MapReduce

MapReduce是什么?
MapReduce源自于Google发表于2004年12月的MapReduce论文,是面向大数据并行处理的计算模型、框架和平台,而Hadoop MapReduce是Google MapReduce克隆版。
如果没有MapReduce!
- 那么在分布式计算上面将很难办,不好编程。
- 在早期无法处理大数据的离线计算。
- 编程中不易扩展性
- 分布式计算任务一旦挂了,没有容错机制进行处理
说明:MapReduce不擅长的方面(慢!)
- 实时计算:像MySQL一样,在毫秒级或者秒级内返回结果。
- 流式计算:MapReduce的输入数据集是静态的,不能动态变化。
- DAG计算:多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出
现在MapReduce逐渐被Spark,Flink等框架取代。但是思想很重要,值得学习。
1 MapReduce编程模型
- 场景:有大量文件,里面存储了单词,且一个单词占一行
- 任务:如何统计每个单词出现的次数?
- 类似应用场景:
- 搜索引擎中,统计最流行的K个搜索词;
- 统计搜索词频率,帮助优化搜索词提示
- 三种问题
- Case 1:整个文件可以加载到内存中;sort datafile | uniq -c;
- Case 2:文件太大不能加载到内存中,但每一行<word, count>可以存放到内存中;
- Case 3:文件太大无法加载到内存中,且<word, count>也不用保存在内存中;
- 将三种问题范化为:有一批文件(规模为TB级或者 PB级),如何统计这些文件中所有单词出现的次数;
- 方案:首先,分别统计每个文件中单词出现次数,然后累加不同文件中同一个单词出现次数;
- 典型的MapReduce过程。
1.1 WordCount案例
1.1.1 WordCount流程图
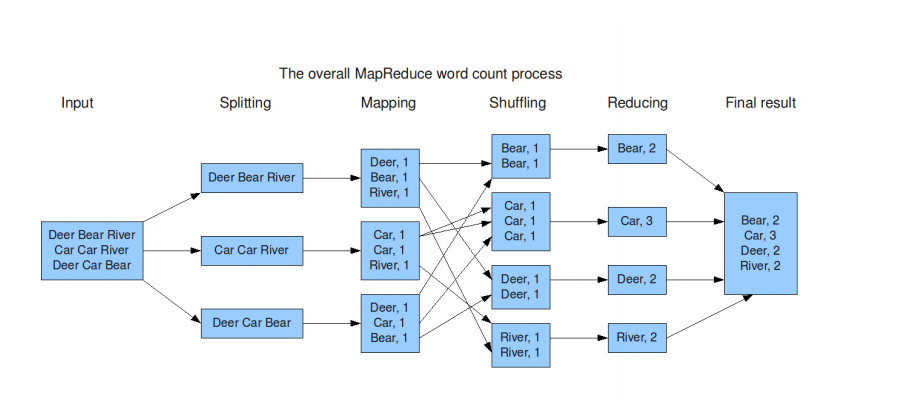
input阶段,我们取出文件中的一些数据
splitting阶段,我们将取出的单词进行分片
Mapping阶段,将每个出现的单词进行1次统计,转换数据类型为(单词,1)
Shuffling阶段,进行hash分片,放入对应的桶,俗称洗牌,将同样的单词放入同一个桶。
Reducing阶段,进行数据整合,求出每个词的出现的次数
Final result阶段,最后获取到的结果
1.1.2 WordCount代码及本地运行
1 新建word.txt文件
Deer Bear River Car Car River Deer Car Bear2 导入maven依赖
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.0.0-cdh6.2.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0-cdh6.2.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.0.0-cdh6.2.0</version> </dependency>3 map类
