Linux进程管理
Linux进程管理(三)进程调度之主动调度
在上一篇文章中,我们讲了Linux进程调度的总体内容,接下来的两篇文章我们将来讨论进程调度具体是什么时候发生的
一、抢占式调度和主动调度
前面我们说过,进程的切换总是通过 shedule 函数发生的,而 schedule 函数可以是在系统调用返回、中断返回等时机被调用,也可以进程在驱动程序中主动调用
我们把在系统调用返回等时机调用 schedule 函数的这种非进程自愿情况称为抢占式调度。把进程在驱动程序中主动调用 schedule 函数来发生进程切换的这种情况称为主动调度
本文将讨论主动调度,抢占式调度将在下一篇文章中讲解
二、主动调度的发生的情况
主动调度一般在应用程序读取某个设备时,设备此时数据还没有准备好,进程就进入睡眠,发生进程调度切换到其它进程运行
例如应用想从网卡读取数据,但是此时网卡没有数据,那么驱动程序就会让进程睡眠,然后发生进程调度。又或者应用想读取按键,但是按键还没有被按下,此时驱动程序也会让进程睡眠,然后发生进程调度
在驱动程序中,对应的实现如下
/*
* 本文作者:_JT_
* 博客地址:https://blog.csdn.net/weixin_42462202
*/
/* 网卡的驱动程序 */
tap_do_read(...)
{
...
DEFINE_WAIT(wait); //定义一个等待队列
while(!condition)
{
add_wait_queue(&wq_head, &wait); //将进程添加到等待队列中
set_current_state(TASK_UNINTERRUPTIBLE); //设置进程的状态为睡眠态
...
/* 主动调度 */
schedule();
...
}
...
}
/*
* 本文作者:_JT_
* 博客地址:https://blog.csdn.net/weixin_42462202
*/
/* 按键的驱动程序 */
button_do_read(...)
{
...
DEFINE_WAIT(wait); //定义一个等待队列
while(!condition)
{
add_wait_queue(&wq_head, &wait); //将进程添加到等待队列中
set_current_state(TASK_UNINTERRUPTIBLE); //设置进程的状态为睡眠态
...
/* 主动调度 */
schedule();
...
}
...
}
如果你看不懂 schedule 前的代码也没有关系,只需要知道那是进程睡眠前做的一些准备动作就行
真正的进程切换发生在 schedule 函数中,调用 schedule 函数,会发生进程调度,切换到其它进程运行,当前进程进入睡眠
这就是进程主动调度的一般情况,接下来我们看一看 schedule 函数做了什么,具体是怎么实现进程切换的
三、schedule 函数
schedule 函数的定义如下
asmlinkage __visible void __sched schedule(void)
{
...
__schedule(false);
...
}
schedule 函数最主要的是调用 __schedule 函数,下面看一下 __schedule 函数的定义
/*
* 本文作者:_JT_
* 博客地址:https://blog.csdn.net/weixin_42462202
*/
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
struct rq *rq;
int cpu;
/* 获取运行队列 */
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
...
/* 从运行队列中挑选下一个运行的进程 */
next = pick_next_task(rq, prev, &rf);
...
...
/* 发生进程切换 */
context_switch(rq, prev, next, &rf);
...
}
- 首先获取CPU对应的运行队列,前面我们说过,每个CPU都有其自己对应的运行队列
- 然后通过 pick_next_task 来获取下一个运行的进程
- 最后通过 context_switch 来实现进程切换
所以 schedule 函数可以总结成两件事,第一件事就是从运行队列中挑选下一个运行的进程,第二件事就是实现进程切换
挑选下一个运行的进程
首先我们来看如何通过 pick_next_task 来获取下一个运行的进程,其定义如下
/*
* 本文作者:_JT_
* 博客地址:https://blog.csdn.net/weixin_42462202
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
...
