啥也先不说,先上图,上图最好理解
其实归并排序挺好理解的,也挺好实现的。其实也挺像我们的平常分工合作的。就像一样事情分成几份,由不同的人去做。再合并起来,采用了分治的思想。
对于一个数列,也同是如此。
我们只需要不断地对着中点切分就可以了。


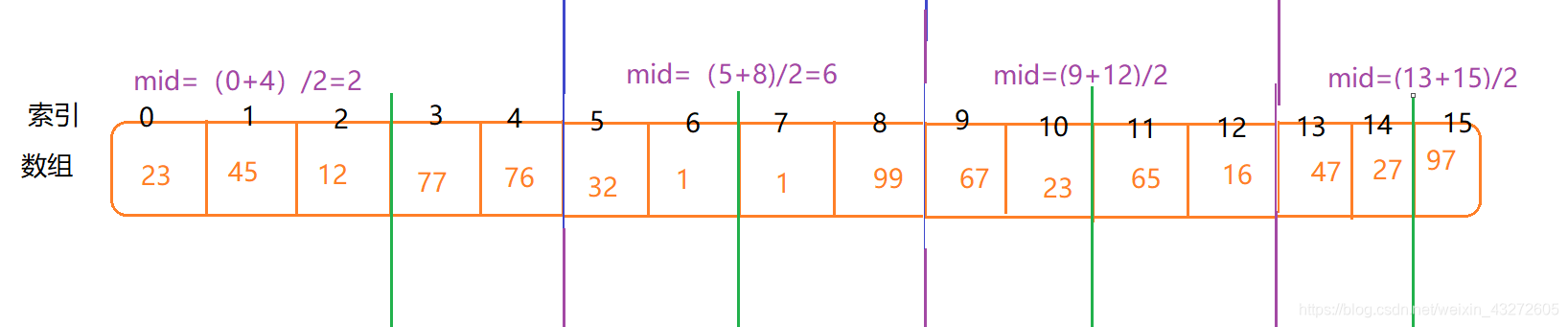
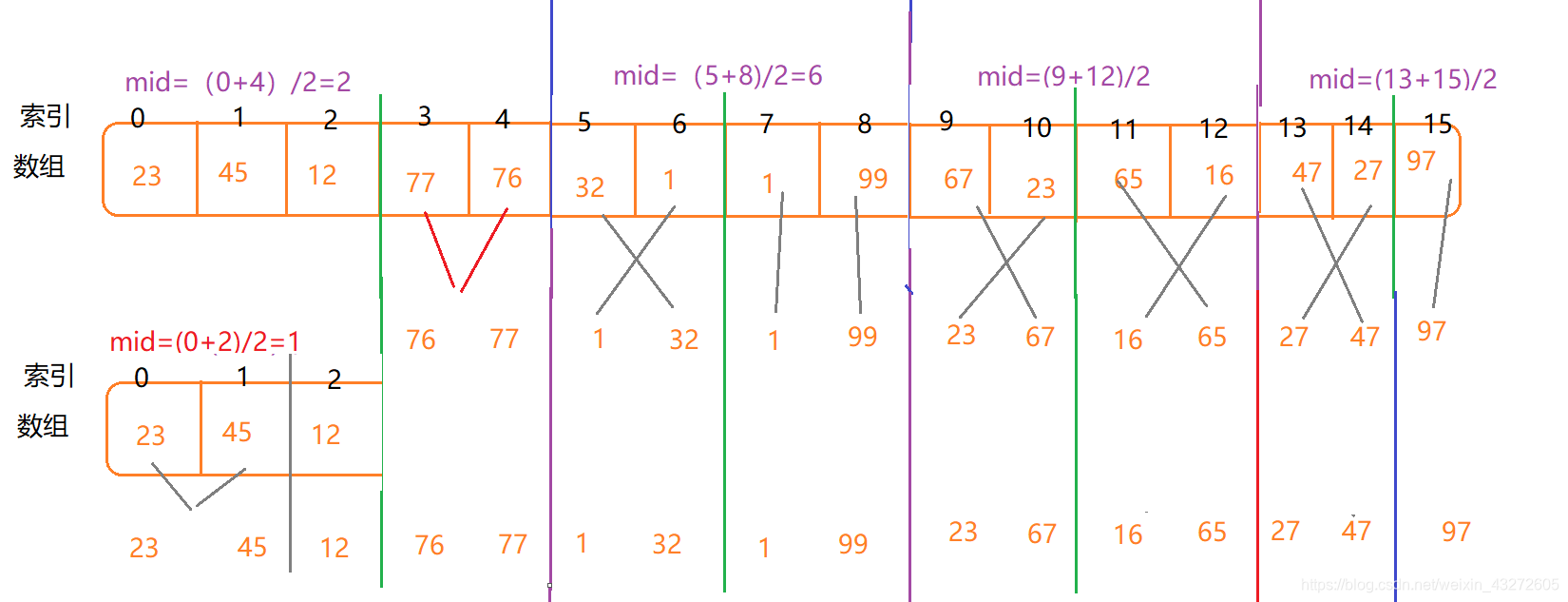
就这样类似的下去,针对每一个每次分割的取键合并
总共可以分两个过程,一个cut,一个merge
cut:对数列进行分割。
merge:这个过程就是两个区间进行合并,可以新建要给数组,然后从两个已排序的数组依次比较,这样就可以将小的或者大的先放进新的数组。
具体可以看看代码实现:
public int[] sort(int[] nums,int start,int end) {
//如果只有一个节点了(start=end)没必要排序,直接将这个元素作为新数组返回就是了
if(nums==null||start==end) return new int[] {nums[start]};
//cut过程
//计算中点
int mid = (start+end)/2;
//这个包含了cut过程,就是将左半边和右半边分开
int[] left = sort(nums, start, mid);//计算左半部分,从start------mid
int[] right = sort(nums, mid+1, end);//计算右半部分,从mid+1------end
//merge过程
//新建一个数组,用来保存合并后的元素
int[] retu = new int[left.length+right.length];
//i是left的索引,j是right的索引,p是新数组索引
int i=0,j=0,p=0;
while(i<left.length&&j<right.length) {
//哪个小就先放入新数组,这是从小到大排序
if(left[i]<right[j]) {
retu[p]=left[i];
i++;
}else {
retu[p]=right[j];
j++;
}
p++;
}
//如果某一个数组比另一个数组长,那么它的索引肯定没有到最后,那么从它的索引到以后的全都是顺序的,那么直接顺序添加进去就行
if(i<left.length) for(;i<left.length;i++,p++) retu[p]=left[i];
else if(j<right.length) for(;j<right.length;j++,p++) retu[p]=right[j];
return retu;
}当然这是一个数组的情况
前一天在leetcode发现了要给题目,是对链表进行排序,采用归并排序;
https://leetcode-cn.com/problems/sort-list/solution/sort-list-gui-bing-pai-xu-lian-biao-by-jyd/
可以去做做
public ListNode sortList(ListNode head) {