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 四个泛型意思: * Mapper<LongWritable, Text, Text, IntWritable> * KEYIN -> LongWritable:偏移量(存储该行在整个文件中的起始字节偏移量) * VALUEIN -> Text:进入数据类型 * KEYOUT -> Text:输出数据键类型 * VALUEOUT -> IntWritable:输出数据值类型 */ public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); private IntWritable one = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到一行数据,以空格切分 String[] words = value.toString().split(" "); //遍历单词数据,将数据变成(单词,1)的形式放入上下文中(框架) for (String word : words) { this.word.set(word); context.write(this.word, one); } } }4 reducer类
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> 四个泛型意思: * Reducer<Text, IntWritable, Text, IntWritable> * KEYIN -> Text:输入数据键类型 * VALUEIN -> IntWritable:输入数据值类型 * KEYOUT -> Text:输出数据键类型 * VALUEOUT -> IntWritable:输出数据值类型 */ public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable total = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //累加相同单词的数量 int sum = 0; for (IntWritable value : values) { sum += value.get(); } //包装结果为(单词,总数)输出 total.set(sum); context.write(key, total); } }5 执行任务Driver类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WcDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取Job实例 Job job = Job.getInstance(new Configuration()); //设置工作类 job.setJarByClass(WcDriver.class); //设置Mapper和Reducer类 job.setMapperClass(WcMapper.class); job.setReducerClass(WcReducer.class); //设置Mapper和Reducer输出的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置输入输出数据 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //提交job boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }6 设置文件输入输出参数,执行程序,得到结果

#### 1.1.3 集群运行
- 打包上面写好的项目,上传集群,执行提交命令。



2 Hadoop序列化
为什么hadoop要自己实现基本的数据类型而不直接使用Java的类?如:IntWritable,LongWritable,Text。
因为Java的序列化是一个重量级框架(Serializable),一个对象被序列化后,会附带很多额外的信息(校验信息,继承体系,Header等),在网络中传输高效性有影响,所以hadoop自己实现了序列化机制(Writable)。
