1.预览
1.1 消费者组(Consumer Group)
- 一个consumer group可能有若干个consumer实例
- 同一个group里面,topic的每条信息只能被发送到group下的一个consumer实例
- topic消息可以被发送到多个group
为什么需要consumer group?
consumer group是用于实现高伸缩性、高容错性的consumer机制。组内的多个实例可以同时读取消息(不同的消息),而一旦某个consumer挂了,group会把这个实例的任务立刻交给其他的consumer负责,不会丢失数据。这个过程叫做重平衡。
kafka实际上同时支持两种消息引擎,基于队列和基于发布/订阅。
- 所有的consumer实例都同属于一个group——实现了队列模型,每个消息只被一个consumer处理。
- consumer属于不同的group——实现了基于发布/订阅模型。极端情况下,每个group只有一个consumer,那么就相当于kafka把消息广播到所有的consumer。
1.2 位移(offset)
这里的位移指的是consumer端的offset,不是parititon那个。每个consumer都会为它消费的分区维护属于自己的位置信息,记录当前消费到该patition的哪个位置。
kafka中,采用consumer group保存消费者端的offset,同时还引入了checkpoint机制定期对offset进行持久化。
下图展示了consumer端的offset保存方式,kafka consumer内部是使用一个map来保存其订阅topic所属分区的位移。
/// to do
1.3 位移提交
consumer客户端需要定期向kafka集群汇报自己消费数据的进度,这个过程称为位移提交。旧版本(0.9.0.0之前)的kafka consumer把位移提交到zookeeper。而之后的版本把位移提交到kafka的一个内部topic(__consumer_offsets)上,不依赖zk保存位移信息,所以在开发新版本的consumer时也不需要连接到zk。
1.4 __consumer_offset
__consumer_offset 主题是kafka自行创建的,用户不要擅自删除。它保存的是consumer的位移信息,每条消息格式大致如下:

1.4 消费组重平衡(consumer group rebalance)
它本质上是一种协议,规定一个consumer group下所有consumer如何达成一致来分配订阅topic的分区。比如一个topic有100个partition,有一个group订阅该topic,其中有50个consumer,那么consumer group会为每个consumer平均分配两个分区,即每个consumer负责两个分区的数据读取。这个过程就成为rebalance。
2.构建consumer
3.消息轮询
3.1 poll内部原理
在Kafka1.0.0版本中,Java Consumer是一个多线程或者说是一个双线程的Java进程——创建KafkaConsumer的为用户主线程,同时consumer后台还有一个心跳线程。KafkaConsumer的poll()方法运行在主线程。这表明:消费者组执行rebalance、消息获取、coordinator管理等操作都运行在主线程。
3.2 poll使用方法
每次poll方法返回的都是订阅分区上的一组消息,如果某些分区没有准备好,可能会返回空。
try { while (true) { // 一次poll()可以拿到很多数据,不足1s时会阻塞,1000ms是最大阻塞时间 ConsumerRecords<String, String> records = consumer.poll(1000); for (ConsumerRecord<String, String> r : records) { System.out.printf("offset=%d, key=%s, value=%s, partition=%d\n", r.offset(), r.key(), r.value(), r.partition()); } } } finally { consumer.close(); }
