki/Eureka-at-a-glance
4. Etcd:etcd is a distributed reliable key-value store for the most critical data of a distributed system. etcd为分布式系统最关键数据提供可靠的分布式键值存储。(使用在CoreOS系统和k8s容器上)
更多了解:https://github.com/coreos/etcd
这几个服务发现中心对比:
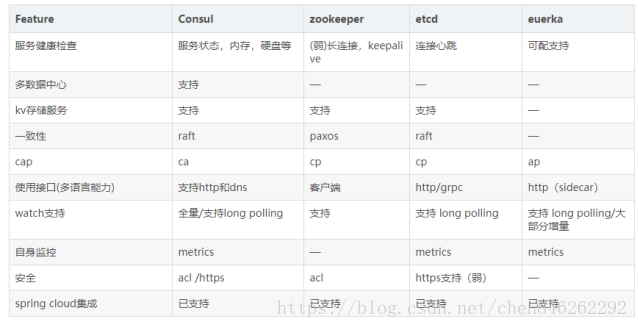
分布式领域CAP理论:
Consistency(一致性), 数据一致更新,所有数据变动都是同步的
Availability(可用性)
Partition tolerance(分区容错性) 可靠性
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
这里也有一篇比较好的外国对比的译文:
Kafka的运行需要注册到zookeeper上,这里我们先下载并安装zk
http://mirror.bit.edu.cn/apache/zookeeper/
下载稳定版本
下载完成后按照知道文档进行安装(先确保java环境可用)
http://zookeeper.apache.org/doc/current/zookeeperStarted.html
1. 解压 tar -zxvf zookeeper-3.4.12.tar.gz
2. 移动到usr/local 目录下 mv zookeeper-3.4.12 /usr/local
3. 创建zoo.cfg配置文件 cp -b zoo_sample.cfg zoo.cfg
4. 运行zk服务 bin/zkServer.sh start
5. 检查是否启动成功 ps -ef|grep zookeeper

二、接下来我们进入主题
使用过分布式中间件的人都知道,程序员使用起来并不复杂,常用的客户端 API 就那么几个,比我们日常编写程序时用到的 API 要少得多。但是分布式中间件在中小研发团队中使用得并不多,为什么会这样呢?原因是中间件的职责相对单一,客户端的使用虽然简单,但整个环境搭起来却不容易。
我们为什么需要消息中间件(消息代理的作用)?
1.业务系统往往要求响应能力特别强。
2.解耦(如果一个系统挂了,则不会影响另外个系统的继续运行)。
3.业务系统往往要求消息高效可靠,以及有对复杂功能如Ack的要求。
4.增强业务系统的异步处理能力(并行执行),减少甚至几乎不可能出现并发现象
打个比方:使用消息队列,就好比为了防汛而建一个大水库,有大量数据的堆积能力,然后可靠地进行异步输出。例如(现在的数据库同步)