注:网络传输中的信息都需要序列化,因为hadoop自己实现了序列化机制(Writable),所以我们才可以进行简单的分布式计算代码开发。
2.1 手机流量统计(序列化案例)
1 新建flow.txt文件(行号 手机号 IP 网址 上行流量 下行流量 状态码)
1 13408542222 192.168.10.1 www.baidu.com 1000 2000 200 2 17358643333 192.168.10.1 www.baidu.com 2000 4000 200 3 13408542222 192.168.10.1 www.baidu.com 1000 2000 200 4 17358643333 192.168.10.1 www.baidu.com 2000 4000 200 5 13408542222 192.168.10.1 www.baidu.com 1000 2000 200 6 17358643333 192.168.10.1 www.baidu.com 2000 4000 2002 导入maven依赖
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.0.0-cdh6.2.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0-cdh6.2.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.0.0-cdh6.2.0</version> </dependency>3 实体类对象
import lombok.Getter; import lombok.NoArgsConstructor; import lombok.Setter; import lombok.ToString; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; @Getter @Setter @NoArgsConstructor @ToString //注意toString方法和最后打印结果效果相关 public class Flow implements Writable { private long upFlow; private long downFlow; private long totalFlow; public void setFlow(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.totalFlow = upFlow + downFlow; } //序列化方法 @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(upFlow); dataOutput.writeLong(downFlow); dataOutput.writeLong(totalFlow); } //反序列化方法 @Override public void readFields(DataInput dataInput) throws IOException { upFlow = dataInput.readLong(); downFlow = dataInput.readLong(); totalFlow = dataInput.readLong(); } }4 map类