poll()方法根据当前consumer消费位移返回消息集合。
如果poll方法没有给定参数,那么consumer端会阻塞以等待数据不断积累并最终满足consumer的需求(比如要一次至少获取1m的数据);
如果给定了参数,那么等待时间超过了指定超时时间就返回。
Java Consumer是非线程安全的,如果把它用到多线程中,会抛出KafkaConsumer is not safe for multi-threaded access异常。
超时参数的用处:
假设用户除了获取数据以外还需要定期执行其他的常规任务(每隔10s需要把消费情况记录到日志中),用户就可以设置consumer.poll(10000),让consumer在等待kafka消息的同时还可以定期执行其他任务。
如果程序唯一的任务是从kafka获取消息然后处理,那么可以采用以下方法
try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE); for (ConsumerRecord<String, String> r : records) { System.out.printf("offset=%d, key=%s, value=%s, partition=%d\n", r.offset(), r.key(), r.value(), r.partition()); } } } catch (WakeupException e) { // 忽略异常处理 }finally { consumer.close(); }这段代码可以让consumer无限等待,然后在另外一个线程中调用consumer.wakeup()来触发异常,注意,用户可以安全地在另一个线程中调用consumer.wakeup(),这时特例,其他方法都是不安全的。
总结以上,poll()的使用方法:
- consumer需要定期执行其他子任务,推荐poll(较小超时时间) + 运行标识布尔变量
- consumer不需要定期执行任务,推荐poll(MAX_VALUE) + 捕获 WakeupException的方式
4.位移管理
4.1 consumer位移
consumer需要为它要读取的分区保存消费进度,即分区中当前最新消费消息的位置,这个位置就成为offset。consuemr需要定期向kafka集群提交自己的位置信息,这里的位移值通常指下一条待消费的消息位置。
offset是实现消息交付语义的保证,如下:
- 最多一次:消息可能丢失,但不会重复处理
- 最少一次:消息不会丢失,但可能会重复处理
- 精确一次:消息一定会被处理一次且只会被处理一次
如果consumer在消费前就提交了位移,那么可以实现at most once语义;如果在消费之后提交了位移,可实现at least once语义。
consumer中的位置信息很多,下面要给出区别:
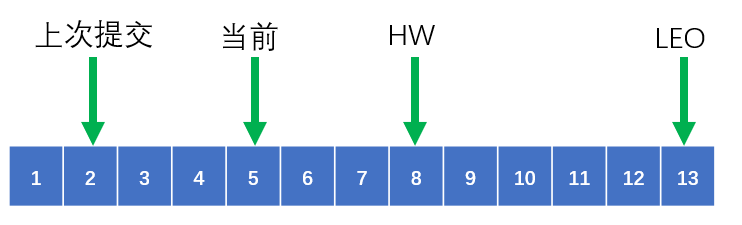
- 上次提交位移:consumer最近一次提交的位移
- 当前位移:已读取但未提交时的位置
- 水位(High Watermark):它不属于consumer管理的范围,属于分区日志管辖。consumer只能读取处于HW以下的数据
- 日志终端位移(Log End Offset):它不属于consumer管理的范围,表示某个分区副本当前保存消息最大的位移。
4.2 consumer位移管理
consumer会在kafka集群的所有broker中选择一个broker作为consumer group的coordinator,用于实现组成员管理、消费分配方案指定以及位移提交等。
consumer group首次启动时,由于没有初始的位移信息,coordinator必须为其确定初始值,这就是consumer参数 auto.offset.reset 的作用,通常,要么从最早(earliest),要么从最新(latest)开始。
当consumer运行了一段时间之后,它必须提交自己的位移。如果consumer崩溃或被关闭,它负责的分区就会分配给其他的consumer。
