目录
目录
进入updateAssignmentMetadataIfNeeded方法
前不久,想写写kafka的consumer,就按照官方API写了下面这一段代码,但是总是打印不出东西。返回的records是没有东西的。于是就研究了一下这个poll方法到底是怎么执行的。调试了很久,终于弄清楚了哪里有问题
代码
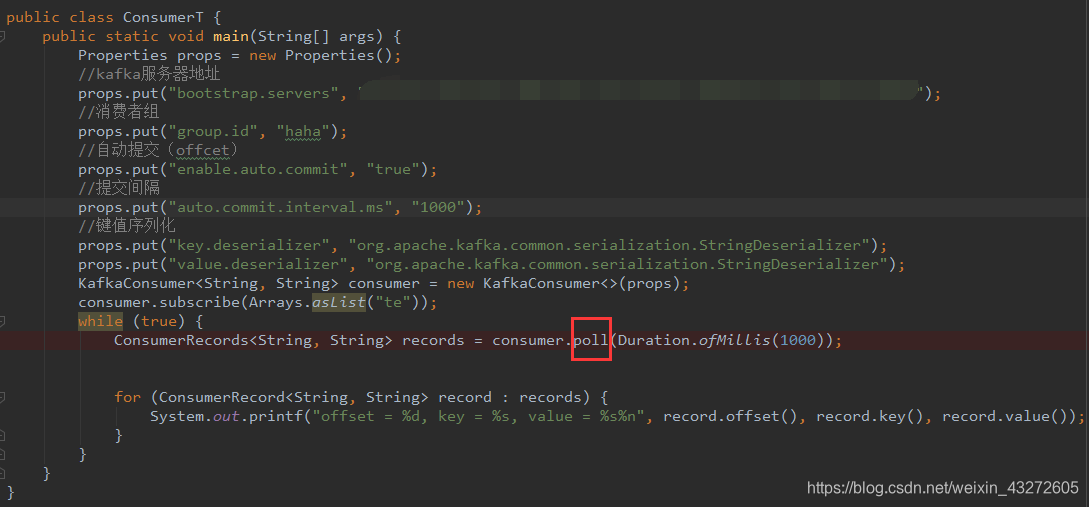
第一步,进入这个poll方法
@Override
//这个是被调用的poll方法,它又调用了下面那个poll方法
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}
//实际调用的
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
//由于 consumer 内部是非线程安全的,所以必须要确保只有一个线程访问 consumer,因此需要在这获取锁。一旦多个线程同时访问这个方法,那么就会报错。
acquireAndEnsureOpen();
try {
//Consumer 验证自己是否有任何订阅信息。如果没有指定任何 topics,那么拉取数据也就变成无稽之谈了。
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
// poll for new data until the timeout expires
//始拉取记录的循环,直到拉取超时或者接收到了一些记录。
do {
可以在拉取的过程中中断 consumer,比如你设置了拉取的超时时间以后,超过了超时时间就会抛出异常。
client.maybeTriggerWakeup();
//获取元数据添加超时机制,注意这个参数建议设置为 true,如果设置为 false,也就是走的else那条路 就会一直去同步获取元数据,极端情况可能就一直卡住了,而设置为 true 的话,就会先去尝试更新元数据信息,如果更新失败会立刻返回空记录,结束 poll 过程。
if (includeMetadataInTimeout) {
//**************************************************//
if (!updateAssignmentMetadataIfNeeded(timer)) {
//**************************************************//
return ConsumerRecords.empty();
}
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE))) {
log.warn("Still waiting for metadata");
}
}
Consumer 从 kafka 中拉取记录。
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
//这里做了一个优化,如果在上面拉取时成功返回了一些记录,那么 consumer 就会提前发送下一次的拉取请求,这样当你的应用在处理刚刚拉取的新记录的时候,consumer 也同时在后台为你拉取好了下一次要用的数据,避免了 IO 阻塞。
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.pollNoWakeup();
}
//Consumer 通过 interceptor chain 传递已经拉取的记录,interceptor 是一种插件化的,你可以通过 interceptor 很方便的对输入的记录做一些更改,一般用于日志和监控。
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
}
}注意上面的updateAssig
nmentMetadataIfNeeded 这个方法,我就是卡在了这里,我就是在这里返回了它的empty,导致返回的的结果也是空,最后打印不出东西。
先来详细看看这个方法
进入updateAssignmentMetadataIfNeeded方法
boolean updateAssignmentMetadataIfNeeded(final Timer timer) {
if (coordinator != null && !coordinator.poll(timer)) {
return false;
}
return updateFetchPositions(timer);
}
这是个判断,如果返回了false,那么就会让上面的那个结果为empty。而要返回false,必须知道coordinator!=null && !coordinator.poll(timer) 返回true。
下面东西有点儿烧脑,先来看看Coordinator
Coordinator
Kafka的coordiantor要做的事情就是group management,就是要对一个团队(或者叫组)的成员进行管理。Group management就是要做这些事情:
- 维持group的成员组成。这包括允许新的成员加入,检测成员的存活性,清除不再存活的成员。
- 协调group成员的行为。
Kafka为其设计了一个协议,就收做Group Management Protocol.
