这个学期开了人工智能与大数据,刚开始看见这门课,觉得和大数据有关,正好是自己兴趣所在,一定要好好学,但是,好像并不是我想象的那样,整个课程比较偏向机器学习,也就是说从基础的学习,按道理说机器学习应该要另外开一门课,而大数据开一门课,然后才可以将两者联系起来。当初数学本来就没有怎么学,现在机器学习全是数学,还有线性代数和概率论。唉,有时候不得不翻几篇博客看看一些机器学习的常用方法。但是额,一些博客真的可能也没有学好,十篇里面四篇是一样的,而且十篇里面同样的公式,写法标准各不一样,很容易造成歧义,也就是说其中一些来芋充数的博客可能也是没有学什么基础学科,写一些自己不了解的公式。所以我还是自己先把基础搞一下吧。然后这篇博客就以自己的理解和例子,以及以高中数学的写法来谈谈自己所理解的线性回归。
什么是线性?什么是回归?
线性的不需要多解释吧,想象成几个变量的关系是一维关系就行,就是说自变量是一维的,不是平方,立方的。
回归,回归是啥,回家?回寝室?
假设线性回归是个黑盒子,那按照程序员的思维来说,这个黑盒子就是个函数,然后呢,我们只要往这个函数传一些参数作为输入,就能得到一个结果作为输出。那回归是什么意思呢?其实说白了,就是这个黑盒子输出的结果是个连续的值。如果输出不是个连续值而是个离散值那就叫分类。那什么叫做连续值呢?非常简单,举个栗子:比如我告诉你我这里有间房子,这间房子有40平,在地铁口,然后你来猜一猜我的房子总共值多少钱?这就是连续值,因为房子可能值80万,也可能值80.2万,也可能值80.111万。再比如,我告诉你我有间房子,120平,在地铁口,总共值180万,然后你来猜猜我这间房子会有几个卧室?那这就是离散值了。因为卧室的个数只可能是1, 2, 3,4,充其量到5个封顶了,而且卧室个数也不可能是什么1.1, 2.9个。所以呢,对于ML萌新来说,你只要知道我要完成的任务是预测一个连续值的话,那这个任务就是回归。是离散值的话就是分类。(PS:目前只讨论监督学习)
线性回归
我们来看一看简单的例子
以我来举个例子吧。我有时候幻想女生喜欢我,可能要看长相,也可能看才华,也可能看人品。。。。。。具体我也不知道看啥,每个女生口味都不同。



把两者结合起来,似乎有点儿关系。
我们可以在每个图找出一条直线,求出这些点所形成的大概的轨迹直线。
我叫9999999个兄弟可能找出9999999条直线。但是哪一条才是最好的。其实吧,这个叫他们找直线的过程就是线性回归。
只不过创建这个东西的人,可能喜欢装逼(开玩笑,我不知道他是不是装逼);
损失函数
那么多个兄弟,我得有个标准评判哪个直线最好吧。就好比如现在如果很多女生喜欢你,你总得有个标准选个最好的吧,不然未必你全都要啊,啊呸,你这个渣男,不给我留一个。
那么这个找直线的标准就是损失函数。
在线性回归里。
我们可以定义欧式距离为损失函数。啥事欧式距离。就是实际的值与预期值的差就是欧氏距离。
逼格高的名字,不用管,知道是啥就行。
损失函数怎么来,实际值是啥,预期值又是啥?
忘了前面的公式了。
先看看长相与找女朋友的关系。加入是越帅越逗人喜欢,那么我们可以定义一个关系。
Y:代表是否有女生喜欢。
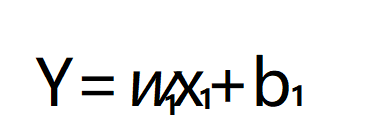
x1:是长相
b1:就理解成截距吧,你想最丑也还是有人喜欢吧。
w1:就是长相与喜欢的线性关系啦。
同样,我也可以定义才华与喜欢成都的关系。
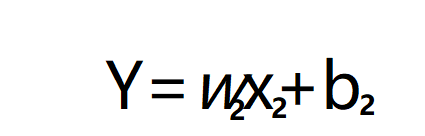
x1:是才华
b1:截距,没文化也有人喜欢坦诚的你。
w1:就是才华与喜欢的线性关系啦。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。此处省略其因素。。。。。。。。。。。。。。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
这样,我们就知道很多这种影响我受不受欢迎的原因。
w1,w2,w3,w4,w5....................
我们把他们搞成一个向量
这里是一个列向量。