consumer提交位移的主要机制是通过向所属的coordinator发送位移提交请求来实现,每个位移提交请求都会往__consumer_offsets对应的分区追加一条消息。
4.3 自动提交和手动提交
默认情况下,consumer是自动提交位移的,间隔是5秒。可以通过 auto.commit.interval.ms 设置。
手动提交:由用户自行确当消息何时被真正处理完毕并提交位移。如下面的例子:
final int minBatchSize = 500; // 缓存 List<ConsumerRecord<String,String>> buffer = new ArrayList<>(minBatchSize); try { while (true) { ConsumerRecords<String,String> records = consumer.poll(1000); records.forEach(buffer::add); if (buffer.size() >= minBatchSize){ // 插入数据库 insertIntoDb(buffer); // 等数据插入数据库之后,再同步提交位移 consumer.commitSync(); // 如果提交位移失败了,那么重启consumer后会重复消费之前的数据,再次插入到数据库中 // 清空缓冲区 buffer.clear(); } } } finally { consumer.close(); }
如果要进行更加细粒度的控制,可以进行分区层的手动提交位移:
try { while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); // 处理每个分区的记录 records.partitions().forEach(p -> { List<ConsumerRecord<String, String>> partitionRecords = records.records(p); partitionRecords.forEach(pr -> { System.out.println(pr.offset() + ": " + pr.value()); }); // 获取该partition最后一个消息的位移 long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); // 提交的offset应该是下一次插入消息的位置 consumer.commitSync(Collections.singletonMap(p,new OffsetAndMetadata(lastOffset+1))); }); } } finally { consumer.close(); }
总结以下,手动提交和自动提交的区别:
| 使用方法 | 优势 | 劣势 | 交付语义保证 | 使用场景 | |
| 自动提交 | 默认或显式配置enable.auto.commit=false | 简单 | 无法精确控制,提交失败后不易处理 | 最少一次 | 对消息交付语义无需求,可容忍一定的消息丢失 |
| 手动提交 | 设置enable.auto.commit=false,并调用consumer.Sync()或consumer.Async()提交 | 可精确控制位移提交 | 额外开发成本,须自行提交 | 易实现最少一次,依赖外部状态可以实现精确一次 | 消息处理逻辑重,不允许消息丢失 |
5 重平衡(Rebalance)
5.1 预览
consumer group的rebalance本质上是一组协议,规定了consumer group是如何达成一致来分配订阅topic的所有分区的。
对于每个组,kafka的某个broker会被选举为组协调者(group coordinatior)。coordinatior负责对组的状态进行管理,它的主要职责就是当新成员到达时,促成组内的所有成员达成新的分区分配方案,即coordinator负责对组执行rebalance。
5.2 rebalce触发条件
有三个:
- 组成员发生变更,比如加入了新的consumer或有consumer离开group,或有consumer崩溃
