转载请标明出处floater的csdn blog,http://blog.csdn.net/flaoter
上节内容对linux进程的表示和常用基础知识等进行了说明,本节开始对进程管理进行说明。
1 进程调度数据结构
1.1 数据结构
在介绍进程调度数据结构之前,先看一下task_struct中与进程调度相关的数据成员。
struct task_struct{
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
unsigned int policy;
int nr_cpus_allowed;
cpumask_t cpus_allowed;
}sheched_class代表调度器类和它的方法, linux kernel支持目前五种调度器类,将在下面进行详细说明。
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
/*
* It is the responsibility of the pick_next_task() method that will
* return the next task to call put_prev_task() on the @prev task or
* something equivalent.
*
* May return RETRY_TASK when it finds a higher prio class has runnable
* tasks.
*/
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p);
void (*task_waking) (struct task_struct *task);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
#endif
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
/*
* The switched_from() call is allowed to drop rq->lock, therefore we
* cannot assume the switched_from/switched_to pair is serliazed by
* rq->lock. They are however serialized by p->pi_lock.
*/
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_move_group) (struct task_struct *p);
#endif
};
rq是就绪队列,数据结构定义如下,
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned int nr_running;
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX]; //跟踪此前的负荷状态
unsigned long last_load_update_tick;
unsigned int misfit_task;
/* capture load from *all* tasks on this cpu: */
struct load_weight load; //就绪队列当前负荷
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
struct task_struct *curr, *idle, *stop;
unsigned long next_balance;
struct mm_struct *prev_mm;
unsigned int clock_skip_update;
u64 clock;
u64 clock_task;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
unsigned long cpu_capacity;
unsigned long cpu_capacity_orig;
struct callback_head *balance_callback;
unsigned char idle_balance;
/* For active balancing */
int active_balance;
int push_cpu;
struct cpu_stop_work active_balance_work;
/* cpu of this runqueue: */
int cpu;
int online;
struct list_head cfs_tasks;
#ifdef CONFIG_INTEL_DWS
struct intel_dws dws;
#endif
u64 rt_avg;
u64 age_stamp;
u64 idle_stamp;
u64 avg_idle;
/* This is used to determine avg_idle's max value */