很明显,consumer group所要做的事情,是可以用group management 协议做到的。而cooridnator, 及这个协议,也是为了实现不依赖Zookeeper的高级消费者而提出并实现的。只不过,Kafka对高级消费者的成员管理行为进行了抽象,抽象出来group management功能共有的逻辑,以此设计了Group Management Protocol, 使得这个协议不只适用于Kafka consumer(目前Kafka Connect也在用它),也可以作为其它"group"的管理协议。
这是AbstractCoordinator源码的一段注释,它告诉了我们broker的coordinator的一些知识点
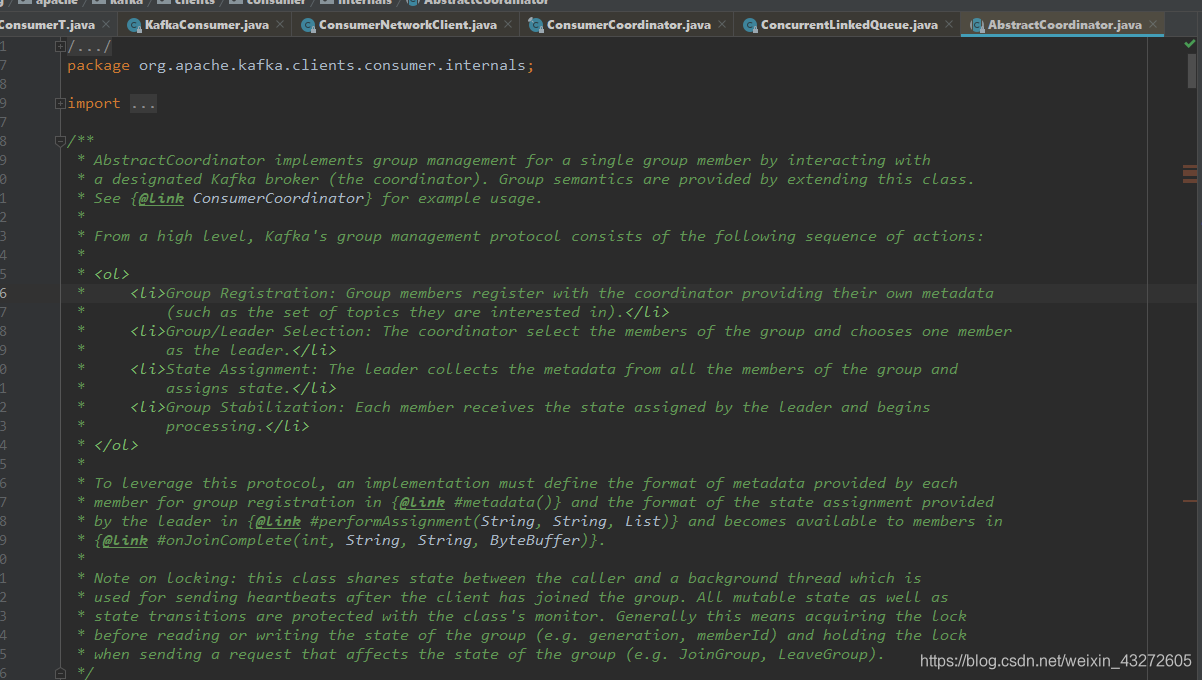
这个coordinator是有两种,一种是在broker,一种是在Concumer端
Broker端:
在Broker端,Kafka的group management protocol包括以下的动作序列:
- Group Registration:Group的成员需要向cooridnator注册自己,并且提供关于成员自身的元数据(比如,这个消费成员想要消费的topic)
- Group/Leader Selection:cooridnator确定这个group包括哪些成员,并且选择其中的一个作为leader。
- State Assignment: leader收集所有成员的metadata,并且给它们分配状态(state,可以理解为资源,或者任务)。
- Group Stabilization: 每个成员收到leader分配的状态,并且开始处理。
所有的成员要先向coordinator注册,由coordinator选出leader, 然后由leader来分配state。单个Kafka集群可能会存在着比broker的数量大得多的消费者和消费者组,而消费者的情况可能是不稳定的,可能会频繁变化,每次变化都需要一次协调,如果由broker来负责实际的协调工作,会给broker增加很多负担。所以,从group memeber里选出来一个做为leader,由leader来执行性能开销大的协调任务, 这样把负载分配到client端,可以减轻broker的压力,支持更多数量的消费组。
Consumer端:
private final ConsumerCoordinator coordinator;这个是consumer端的
ConsumerCoordinator是KafkaConsumer的一个成员变量,所以每个消费者都要自己的ConsumerCoordinator,消费者的ConsumerCoordintor只是和服务端的GroupCoordinator通信的介质。
每个KafkaServer都有一个GroupCoordinator实例,服务端的GroupCoordinator管理消费组成员和offset,它可以管理多个消费组(因为Broker本身即使存储一个topic的消息,也可以被不同的消费组订阅)。注意:组成员的状态管理(比如GroupMetadata)是在服务端的GroupCoordinator完成的,而不是由消费组的ConsumerCoordinator完成(因为消费者只能看到自己的,无法看到和自己同组的其他成员)。
!coordinator.poll(timer)条件
进入到poll里面,源码如下
- 同步更新 coordinator - 确保我们的 consumer group 的 coordinator 是最新的。
- 更新拉取的位移 - 确保当前 consumer 分配的分区更新其相应的拉取位移,如果没有更新到的话,consumer 就会使用
auto.offset.reset来更新分区的拉取位移(设置为最早位移、最近位移或者抛错)。
public boolean poll(Timer timer) {
maybeUpdateSubscriptionMetadata();
invokeCompletedOffsetCommitCallbacks();
//检查 consumer 是使用自动提交位移还是手动提交位移,这里我忽略了手动提交位移的逻辑,主要讲一下自动提交位移。
if (subscriptions.partitionsAutoAssigned()) {
// Always update the heartbeat last poll time so that the heartbeat thread does not leave the
// group proactively due to application inactivity even if (say) the coordinator cannot be found.
