HashMap的特性
1.HashMap存储键值对实现快速存取,允许为null。key值不可重复,若key值重复则覆盖。
2.非同步,线程不安全。
3.底层是hash表,不保证有序(比如插入的顺序)
1.HashMap的底层原理是什么?
HashMap基于hashing的原理,jdk8后采用数组+链表+红黑树的数据结构。我们通过put和get存储和获取对象。当我们给put()方法传递键和值时,先对键做一个hashCode()的计算来得到它在bucket数组中的位置来存储Entry对象。当获取对象时,通过get获取到bucket的位置,再通过键对象的equals()方法找到正确的键值对,然后在返回值对象。
2.hashMap中put是如何实现的?
1.计算关于key的hashcode值(与Key.hashCode的高16位做异或运算)
2.如果散列表为空时,调用resize()初始化散列表
3.如果没有发生碰撞,直接添加元素到散列表中去
4.如果发生了碰撞(hashCode值相同),进行三种判断
4.1:若key地址相同或者equals后内容相同,则替换旧值
4.2:如果是红黑树结构,就调用树的插入方法
4.3:链表结构,循环遍历直到链表中某个节点为空,尾插法进行插入,插入之后判断链表个数是否到达变成红黑树的阙值8;也可以遍历到有节点与插入元素的哈希值和内容相同,进行覆盖。
5.如果桶满了大于阀值,则resize进行扩容
3.hashMap中get是如何实现的?
对key的hashCode进行hashing,与运算计算下标获取bucket位置,如果在桶的首位上就可以找到就直接返回,否则在树中找或者链表中遍历找,如果有hash冲突,则利用equals方法去遍历链表查找节点。
4.当两个对象的hashcode相同会发生什么?
会产生哈希碰撞,若key值相同则替换旧值,不然链接到链表后面,链表长度超过阙值8就转为红黑树存储. HashCode相同,通过equals比较内容获取值对象
5.HashMap和HashTable的区别
相同点:都是存储key-value键值对的
不同点:
HashMap允许Key-value为null,hashTable不允许;
hashMap没有考虑同步,是线程不安全的。hashTable是线程安全的,给api套上了一层synchronized修饰;
HashMap继承于AbstractMap类,hashTable继承与Dictionary类。
迭代器(Iterator)。HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException。
容量的初始值和增加方式都不一样:HashMap默认的容量大小是16;增加容量时,每次将容量变为"原始容量x2"。Hashtable默认的容量大小是11;增加容量时,每次将容量变为"原始容量x2 + 1";
添加key-value时的hash值算法不同:HashMap添加元素时,是使用自定义的哈希算法。Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
6.什么是HashSet?
HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。
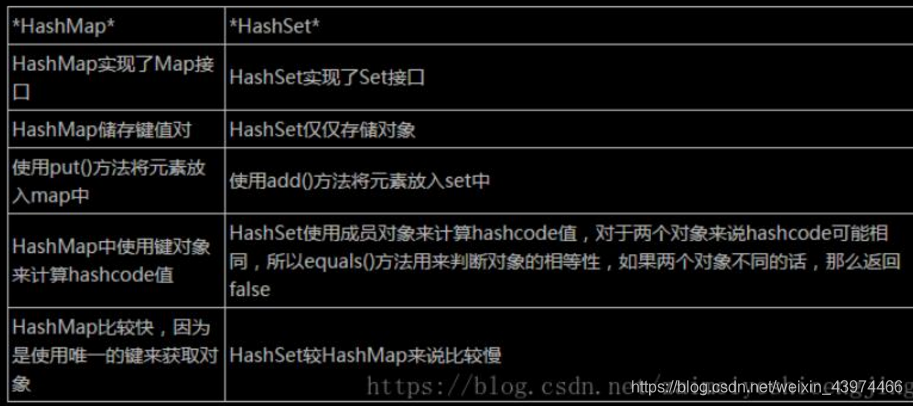
7.HashSet与HashMap的区别?
8.传统hashMap的缺点(为什么引入红黑树?
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题
9.平时在使用HashMap时一般使用什么类型的元素作为Key?
选择Integer,String这种不可变的类型,像对String的一切操作都是新建一个String对象,对新的对象进行拼接分割等,这些类已经很规范的覆写了hashCode()以及equals()方法。作为不可变类天生是线程安全的,
10.如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
超过阙值会进行扩容操作,概括的讲就是扩容后的数组大小是原数组的2倍,将原来的元素重新hashing放入到新的散列表中去。