if (head == null || head.next == null)
return head;//判断是不是已经没了,只剩一个节点,或者没有节点了,就不用排序
//cut过程
//下面就是利用物理中的快慢速度,来找到中点
//一个是一次跳一个节点,另一个跳两个节点,同样的速度,不同的步长,当第二个到了终点,第一个还在正中心
ListNode fast = head.next, slow = head;
while (fast != null && fast.next != null) {//如果是偶数个的话(1234),fast==null;;;;;如果是奇数个的话(12345),fast.next=null
slow = slow.next;
fast = fast.next.next;
}
ListNode tmp = slow.next;//tmp保存后半部分链表的头节点
slow.next = null;//将前半部分与后半部分链表切开
ListNode left = sortList(head);//求的前半部分链表
ListNode right = sortList(tmp);//求的后半部分链表
//merge过程
ListNode h = new ListNode(0);//新的头节点,来讲left和right合并
ListNode res = h;
while (left != null && right != null) {
if (left.val < right.val) {
h.next = left;
left = left.next;
} else {
h.next = right;
right = right.next;
}
h = h.next;
}
h.next = left != null ? left : right;//将剩下的连接起来
return res.next;
}这个链表的形式虽然找中心节点比较麻烦了,但是在每次新排序的节点中,空间开销不用新建整个数组,而是只需要头节点和一个索引指针(跟随新来的节点)就行。
所以对比上面两种,要知道归并排序的核心过程就是cut和merge
非递归实现
复杂度分析
关于时间复杂度很明显
我们一共要分为log n层
每一层,我们需要将每一个元素都放进一个新的数组里面去,也就是说每一层都会对所有的元素进行操作,复杂度n
总共就是nlog n
空间复杂度:
因为新建了一个数组,所以空间复杂度为O(n),但是对于链表因为只需要一个头节点和索引指针,它的空间复杂度是常数级别的
多路归并排序
归并排序思想使用
归并的思想主要用于外部排序:
外部排序可分两步
- 待排序记录分批读入内存,用某种方法在内存排序,组成有序的子文件,再按某种策略存入外存。
- 子文件多路归并,成为较长有序子文件,再记入外存,如此反复,直到整个待排序文件有序。
外部排序可使用外存、磁带、磁盘,最初形成有序子文件长取决于内存所能提供排序区大小和最初排序策略,归并路数取决于所能提供排序的外部设备数。比如在mapreduce里面,就有个排序过程,当许多小文件溢写到磁盘时,多个小文件进行归并排序。