u64 max_idle_balance_cost;
#endif
/* calc_load related fields */
unsigned long calc_load_update;
long calc_load_active;
#ifdef CONFIG_SMP
struct llist_head wake_list;
#endif
#ifdef CONFIG_CPU_IDLE
/* Must be inspected within a rcu lock section */
struct cpuidle_state *idle_state;
int idle_state_idx;
#endif
};
每个cpu对应一个就绪队列
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);调度实体,本节中调度实体都是进程,当CONFIG_FAIR_GROUP_SCHED定义时,调度实体是进程组。
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
#ifdef CONFIG_SMP
/* Per entity load average tracking */
struct sched_avg avg;
#endif
};在进入讲解调度器之前还需要对linux进程表示的两个常用属性进行介绍,它们是进程调度依赖的度量,分别是优先级和负荷权重。
1.2 优先级
linux支持的进程有普通进程和实时进程。普通进程有三种优先级,静态优先级,普通优先级,动态优先级。实时进程与之对比没有静态优先级,取代的是实时优先级。
• 静态优先级(static_prio) ,非实时进程的优先级[100,139]
由用户预先指定,以后不会改变 ;在进程创建时分配,该值会影响分配给任务的时间片的长短和非实时任务动态优先级的计算。
• 实时优先级(rt_priority),实时进程的优先级[0~99]
指明这个进程为实时进程;较高权值的进程总是优先于较低权值的进程。
• 普通优先级(normal_prio) :
指的是任务的常规优先级,该值基于static_prio和调度策略计算。
• 动态优先级( prio ):
基于normal_prio抽象的,调度器直接采用的优先级。
normal_prio和prio的赋值过程如下代码所示,
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
/*
* If we are RT tasks or we were boosted to RT priority,
* keep the priority unchanged. Otherwise, update priority
* to the normal priority:
*/
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_dl_policy(p))
prio = MAX_DL_PRIO-1;
else if (task_has_rt_policy(p))
prio = MAX_RT_PRIO-1 - p->rt_priority;
else
prio = __normal_prio(p);
return prio;
}
static inline int __normal_prio(struct task_struct *p)
{
return p->static_prio;
}
实时进程prio = normal_prio = static_prio = MAX_RT_PRIO+20+nice
普通进程prio = normal_pro=MAX_RT_PRIO-1-rt_priority
关于优先级的设置可以使用如下API,
(1) nice(int increment )
(2) int setpriority(int which, int who, int prio)
(3) int sched_setscheduler(pid_t pid, int policy, const struct sched_param *param) ;

1.3 负荷权重
优先级与负荷权重的对应关系如下,
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};2 调度器
linux 调度器分为主调度器和周期调度器,主调度器的实现是schedule,周期调度器的实现是scheduler_tick。
kernel定义了如下五种调度器类,
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
调度器类优先级是
stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_sched_class
实时进程的调度有SCHED_FIFO和SCHED_RR两种调度策略,普通进程的完全公平调度有SCHED_NORMAL,SCHED_BATCH和SCHED_IDLE三种调度策略。