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
return p;
}
}
}
按优先级遍历所有的调度类,从对应的运行队列中找到下一个运行的任务,上一篇文章对这部分已经做了详细的讲解,这里不再细说了,如果不记得的,可以回忆一下下面这张图
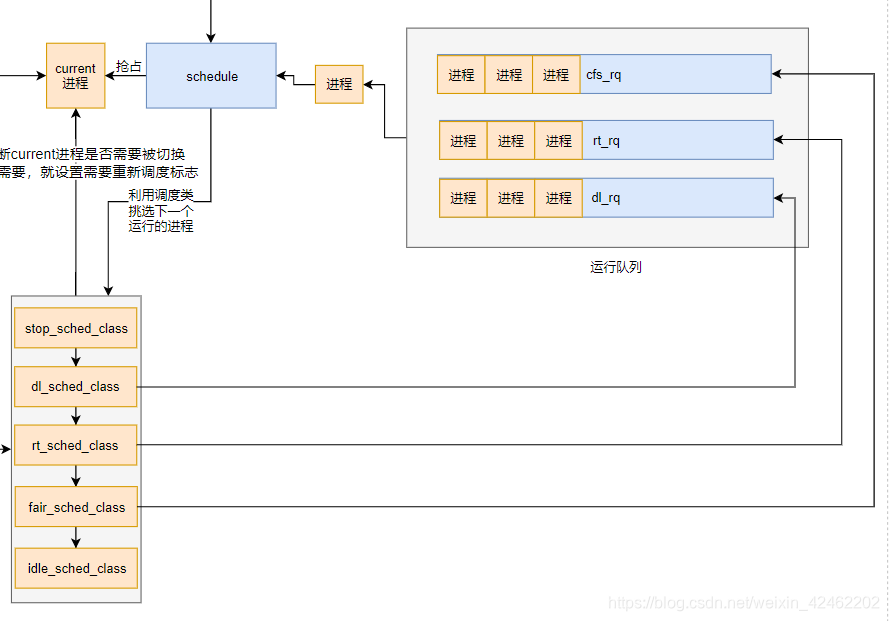
接下来我们看第二件事,实现进程切换
进程切换
在 schedule 通过 pick_next_task 找到下一个进程后,会调用 context_switch 来实现进程切换,其定义如下
/*
* 本文作者:_JT_
* 博客地址:https://blog.csdn.net/weixin_42462202
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
/* 切换内存空间 */
mm = next->mm;
oldmm = prev->active_mm;
...
switch_mm_irqs_off(oldmm, mm, next);
/* 切换进程 */
switch_to(prev, next, prev);
/* 对上一个进程进行清理 */
return finish_task_switch(prev);
}
- 首先是通过 switch_mm_irqs_off 来进行进程地址空间的切换,其中的 mm 表示下一个进程的地址空间,oldmm 表示当前进程的地址空间,switch_mm_irqs_off 主要做的是重新加载页表
- 然后会调用 switch_to 进行进程切换,switch_to 返回后,进程已经切换完毕
- 最后调用 finish_task_switch 对上一个进程做一些清理工作
下面我们来看 switch_to 做了什么,它其实是一个宏定义,如下
switch_to(prev, next, prev);
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
__switch_to 函数的具体内容这里就不看了,它里面做的最重要的一件事就是切换内核栈,将栈顶指针寄存器指向新进程的内核栈
到这里,进程的切换就已经完成了
真的这样就完成了吗?
我们先想一下,进程切换主要做了什么
-
进程地址空间的切换
进程与进程之间的地址是相互独立的,所以需要切换进程的地址空间
-
指令指针的切换
进程切换后,要恢复进程原本执行的地方
我们下面看看 context_switch 主要做了哪些事情
- 切换进程用户地址空间,重新加载页表
- 在 switch_to 中切换进程的内核栈
- 切换内核栈后继续执行,此时已经算是进程切换完毕了
从上面我们可以看到,我们已经完成了进程地址空间的切换
但是我们并没有看到指令指针的修改,我们说一旦内核栈切换完后,就算进程切换完毕,这是为什么呢?