- 组订阅的topic数量发生改变。
- 组订阅的topic的分区数发生改变。
5.3 rebalance分区分配
consumer默认提供了3种分配策略:
- range策略:将单个topic的分区按顺序排列,然后把这些分区划分成固定大小的分区段并依次分配给每个consumer。
- round-robin:把topic的所有分区按顺序排开,以轮询的方式分配给每个consumer。
- sticky:// todo
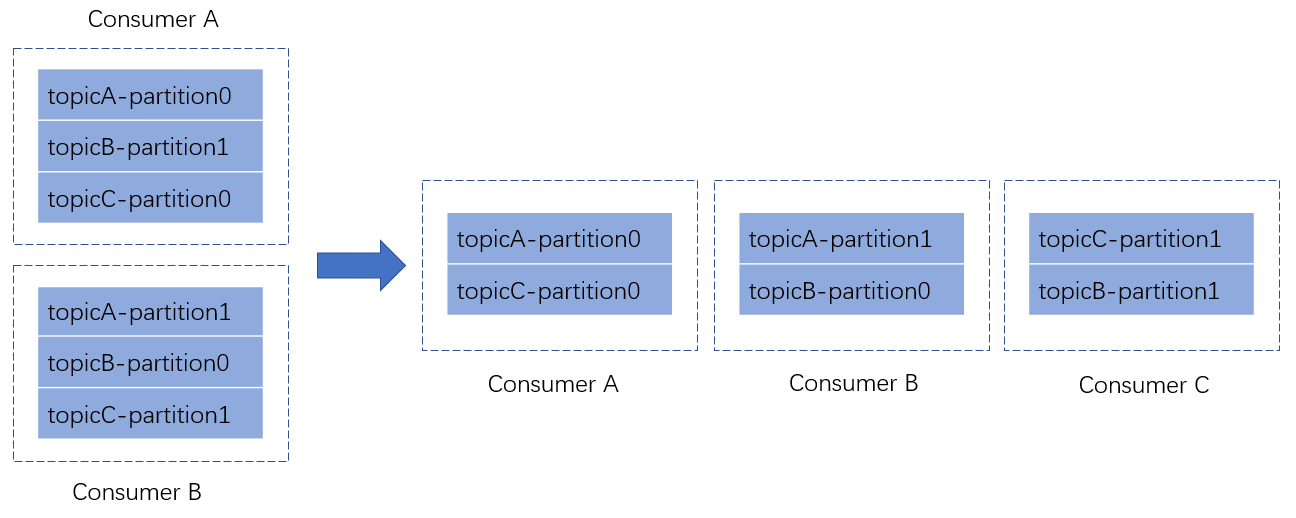
下面给一个简单的例子,假设目前某个consumer group有2个consumer A和B,当C加入时,触发了rebalance条件,coordinator会进行rebalance,根据range策略重新分配了partition。
5.4 rebalance generation
rebalance generation用于标识某次rebalance。它是一个整数,从0开始。它主要是为了保护consumer group的,比如上一届的consumer由于某些原因延迟提交了offset,但rebalance之后该group产生了新的一届成员,而这次延迟的offset提交的是旧的generation信息,因此会被consumer group拒绝。
5.5 rebalance 协议
group与coordinator共同使用rebalance协议来完成rebance操作,kafka提供了下面5个协议:
- JoinGroup请求:consumer请求加入组
- SyncGroup请求:group leader把分配方案同步更新到组内成员。
- Hearbeat请求:consumer定期向coordinator汇报心跳表明自己存活
- LeaveGroup请求:consumer主动通知coordinator该consumer即将离开组
- DescribeGroup请求:查看组的所有信息
5.6 rebalance流程
consumer group在rebalance之前必须确定coordinator所在的broker,并创建与之通信的socket。
确定coordinator位置的算法如下:
- 计算Math.abs(groupID.hashCode)%offsets.topic.num.partitions,假设结果为x
- 寻找__consumer_offset分区x的leader所在的broker,该broker就是这个group的coordinator
建立socket之后,开始进行rebalance。主要有2步:
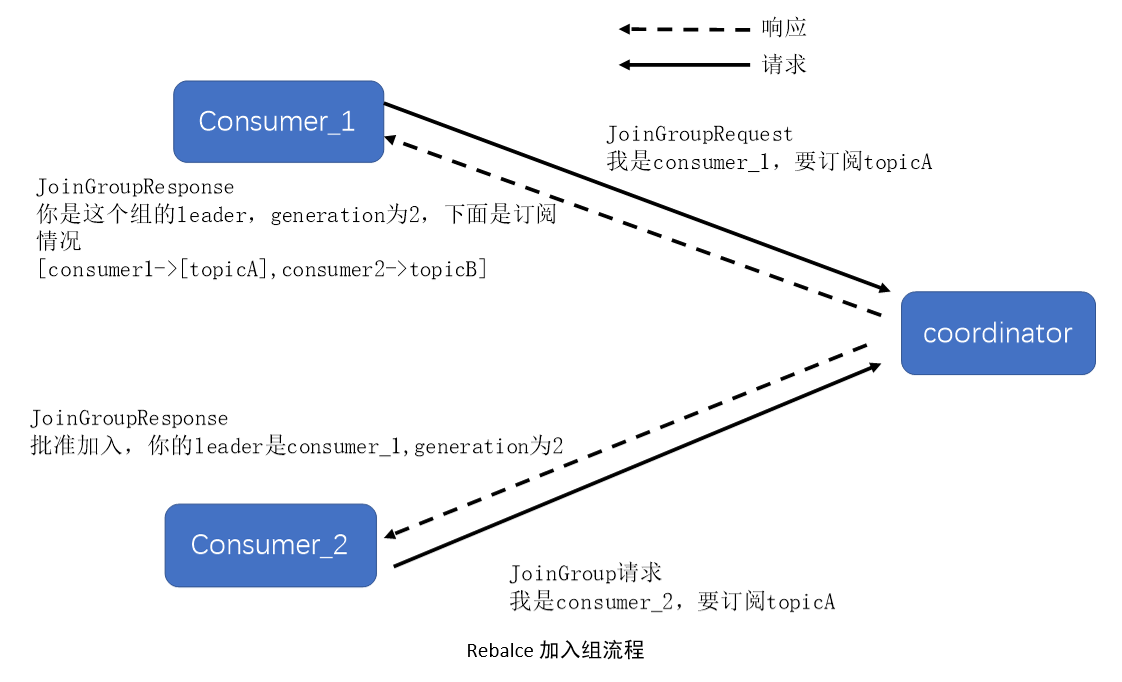
- 加入组:组内所有的consumer向coordinator发送JoinGroup请求,收集完毕后,coordinator从中选一个consumer作为group的leader,并把所有的成员信息都发给这个leader。
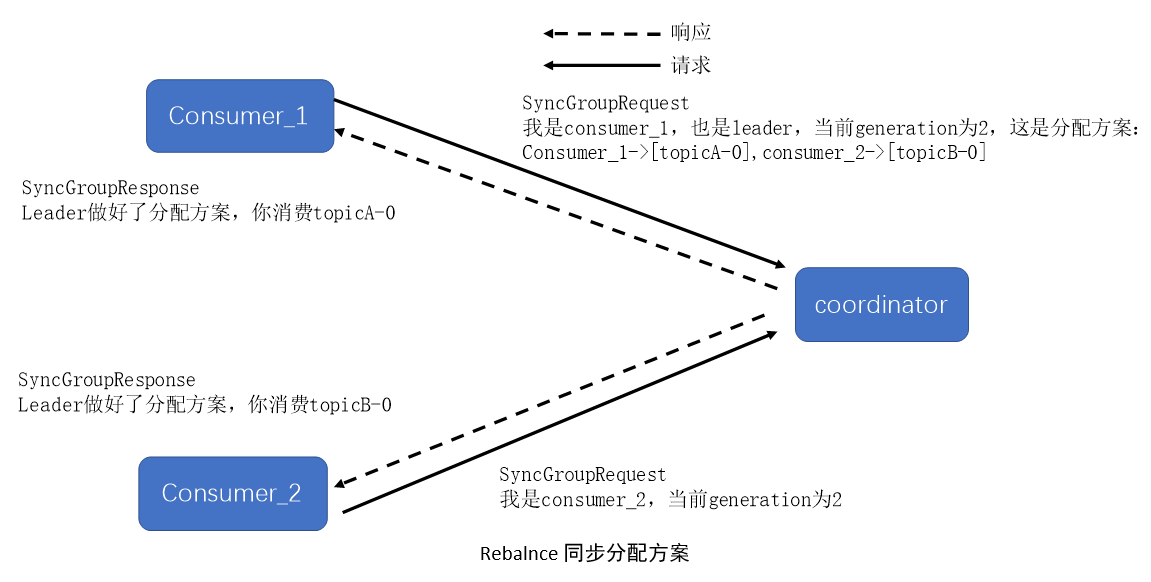
- 同步更新分配方案:leader开始制定分配方案,即根据分配策略决定每个consumer负责topic的哪些分区。方案确定后,leader会把这个分配方案以SyncGroup请求发送给coordinator。组内的所有成员都会发送SyncGroup请求,但是只有leader才会携带分配方案。coordinator接收到分配方案后把属于每个consumer的分配方案单独拿出来,左右SyncGroupResponse返回给各自的consumer。
5.7 rebalce监听器
这个监听器的主要作用是在coordinator开启一轮rebalance的前后进行一些操作,比如,要在rebalance前手动提交位移到第三方存储。
要使用监听器,要在consumer.subscribe()方法的第二个参数新建一个回调接口ConsumerRebalanceListener,里面封装了相关的逻辑,我们需要实现onPartitionsRevoked(rebalace前调用)和onPartitionAssigned(rebalance后调用)方法。