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class FlowMapper extends Mapper<LongWritable, Text, Text, Flow> { private Text phone = new Text(); private Flow flow = new Flow(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] data = value.toString().split(" "); phone.set(data[1]); long upFlow = Long.parseLong(data[4]); long downFlow = Long.parseLong(data[5]); flow.setFlow(upFlow, downFlow); context.write(phone, flow); } }5 reducer类
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FlowReducer extends Reducer<Text, Flow, Text, Flow> { private Flow flow = new Flow(); @Override protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException { long sumUpFlow = 0; long sumDownFlow = 0; for (Flow value : values) { sumUpFlow += value.getUpFlow(); sumDownFlow += value.getDownFlow(); } flow.setFlow(sumUpFlow, sumDownFlow); context.write(key, flow); } }6 执行任务Driver类
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class FlowDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取Job实例 Job job = Job.getInstance(new Configuration()); //设置工作类 job.setJarByClass(FlowDriver.class); //设置Mapper和Reducer类 job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); //设置Mapper和Reducer输入输出的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flow.class); //设置输入输出数据 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //提交job boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }7 设置文件输入输出参数,执行程序,得到结果

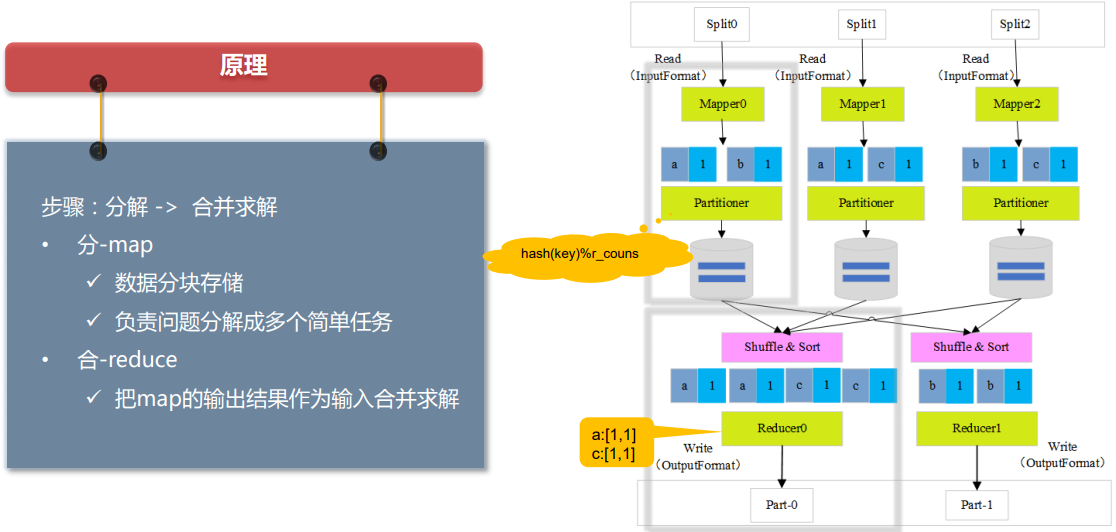
3 MapReduce原理
3.1MapReduce的集群管理架构
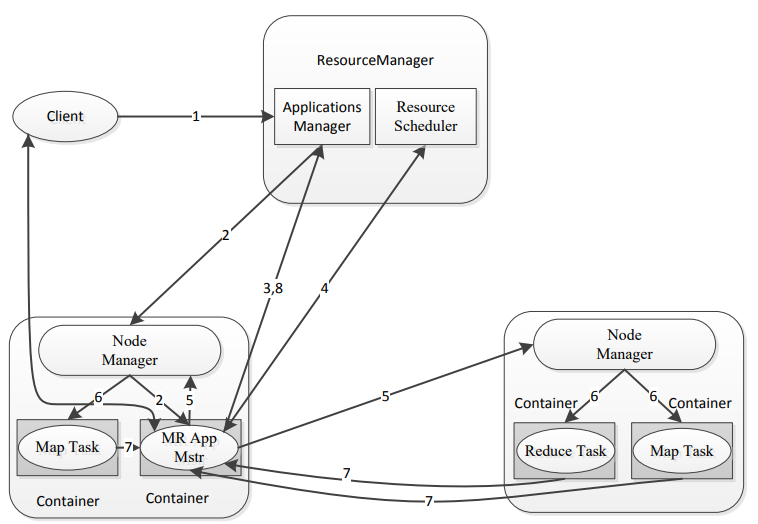
1.客户端发送MR任务到RM上
2.RM分配资源,找到对应的NM,分配Container容器,启动对应的Application Master
3.Application Master向Applications Manager注册
4.Application Master向Resource Scheduler申请资源
5.找到对应的NM
6.分配Container容器,启动对应的的Map Task或者是Reduce Task任务