我们前面一直强调,进程切换都是调用 schedule 函数来实现的,schedule 函数中会调用 switch_to 来进行进程切换。对于每个进程来说,都是在 switch_to 函数中被切换掉的,所以当进程再次被运行的时候,也是从 switch_to 函数中继续运行是没毛病的
为了让你理解进程切换的过程,我打算把从应用层到进程切换过程给复盘一遍
我将讨论这样一个场景,现在有一个进程,它通过系统调用读取网卡数据,但是网卡此时没有数据,所以它会睡眠。当网卡有数据的时候,它又被唤醒重新开始运行,然后返回用户态
-
当进程A发生系统调用的时候,会将进程A在用户态运行的时候的寄存器保存下来(栈顶指针、指令指针等等)
还记得内核栈的模样吗?它长下面这个样子
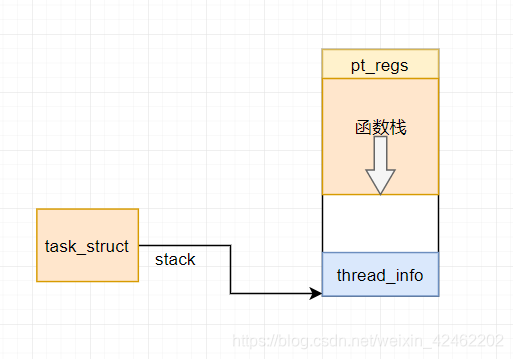
其中的 pt_regs 就用来保存进程在用户态运行时寄存器的值
-
发生系统调用进入内核态后,进程最终会调用到网卡驱动的读函数
网卡的读函数大概是这个样子
/* * 本文作者:_JT_ * 博客地址:https://blog.csdn.net/weixin_42462202 */ /* 网卡的驱动程序 */ tap_do_read(...) { ... DEFINE_WAIT(wait); //定义一个等待队列 while(!condition) { add_wait_queue(&wq_head, &wait); //将进程添加到等待队列中 set_current_state(TASK_UNINTERRUPTIBLE); //设置进程的状态为睡眠态 ... /* 主动调度 */ schedule(); ... } ... } -
当网卡没有数据的时候,进程A就会进入睡眠,调用 schedule 函数发生进程切换,schedule 又会调用 switch_to 来真正完成进程切换,此时该进程的内核栈就变成下面这个样子
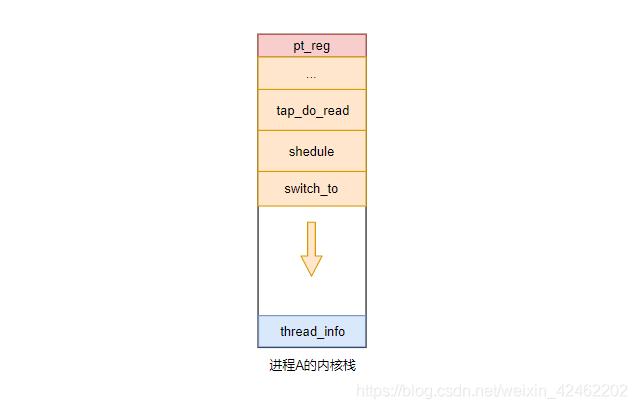
在进程A的内核栈中,在调用 schedule 函数的时候,会保存下来 tap_do_read 的返回地址,在调用 switch_to 的时候,会保存 schedule 函数的返回地址
而在调用 switch_to 后,栈顶指针就会指向新进程的内核栈,所以进程A的函数栈就保存成上面的样子,直到被唤醒重新运行
-
在 switch_to 函数中切换进程栈后,就算进程切换完毕了。假如我们此时切换到进程B,如果进程B当初是准备读取按键,由于按键没有被按下,所以进入睡眠,进程B也是通过 schedule 函数来实现进程切换的。那么进程B内核栈的内容跟进程A的内核也是相似的,如下
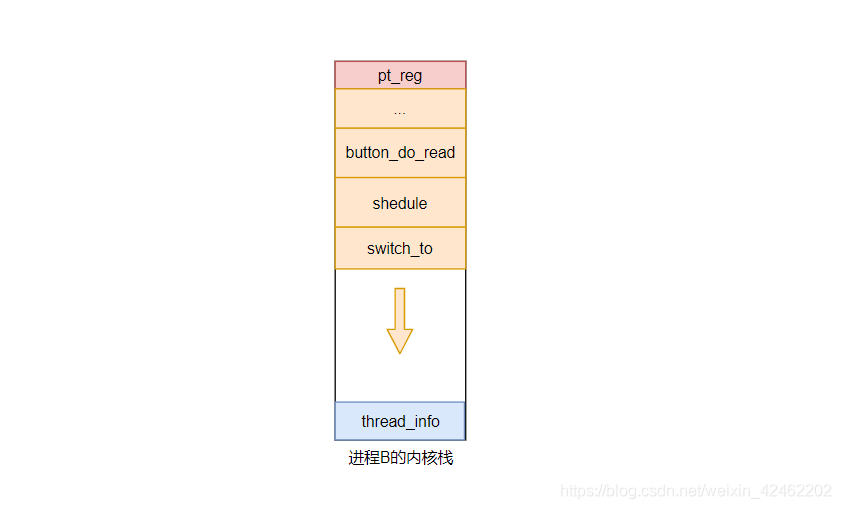
所以切换到进程B后,还是在 switch_to 函数中继续运行,之后函数调用返回,从栈中弹出返回地址,最后会返回到 button_do_read 函数,这也是进程B在内核态运行时候的
-
进程B当初也是通过系统调用进入内核的,现在进程B读取到按键数据后,要返回用户空间,此时内核会将进程B的内核栈中 pt_reg 里面所有保存下来的寄存器恢复,例如会重新设置栈指针寄存器,指令指针寄存器。而进程B的用户地址空间映射在 schedule 函数中已经修改了,这样子,进程B又回到了原来用户空间运行的位置继续运行下去
-
同理,当某个时刻调用了 schedule 函数,切换到进程A,也是一样的过程
到此,你应该对进程切换有所了解了
下面再来讨论一个问题,为什么进程切换涉及到三个进程,而不是两个进程?
