结合最近正做的马银金服比赛中遇到的小问题,以kaggle上的house prices competition的一篇kernel的特征工程处理为例子做一些简单的总结。
house prices地址:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
kernel地址:https://www.kaggle.com/serigne/stacked-regressions-top-4-on-leaderboard
1.离群点分析与处理(outliers)
数据离散程度的图,分类用boxplot,回归用scatter。也不知道我是哪根筋搭错了,二分类问题上来就画了个scatter,画面很美。
而且好似分类问题没有离群点的处理,如果有的话也是4C标准里面的数据准确性(correct)出了问题,比如80岁误写成800这种情况,这就需要手动纠正。
重要的是:outlier的处理不能做上头,一些主要的特征上,离群很夸张的点是完全没问题的,但是如果每个feature都去除,或者去除的离群点过多的话肯定会对最后的模型精确度造成很大影响。
2.正太分布的数据转换(data transformation)
因为回归问题上很多的ML model都需要数据服从正太分布,当然这是理想状况,大多时候数据是不正太分布的。
首先通过图标查看数据:
distplot():
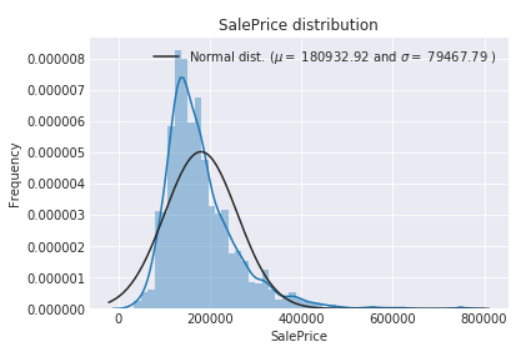
很明显我们看出房价不服从正太分布。
还有一个很直观的方法:
Q-Q图,可以用来检验数据是否服从某一分布,scipy里有现成的函数来实现:probplot()
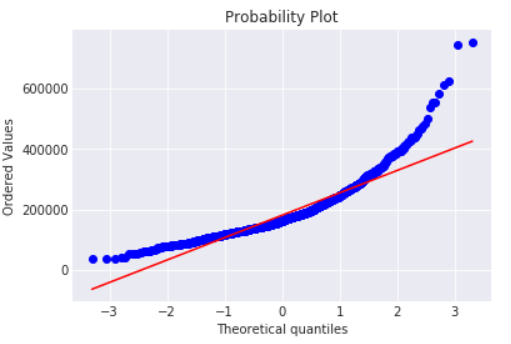
这样就更明显,数据并不符合正态分布,因此进行data-transformation:
简单粗暴的log(1+x),对应numpy函数:log1p(data),转换后:
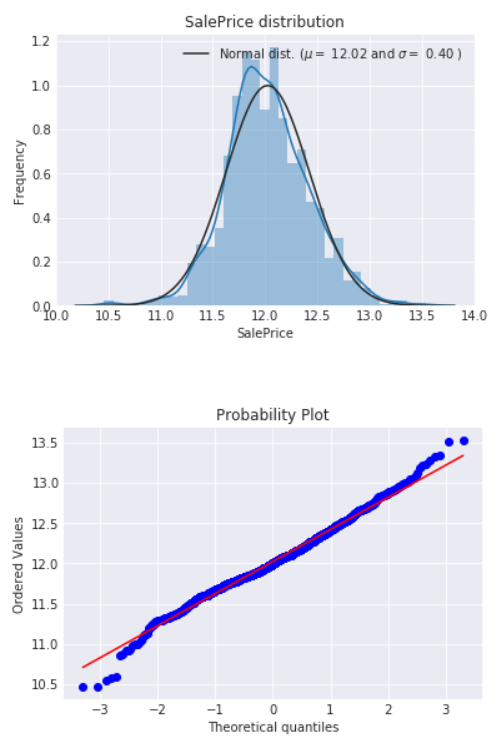
好多了。