传统做法存在的缺点:
1.一旦业务处理时间超过了定时器时间间隔,就会导致漏单。
2.如果采用新开线程的方式获取数据,那么由于大量新开线程处理,会容易造成服务器宕机。
3.数据库压力大,易并发。
MQ运用在哪些场景:
异步跨进程消息通信(解耦:注册邮件和注册短信发送)、秒杀和团抢(高吞吐量)、分布式日志处理(并行处理日志记录)、点对点通信(聊天室)...
我们常用的消息中间件有哪些?
比如:ActiveMQ、RabbitMQ 、RocketMQ、kafka 等等
这些消息中间有什么大的区别呢?说到区别,我们先了解一下JMS(java消息系统)接口规范和AMQP(高级消息队列协议)协议。JMS规范目前支持两种消息模型:点对点(point to point, queue)和发布/订阅(publish/subscribe,topic)。AMQP 更确切的说是一种链接协议,它不从API层进行限定,而是直接定义网络交换的数据格式。目前AMQP逐渐成为消息队列的一个标准协议,当前比较流行的Rabbitmq使用了AMQP实现。那么kafka使用的是自身定制基于TCP的二进制协议(NIO)。
1. P2P模型:
P2P模式包含三个角色:消息队列(Queue),发送者(Sender),接收者(Receiver)。每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到他们被消费或超时(消息不会重复消费)。
P2P的特点:
1.Queue支持多个消费者,但对一个消息而言只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中,也称为单播)
2.发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行,它不会影响到消息被发送到队列
3.接收者在成功接收消息之后需向队列应答成功
Pub/sub模型:
包含三个角色主题(Topic),发布者(Publisher),订阅者(Subscriber) 。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
Pub/Sub的特点:
1.每个消息可以有多个消费者
2.发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
3.为了消费消息,订阅者必须保持运行的状态。
4.会存在多次消费的可能,所以有必要的时候需要做幂等
以下是阿里巴巴消息中间团队对常见的消息中间件性能对比:
接下来说说kafka消息代理,其他的消息代理可自行了解下
Kafka是由LinkedIn(领英)开发的一个开源分布式基于发布/订阅的消息系统,生产者使用Scala 消费者使用Java语言编写。
Kafka主要是基于pull模式进行处理消息、RocketMQ、RabbitMQ push 和 pull 都支持。
Push方式:优点是可以尽可能快地将消息发送给消费者,缺点是如果消费者处理能力跟不上,消费者的缓冲区可能会溢出。
Pull方式:优点是消费端可以按处理能力进行拉去,缺点是会增加消息延迟。
Kafka的核心组件:
1. Broker(代理、节点):Kafka集群包含一个或多个服务器,这种服务器被称为broker。
2. Topic(主题):每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,逻辑上可称之为队列(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
3. Partition(分区):Partition是物理上的概念,每个Topic包含一个或多个Partition,每个Partition对应一个逻辑log,由多个segment组成。
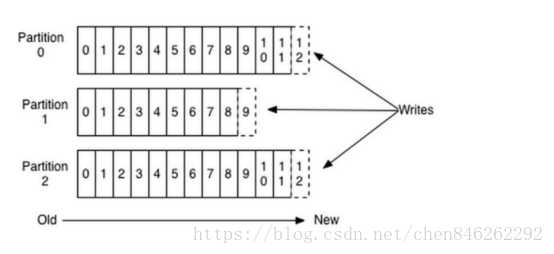
发到某个topic的消息会被均匀的分布到多个Partition上(随机或根据用户指定的回调函数进行分布),broker收到发布消息往对应Partition的最后一个segment上添加该消息,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。
4. Producer:负责发布消息到Kafka broker
5. Consumer:消息消费者,向Kafka broker读取消息的客户端。

6.Consumer Group(消费组):每个Consumer属于一个特定的Consumer Group,它会维护一个索引,用于标识一个消费集群的消费位置。为了对减小一个consumer group中不同consumer之间的分布式协调开销,指定partition为最小的并行消费单位,即一个group内的consumer只能消费不同的partition。如果要实现消息单播,只要将消费者归属到同一个消费组即可,也就是说不同的消费组可以实现消息的多播。消费组还有一个作用是提供容错。
概念上的东西如果需要了解更多,可以查看:http://kafka.apache.org/intro
接下来进行kafka的实战
1.开始下载安装kafka
下载路径:
http://mirror.bit.edu.cn/apache/kafka/
按照指导文档进行安装
http://kafka.apache.org/quickstart
1. 解压到 /usr/local 目录下 tar -xzf kafka_2.11-1.1.0.tgz
2. mv kafka_2.10-0.10.2.1 /usr/local/
3. 启动kafka bin/kafka-server-start.sh config/server.properties & (要先启动zk)
4. 检查kafka服务是否启动成功 netstat -anp|grep 9092

现在建立一个spring boot 项目链接kafka消息中间件
参考:spring 官网
https://spring.io/projects/spring-kafka#learn
https://docs.spring.io/spring-boot/docs/1.5.14.RELEASE/reference/htmlsingle/#boot-features-kafka