7.Map Task和Reduce Task对Application Master汇报心跳,任务进度
8.Application Master向Applications Manager汇报整体任务进度,如果执行完了Applications Manager会将Application Master移除注意:原则上MapReduce分为两个阶段:Map Task和Reduce Task,但是由于Shuffling阶段很重要,人为划分了Shuffling阶段,这个阶段发生在Map Task和Reduce Task之间,可以理解为由Map Task后半段和Reduce Task前半段组成。
3.2 MapReduce的数据流
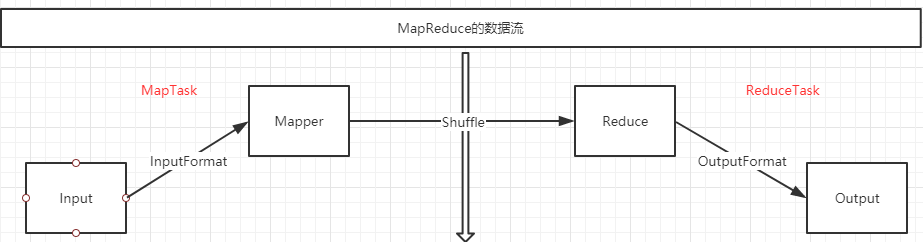
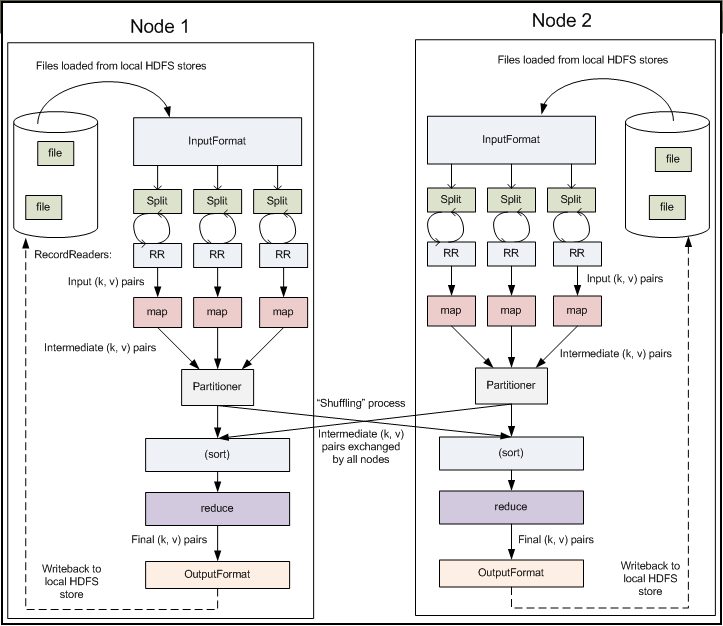
3.3 MapTask
3.3.1 并行度决定机制
1G的数据,分成8份并行计算,那么每一份需要计算的数据为128M,感觉还不错。
1M的数据,分成8份并行计算,那么每一份需要计算的数据为128B,感觉资源浪费严重。
那么就需要有一个东西来决定怎么切分,它就是InputFormat,而切分大小一般由HDFS块大小决定。
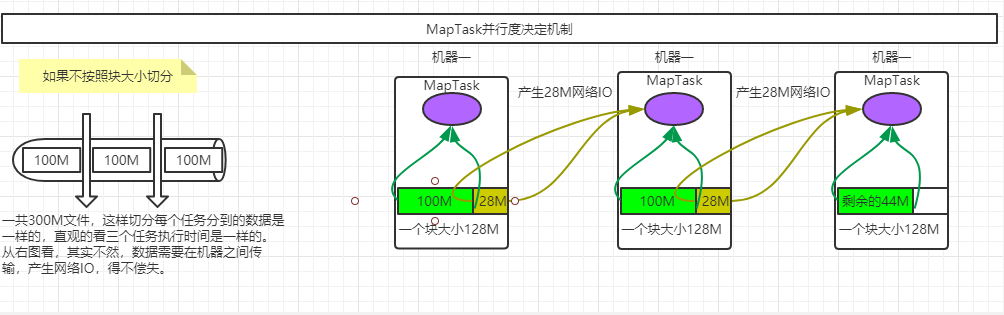
- 一个Job的Map阶段并行度由客户端在提交Job时的切片数决定。
- 每一个Split切片分配一个MapTask并行处理实例。
- 默认情况下,切片大小=BlockSize(128M)。
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片。
针对第四点说明:比如有3个文件,一个300M,第二个50M,第三个50M,那么一共就是切了5个MapTask出来。
针对每一个文件,第一个300M切了3个,第二个50M切了一个,第三个50M切了一个,共5个。
而如果只有一个文件为128M+1KB,那么就只会切分一个,因为切片判断规则为->如果文件小于切片大小1.1倍,就和上一个切片将就放在一起了,这样可以防止过小的切片在执行任务的时候,调度资源的时间超过执行时间的情况。
3.3.2 InputFormat
TextInputFormat:
- TextInputFormat是默认的FileInputFormat实现类,按行读取每条记录。
键:存储该行在整个文件中的起始字节偏移量,LongWritable类型
值:为这行内容,不包括任何行止符(如回车,换行)
示例,一个分片中包含了如下记录:
#源文件 si chuan cheng du jiang su wu xi he bei bei jing#被TextInputFormat加载后会变成 (0,si chuan cheng du) (18,jiang su wu xi) (33,he bei bei jing)
KeyValueInputFormat:
- KeyValueInputFormat每一行均为一条记录,被分隔符号分割为key,value。
可以通过在驱动类中设置conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,"\t");来设置分隔符。默认\t
示例,一个分片中包含了如下记录:
#源文件 line1 si chuan cheng du line2 jiang su wu xi line3 he bei bei jing#被KeyValueInputFormat加载后会变成 (line1,si chuan cheng du) (line2,jiang su wu xi) (line3,he bei bei jing)