consumer.subscribe(Arrays.asList("test1"), new ConsumerRebalanceListener() { //rebalance监听器
//在coordinator开启新一轮rebalance前调用
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
//这里可以进行一些操作,比如把手动提交的位移存储到第三方
partitions.forEach(tp -> saveOffsetInExternalStore(consumer.position(tp)));
joinStart.set(System.currentTimeMillis());
}
//在rebalance完成后调用
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
totalRebalanceTimeMs.addAndGet(System.currentTimeMillis() - joinStart.get()); //更新总的rebalance时长
// 从外部存储读取每个topicPartition的位移,然后移动当前consumer的位移到该位置
partitions.forEach(tp -> consumer.seek(tp,readOffsetFromExternalStore(tp)));
}
private long readOffsetFromExternalStore(TopicPartition tp) {
}
// 保存到数据库
private void saveOffsetInExternalStore(long position) {
}
});
// 位移处理后就可以从上面移动到的位置开始读取了
try {
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(1000);
consumerRecords.forEach(r ->
System.out.printf("offset=%d, key=%s, value=%s, partition=%d\n",
r.offset(), r.key(), r.value(), r.partition()));
}
} finally {
System.out.println("totoalRebalanceTimeMs: " + totalRebalanceTimeMs);
consumer.close();
}
6 多线程消费
KafkaConsumer是非线程安全的,多个线程中要避免共用一个KafkaConsumer。
那么如何实现多线程的consumer消费呢?有两种方法
1.每个线程维护一个KafkaConsumer,每个consumer消费固定数目的分区。
2.单个KafkaConsumer实例+多worker线程。仅由一个consumer实例接收消息,然后立刻交给其他的工作线程进行消息的处理。
7 独立Consumer
前面讨论的consumer都是以consumer group的形式存在的,group自动帮用户执行分区分配和rebalance。
standalone consumer间彼此独立工作互不干扰,任何一个consumer崩溃都不会影响其他standalone consumer的工作。
使用standalone consumer的方法就是调用KafkaConsumer的assign方法。这个方法接收一个分区列表,直接赋予该consumer访问这些分区的权力。
List<TopicPartition> partitions = new ArrayList<>(10); consumer.partitionsFor("test1").forEach(partitionInfo -> partitions.add(new TopicPartition(partitionInfo.topic(), 0))); //只订阅分区0的消息 //赋予consumer访问分区的能力 consumer.assign(partitions);
注意:assign和subscribe不能混用。