同时我们会有各种样本。指定x向量,能够由原因1:x1和原因2:x2.。。。。。。组成

这样我们可以统一定原因加起来
Y=x1*w1+x2*w2+x3*w3..........+b(这个b可以看成b1+b2+b3.....)
用向量表示就是
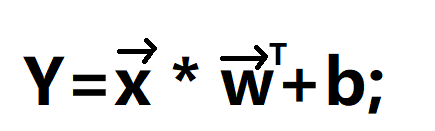
x=(x1,x2,x3,...);列向量,为了排版就写成行向量的样子,希望你想象程列向量。
w=(w1,w2,w3,w4...);这里是列向量,右上角一个T是行向量,就是转置变成行向量
这样是不是就定义了一个Y与各种x之间的关系了。
但是我们有太多太多的样本了,仅仅是一个这样的x和y根本求不出一些列的w和b。
这样我们就要重新定义几个变量。
将b吸收入w变成下面这个样子

重新定义x将所有样本定义过来。

这样我们将矩阵X和原因w相乘

就可以的的出另外一个向量

所以我们定义的预期值Y=x*w,x是指某一个样本,w是指预期的因素向量的系数
那么损失函数就定义成实际值与预期值的差了。
那么实际值y
某一个样本差:Y-y=x*w-y;
现在把所有样本算进来。
定义损失函数:
E=(Y1-y1)^2 + (Y2-y2)^2 + (Y3-y3)^2.........
=(w*x1-y1)^2 + (w*x2-y2)^2 + (w*y3-y3)^2 ........
这里的w是所有的因素向量系数。而x是某一个样本(里面包括了各种因素),y是实际值。
写成向量形式:




这样我们的损失函数就是这样

怎么得出w,b使损失函数最优
既然评判标准出来了,那么怎么知道哪个最好了。
我们这时候就可以根据求出来的w来使E最小值。
一般想法就是求导啦。
我们来求导试一试
求导:
那么现在自变量就变成了w,而X,y都是样本,都是已知的。


将E对w求导
矩阵的求导可以看这篇文章,记住一点就是,任何求导都是针对某一个量,矩阵只是多个量的表示而已。
https://www.cnblogs.com/pinard/p/10750718.html
求得导数为
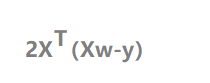
只要令导数为0,就可以得出极值点,也就是最小值。
那么就可以的出w
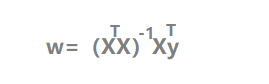
梯度下降
梯度下降就是我们平常下山来找到最小值。我们可以在山的任何一个地方,找到一个方向,沿着这个方向下降的最快。
而对于线性回归的损失函数,来求最小值,需要给一个初始值,然后逐步的迭代改变的值,是代价损失函数逐次变小,使每次都往梯度下降的方向改变:
而所谓的梯度,就是导数所形成的向量,这个向量有反向,就是沿着这个方向下降最快的。
我们需要对该向量求偏导。
即对w的每一个分量求偏导。使其逐渐趋于0
对于我们的损失函数。
我们要设置一个步长,或者说学习率,就是你下山一次跨多大。我们一次次迭代就可以慢慢逼近了。

这样我们对于每一个分量wj都能找出来。
直到损失函数不能在小。