NlineInputFormat:
- NlineInputFormat代表每个map进程处理的inputSplit不在按Block块去划分,而是按指定的行数N来划分。
- 输入文件的总行数/N=切片数,如果不整除,切片数=商+1
键:存储该行在整个文件中的起始字节偏移量,LongWritable类型
值:为这行内容,不包括任何行止符(如回车,换行)
示例,一个分片中包含了如下记录:
#源文件 si chuan cheng du jiang su wu xi he bei bei jing hu bei wu han如果N是2,则每个输入分片包含2行,开启2个Map Task
#第一个map收到 (0,si chuan cheng du) (18,jiang su wu xi) #第二个map收到 (33,he bei bei jing) (49,hu bei wu han)
CombineTextInputFormat:
根据设置的阈值来决定切片数。
假设setMaxInputSplitSize值为5M,如下4个文件
a.txt 2.1M b.txt 5.8M c.txt 3.6M d.txt 7.8M #虚拟储存过程(因为如上4小个文件在hdfs上占用了4个块,所以要有一个虚拟划块的过程) 2.1M < 5M 划分一块,2.1M 5.8M > 5M 大于5M但是小于2*5M,划分2个同样大小的块,2.9M-2.9M 3.6M < 5M 划分一块,3.6M 12M > 5M 大于2*5M,先划分5M,剩下的 7M > 5M 但是 < 2*5M 划分2个同样大小的块,5M-3.5M-3.5M (得到结果) 2.1M 2.9M 2.9M 3.6M 4M 3.5M 3.5M #切片过程(补够5M划成一块) 第一块 2.1M + 2.9M = 5M 第二块 2.9M + 3.6M = 6.5M 第三块 4M + 3.5M = 7.5M 第四块 3.5M
SequenceFileInputFormat:
- SequenceFile其实就是上一个MR程序的输出
- 由于每一个MR都会落地磁盘,那么框架就提供了一种文件对接格式SequenceFile
- 使用SequenceFileInputFormat作为中间结果的链接
3.4 Shuffle
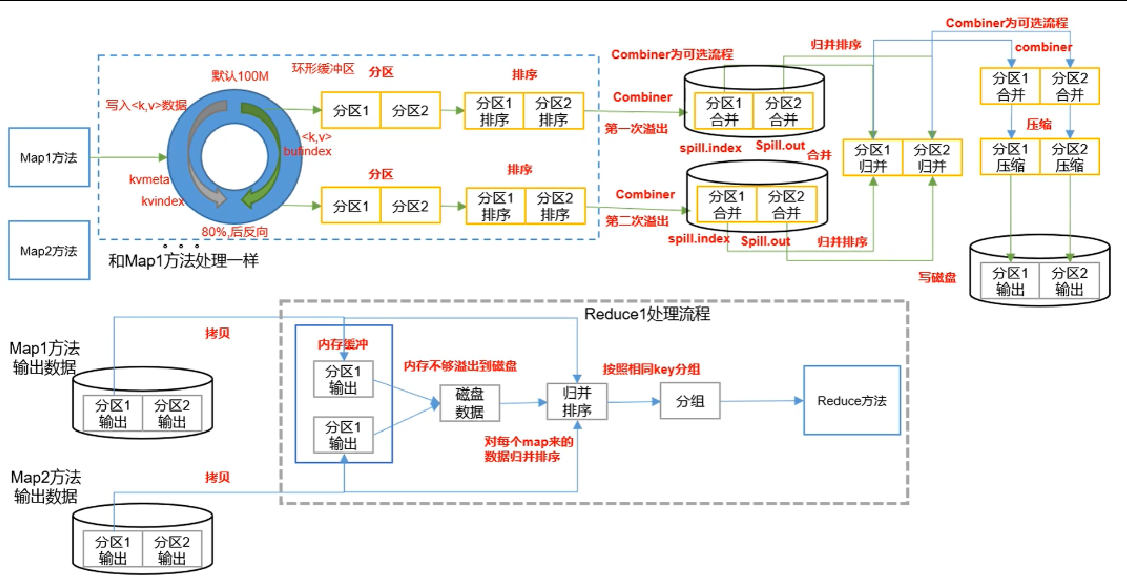
Partitioner分区
- Partitioner决定了Map Task输出的每条数据,交给哪个Reduce Task处理
- 默认实现:hash(key) mod ReduceTask数目
- 允许用户自定义
- 很多情况需自定义Partitioner
- 比如hash(hostname(URL)) mod ReduceTask数目,确保相同域名的网页交给同一个Reduce Task处理
3.5 Combiner合并
Combiner是MR程序中Mapper和Reducer之外的一种组件。
Combiner组件的父类是Reducer。
Combiner和Reducer的区别是运行位置不同。
- Combiner是在每一个MapTask所在的节点运行;
- Reducer是接受全局所有的Mapper的输出结果;
Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
Combiner能够应用的前提是不能影响最终的业务逻辑,且Combiner输出KV要和Reducer的输入KV对应。
Mapper Reducer 3 5 7 ->(3+5+7) / 3 = 5 (5+4) / 2 = 4.5 不等于 (3+5+7+2+6) / 5 = 4.6 2 6 ->(2+6) / 2 = 4