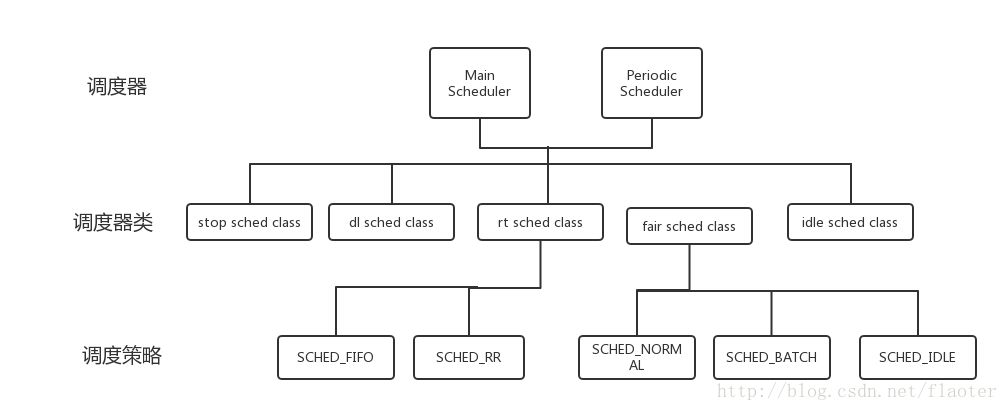
2.1 主调度器
schedlue函数实现如下,
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable(); //禁止内核抢占
__schedule(false);
sched_preempt_enable_no_resched(); //恢复内核抢占
} while (need_resched()); //检查用户抢占
}在对schedule的实现主函数__schedule进行解释前,需要先对内核抢占和用户抢占进行说明。
2.1.1 用户抢占
从系统调用返回之后,内核会检查当前进程是否设置了thread_info中的flags成员为TIF_NEED_RESCHED。
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
static __always_inline bool need_resched(void)
{
return unlikely(tif_need_resched());
}发生用户抢占的时机是从系统调用或者中断响应函数返回用户空间时。
常见的场景有:
1. 时间片消耗完时,scheduler_tick()函数就会设置need_resched标志
2. 进程从中断、异常及系统调用返回到用户态时
3.当前任务或其他任务优先级发生改变,可能会使高优先级的任务进入就绪状态;
…
2.1.2 内核抢占
2.6之前的内核并不支持内核抢占,当低优先级任务在内核态运行时,高优先级的任务不能及时占有CPU,只有当低优先级任务退出内核态后才能进行抢占,导致任务响应时间长。
当前kernel也并不是在任意时机都可以进行任务抢占,在访问临界资源和中断上下文中内核抢占功能会被关闭。
下面两图分别对应非抢占式内核和抢占式内核的任务抢占过程,非抢占式内核RT task在Normal task退出内核态后才可以进行抢占,抢占式内核的RT task当Normal task内核态退出访问临界区资源后就进行了抢占。
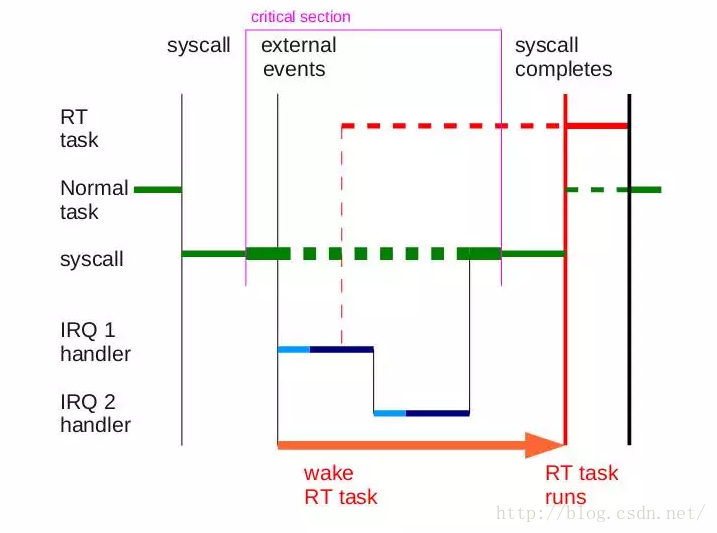 Non-preemptible Non-preemptible
|
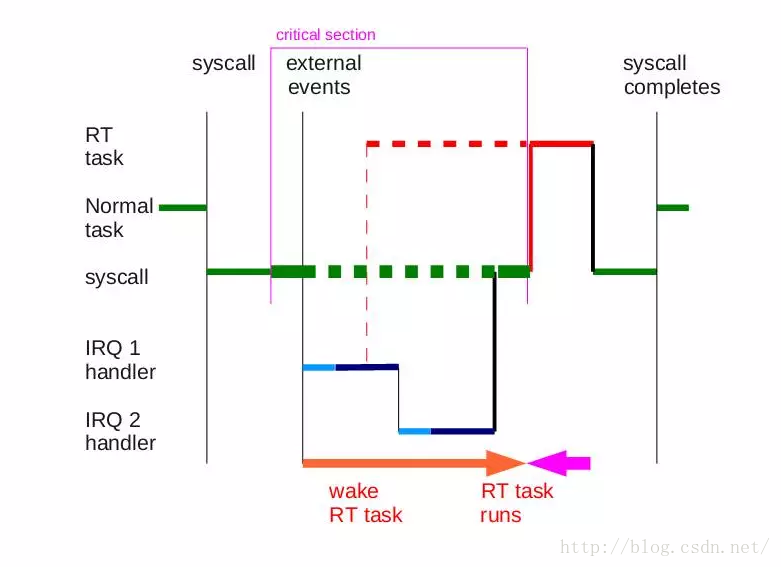 Preemptible Preemptible
|
内核抢占使能时,可检查当前进程是否设置了thread_info中的抢占计数器preempt_count决定是否可以进行抢占。
发生内核抢占的时机是内核函数重新使能内核抢占或者从中断返回内核态,对应实现的函数分别为preempt_schedule和preempt_schedule_irq。
常见场景有:
1. 从中断处理程序返回内核空间时
2. 当kernel code从不可抢占状态变为可抢占状态
3. 显示调用schedule
…
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(!preemptible()))
return;
preempt_schedule_common();
}
static void __sched notrace preempt_schedule_common(void)
{
do {
preempt_disable_notrace(); //__preempt_count_inc
__schedule(true);
preempt_enable_no_resched_notrace(); //__preempt_count_dec
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
} while (need_resched());
}asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
prev_state = exception_enter();
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
exception_exit(prev_state);
}2.1.3 主调度器实现
继续主调度器的实现,实现代码如下,
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
u64 wallclock;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_note_context_switch();
prev = rq->curr;
/*
* do_exit() calls schedule() with preemption disabled as an exception;
* however we must fix that up, otherwise the next task will see an
* inconsistent (higher) preempt count.