//检查心跳线程的状态并且报告这次的 poll 请求。当首次 poll 请求时还没有创建心跳线程,所以这里其实什么也没有做。但是之后请求时,就会检测心跳线程的状态和报告 poll 请求,如果有问题会抛出错误。
pollHeartbeat(timer.currentTimeMs());
//这是我们首次和集群建立通信的地方!ensureCoordinatorReady 方法会连接到 bootstrap.servers 的一个节点并且拉取整个集群的结构,获取到当前消费者组的 coordinator(通过设置的 group.id),然后与该 coordinator 建立连接。如果一切顺利的话那么现在我们已经和我们自己的 coordinator 成功会师,可以继续进行下一步了。
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
/**************************************************/
return false;
/**************************************************/
}
//检查当前 consumer 是否需要加入 group。事实上 consumer 正是在调用 poll 方法的时候才加入到 group 里面的,如果你更改了 topic 的注册信息(如有 consumer 退出了当前 group),那么当前 consumer 就需要再次重新加入 group。
if (rejoinNeededOrPending()) {
// due to a race condition between the initial metadata fetch and the initial rebalance,
// we need to ensure that the metadata is fresh before joining initially. This ensures
// that we have matched the pattern against the cluster's topics at least once before joining.
//支持注册 topic 的时候可以使用正则匹配。例如你指定了要订阅的 topic 的正则表达式是 my-kafka-topic-*,那么当前 consumer 就会注册到任何匹配这个表达式的 topic。一般来说我们不经常使用正则表达式进行注册,忽略这种情况。
if (subscriptions.hasPatternSubscription()) {
// For consumer group that uses pattern-based subscription, after a topic is created,
// any consumer that discovers the topic after metadata refresh can trigger rebalance
// across the entire consumer group. Multiple rebalances can be triggered after one topic
// creation if consumers refresh metadata at vastly different times. We can significantly
// reduce the number of rebalances caused by single topic creation by asking consumer to
// refresh metadata before re-joining the group as long as the refresh backoff time has
// passed.
if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
maybeUpdateSubscriptionMetadata();
}
if (!ensureActiveGroup(timer)) {
return false;
}
}
} else {
// For manually assigned partitions, if there are no ready nodes, await metadata.
// If connections to all nodes fail, wakeups triggered while attempting to send fetch
// requests result in polls returning immediately, causing a tight loop of polls. Without
// the wakeup, poll() with no channels would block for the timeout, delaying re-connection.
// awaitMetadataUpdate() initiates new connections with configured backoff and avoids the busy loop.
// When group management is used, metadata wait is already performed for this scenario as
// coordinator is unknown, hence this check is not required.
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
}
maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
return true;
}你可能会好奇为什么 consumer 需要报告它的请求,实际上调用 poll 方法去拉取数据是你的应用自己的事,然后 Kafka 并不是很信任你,它可能怀疑你在尸位素餐。所以作为预防,consumer 会记录你多久调用一次 poll 方法,一旦这个间隔超过了指定值 max.poll.interval.ms,那么当前 consumer 就会从消费者组中离开,这样其他 consumer 就可以接盘当前 consumer 的工作了
看清楚上面我写的注释,带*号的位置,我就是在那里除了问题,不能和Broker建立连接,所以出现了问题。那么我就只能通过自己的服务器检查咋回事。
最后是因为一个节点端口不能通信,由于是别人名下的一个服务器,我也动不了端口,没有任何权限,就只能换一台服务器,终于,我们这边的ConsumerCoordinator终于和Broker端的CoordinatorGroup建立了连接。

体会
通过这次排错,我特意研究了一下源码,还真是有用。比较好玩。kafka的源码好像也不是很多。实现一个简单消息队列应该挺不错的。
以后找错不用先找博客,先看看别人的代码怎么运作的。这样能够从根本找出问题。