进程切换不是只是从进程A切换到进程B吗,为什么在 switch_to 中是三个进程
/*
* 本文作者:_JT_
* 博客地址:https://blog.csdn.net/weixin_42462202
*/
switch_to(prev, next, prev);
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
其实进程切换涉及到的是三个进程,为何?下面我来为你讲解
假设进程A切换到进程B,进程B又进行了多次进程切换,最后切换到进程C,进程C又切换到进程A,如下图所示
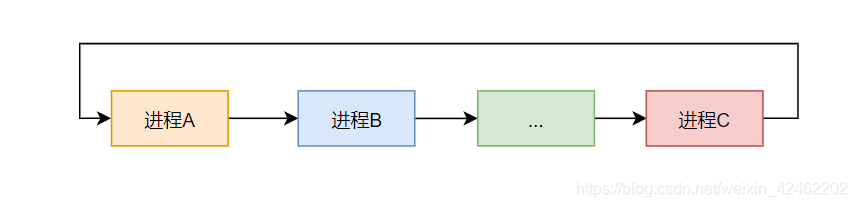
你看,跟进程A相关的进程有两个,一个是进程B,一个是进程C
进程A切换到进程B,进程A又从进程C切换过来,所以这个过程涉及到三个进程A、B、C
在 switch_to 中,有三个变量,在进程A被唤醒的时候,prev 表示进程A,next 表示进程B,last 表示进程C
/*
* 本文作者:_JT_
* 博客地址:https://blog.csdn.net/weixin_42462202
*/
#define switch_to(prev, next, last) \
do { \
((last) = __switch_to((prev), (next))); \
} while (0)
那么 switch_to 是怎么实现的呢?
prev 和 next 在进程被切换前就保存在进程的内核栈中,所以进程再被唤醒的时候很自然通过局部变量就可以得到它们
而 last 对于被唤醒的进程,又不存在于它的内核栈中,那么 last 对于进程来说是怎么获取的呢?
你可以注意到,last 是通过 __switch_to 的函数返回值获取的
以进程C切换到进程A为例,进程C将自己的进程描述符地址放到寄存器中,然后切换到进程A,进程A得到 __switch_to 返回值,__switch 的返回值其实就是寄存器的值,也就是进程C的进程描述符地址
这样子进程就知道自己是从哪一个进程切换过来的,那么为什么进程需要直到它是从哪一个进程切换过来的呢?
因为在进程切换后,新进程有必要对它上一个进程做一些清理工作
好了,这篇文章到这里就差不多结束了,下面进入总结时刻
四、总结
- 进程发生切换总是调用 schedule 函数进行的,进程调度分抢占式调度和主动调度,主动调度表示的是进程主动调用 schedule 函数发生进程切换
- schedule 函数主要做了两件事,第一件事是将通过调度类从运行队列中挑选下一个运行的进程,第二件事是进行进程切换
- 进程切换会切换进程地址空间,重新加载页表,还有切换内核栈
- 进程切换涉及三个进程,新进程需要对上一个进程做一些清理工作