*
* It also avoids the below schedule_debug() test from complaining
* about this.
*/
if (unlikely(prev->state == TASK_DEAD))
preempt_enable_no_resched_notrace();
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
lockdep_pin_lock(&rq->lock);
rq->clock_skip_update <<= 1; /* promote REQ to ACT */
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP); //从运行队列中去除当前进程prev
prev->on_rq = 0;
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
if (task_on_rq_queued(prev))
update_rq_clock(rq);
next = pick_next_task(rq, prev); //从运行队列中取出下一进程
wallclock = walt_ktime_clock();
walt_update_task_ravg(prev, rq, PUT_PREV_TASK, wallclock, 0);
walt_update_task_ravg(next, rq, PICK_NEXT_TASK, wallclock, 0);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->clock_skip_update = 0;
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
trace_sched_switch(preempt, prev, next);
rq = context_switch(rq, prev, next); /* unlocks the rq */ //上下文切换
cpu = cpu_of(rq);
} else {
lockdep_unpin_lock(&rq->lock);
raw_spin_unlock_irq(&rq->lock);
}
balance_callback(rq);
}主要步骤为:
1. 从运行队列中去除当前进程prev,实现细节为
deactivate_task(rq, prev, DEQUEUE_SLEEP)
dequeue_task(rq, p, flags); //p是prev代表的task_struct
p->sched_class->dequeue_task(rq, p, flags);
最终通过当前进程prev的调度类sched_class的dequeue_task方法实现。
2. 从运行队列中取出下一进程,实现细节为
pick_next_task(rq, prev);
class->pick_next_task(rq, prev);
调用的是sched_class中的pick_next_task方法实现。
3. 上下文切换context_switch,与体系结构相关。
主要工作在switch_mm和switch_to两个特定于体系结构的函数的实现。
static inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next); //除了一些统计信息外,主要调用prepare_arch_switch,arm中没有定义
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev); //arm中未定义
if (!mm) { //如果next进程为内核线程,其不具有地址空间信息,将借用上一个进程的mm信息
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
if (!prev->mm) { //如果之前进程是内核线程,将active_mm重置为NULL
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
lockdep_unpin_lock(&rq->lock);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
arm 32bit中两个函数实现功能如下:
switch_mm中操作主要为刷新icache和对进程的PGD页表进行切换。
switch_to对寄存器和栈进行切换。将当前进程的通用寄存器,lr和SP保存在进程thread_info的cpu_context中,从下一进程的thread_info中恢复寄存器和栈。
2.2 周期调度器
scheduler_tick主要实现的功能通过curr->sched_class->task_tick和trigger_load_balance实现,在此只介绍下大体功能,会分别在调度器类和SMP调度中进行详述。
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
walt_set_window_start(rq);
update_rq_clock(rq); //更新rq时钟
curr->sched_class->task_tick(rq, curr, 0); //使用rq对应调度器类的task_tick更新时间片信息,可设置进程的重调度标志TIF_NEED_RESCHED
update_cpu_load_active(rq); //更新rq的cpu_load
walt_update_task_ravg(rq->curr, rq, TASK_UPDATE,
walt_ktime_clock(), 0);
calc_global_load_tick(rq);
sched_freq_tick(cpu);
raw_spin_unlock(&rq->lock);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq); //触发SCHEDULE_SOFTIRQ的软中断
#endif
rq_last_tick_reset(rq);
}