因子——表示名义型变量或有序变量。
名义变量一般表示类别,如性别,种族等等。
有序变量是有一定排序顺序的变量,如职称,年级等等。
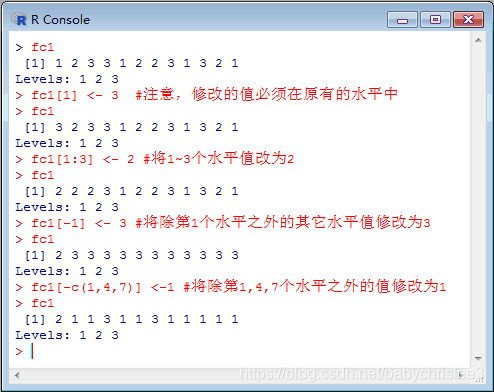
使用factor()函数
f <- factor(x=charactor(), levels, labels=levels, exclude = NA, ordered = is.ordered(x), namax = NA)
其中:
x 为创建因子的数据,是一个向量;
levels:因子数据的水平,默认是x中不重复的值;
labels:标识某水平的名称,与水平一一对应,以方便识别,默认取levels的值;
exclude:从x中剔除的水平值,默认为NA值;
ordered:逻辑值,因子水平是否有顺序(编码次序),若有取TRUE,否则取FALSE;
nmax:水平个数的限制。
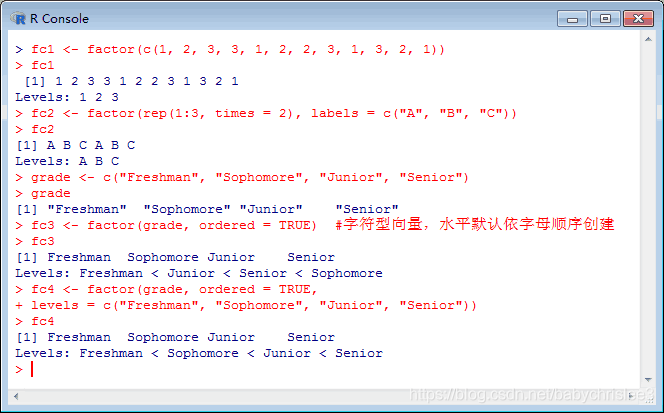
gl()函数
gl(n, k, length = n*k, labels = 1:n, ordered = FALSE)
n: 正整数,表示因子的水平个数
k:正整数,表示每个水平重复的次数;
length: 正整数,表示因子向量的长度,默认为n*k
labels: 表示因子水平的名称,默认值为1:n
ordered: 逻辑变量,表示因子水平是否是有次序的,默认值为FALSE
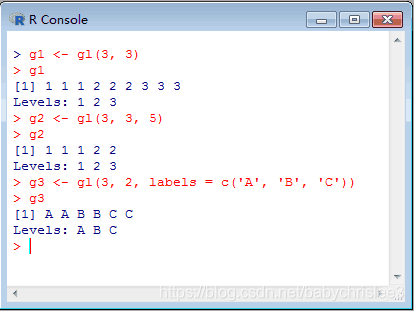
因子的索引
fc3[fc3 > ‘Junior’] #对于有序因子可以使用>,>=,<,<=,!=,==
而非有序因子,只可以使用!=和==
注意:因为因子一般表示名义变量或有序变量,如非有序因子,则使用>,>=,<,<=比较大小是没有意义的。
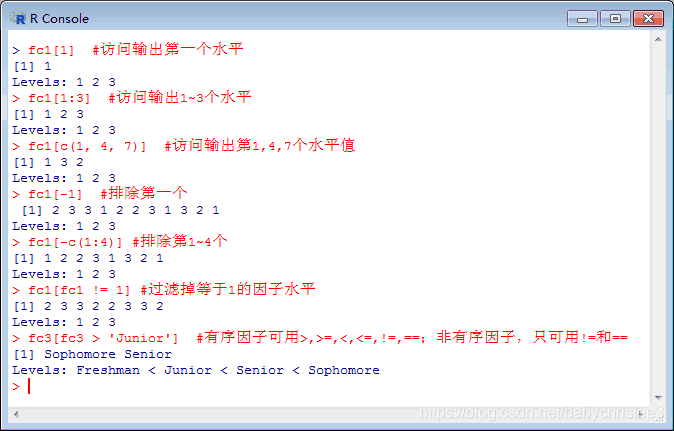
因子的修改