ProxyHandler代理器
在写爬虫时常常需要做代理IP以反爬虫
常用IP有:
西刺免费代理:xicidaili.com/nt/
快代理:http://kuaidaili.com/
代理云:http://dailiyun.com/
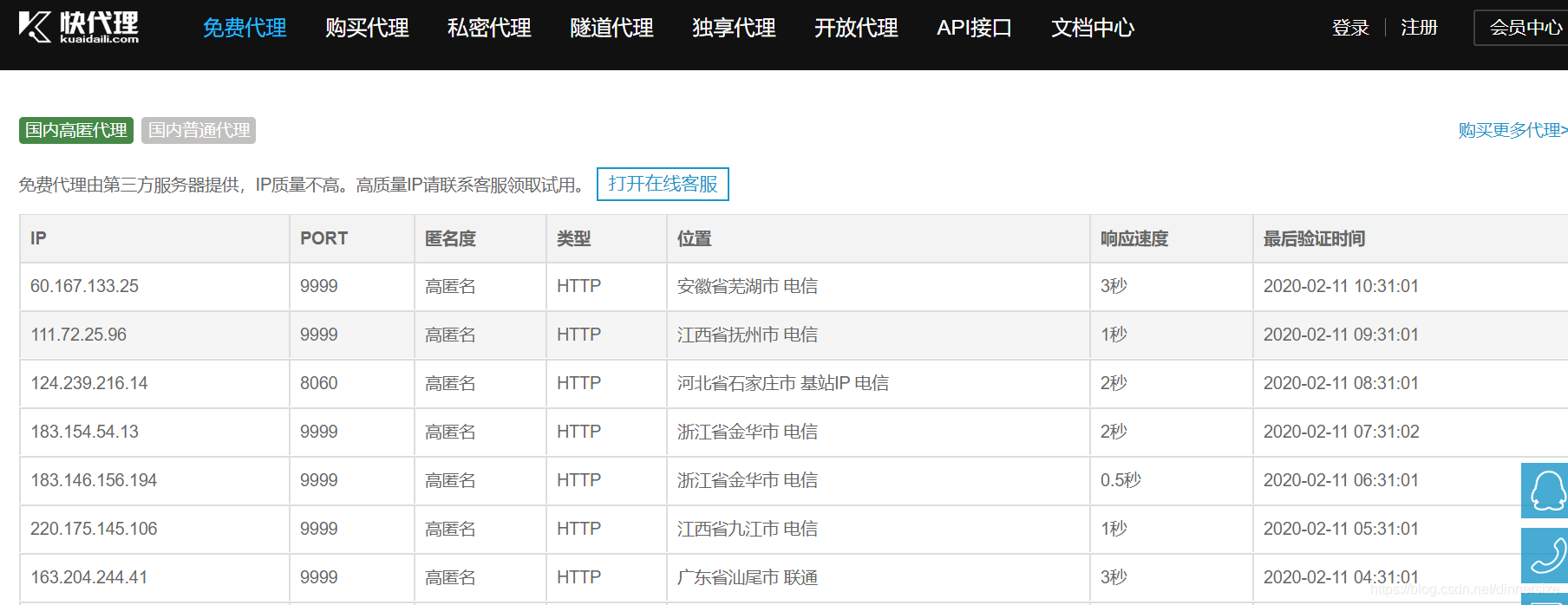 查看代理的IP:http://www.httpbin.org/ip
查看代理的IP:http://www.httpbin.org/ip
网站:http://www.httpbin.org/可查看http的一些参数。
#检查当前ip
from urllib import request,parse
url="http://httpbin.org/ip"
resp=request.urlopen(url)
print(resp.read())
代理的原理:先访问代理服务器,利用代理服务器去访问目标网站,然后再将访问结果返回给自己。
步骤:
1.使用ProxyHandler{“类型”:“ip:端口”}创建一个hander
2.利用创建的handler创建一个opener
3.利用opener发送请求 #其实,urlopen的底层就是一个如此的操作。
代码如下:
handler=request.ProxyHandler({"http":"112.95.205.49:8888"})
opener=request.build_opener(handler)
resp=opener.open(url)
print(resp.read())
结果:
b’{\n “origin”: “60.222.112.195”\n}\n’ #原IP
b’{\n “origin”: “60.222.112.195, 112.95.204.217”\n}\n’ #代理IP
cookie
在网站中,对服务器的使用往往需要认证,第一次访问服务器后,服务器返回一个cookie,以确保第二次访问无需认证。cookie一般不超过4kb。
代码如下,使用cookie可以实现登录账户。
方法一:在headers加入网页的cookie信息
aji_url="http://www.renren.com/973687886/profile"
headers=({"User-Agent":" Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36",
"Cookie": "anonymid=k6hu8cnocon7sq; 删除部分代码39c126ca7%7C1581428091545%7C1%7C1581428091771; jebecookies=6f157d36-8a56-4d80-b00e-5b56897c858e|||||; t=af9ce0986e484e427bb7eb4c8e9e3ed56; societyguester=af9ce0986e484e427bb7eb4c8e9e3ed56; xnsid=c90db889; loginfrom=null; wp_fold=0"
})
req=request.Request(url=aji_url,headers=headers)
resp=request.urlopen(req)
print(resp.read().decode("utf-8"))
方法二:
from http.cookiejar import CookieJar
headers = ({
“User-Agent”: " Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36"})
def get_opener():
# 创建一个cookiejar
cookiejar = CookieJar()
# 使用cookiejar创建一个HTTPCookieProcessor对象
handler = request.HTTPCookieProcessor(cookiejar)
# 使用handler创建一个opener
opener = request.build_opener(handler)
return opener
def login_renren(opener):
#登录人人网
data = ({"email": "13537703610",
"password": "510548134ys"})
login_url = "http://www.renren.com/SysHome.do"
req = request.Request(url=login_url, data=parse.urlencode(data).encode("utf-8"), headers=headers)
opener.open(req)
def visit_renrne(opener):
# 访问个人网页
aji_url = “http://www.renren.com/973687886/profile”
req = request.Request(aji_url, headers=headers) # 使用之前新建的opener,已经有登录信息
resp = opener.open(req)
with open(r"C:\python38\new project\mydi\ren.txt", “w”, encoding=“utf-8”)as fp:
fp.write(resp.read().decode(“utf-8”))
if name == ‘main’:
opener=get_opener()
login_renren(opener)
visit_renrne(opener)
cookie之保存 cookie保存到本地****可以方便再次查看
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar(“cookie.txt”)
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
resp=opener.open(“https://www.baidu.com/”)
cookiejar.save()
