最近,导师交给了我们一个任务,让我们核查各个学校提交上来的资料是否正确,我分到的任务就是核查所提交上来的已被收录的论文是否能在相应的期刊搜索的到,以及其他相关信息是否正确。于是,我就想着使用python爬虫帮我自动化完成这些任务。
所使用的网站是:IEEE
网站首页截图是:
我的第一想法就是使用咱们前一篇博客爬取hupu论坛帖子数据的方法,来进行这次的任务。python爬虫爬取虎扑湖人论坛专区帖子数据,并存入MongoDB数据库中
我们来搜索一篇论文,该论文的题目是【Single-Stage Bidirectional Buck–Boost Inverters Using a Single Inductor and Eliminating the Common-Mode Leakage Current】,好,我们将论文题目输入到搜索框中,点击搜索:
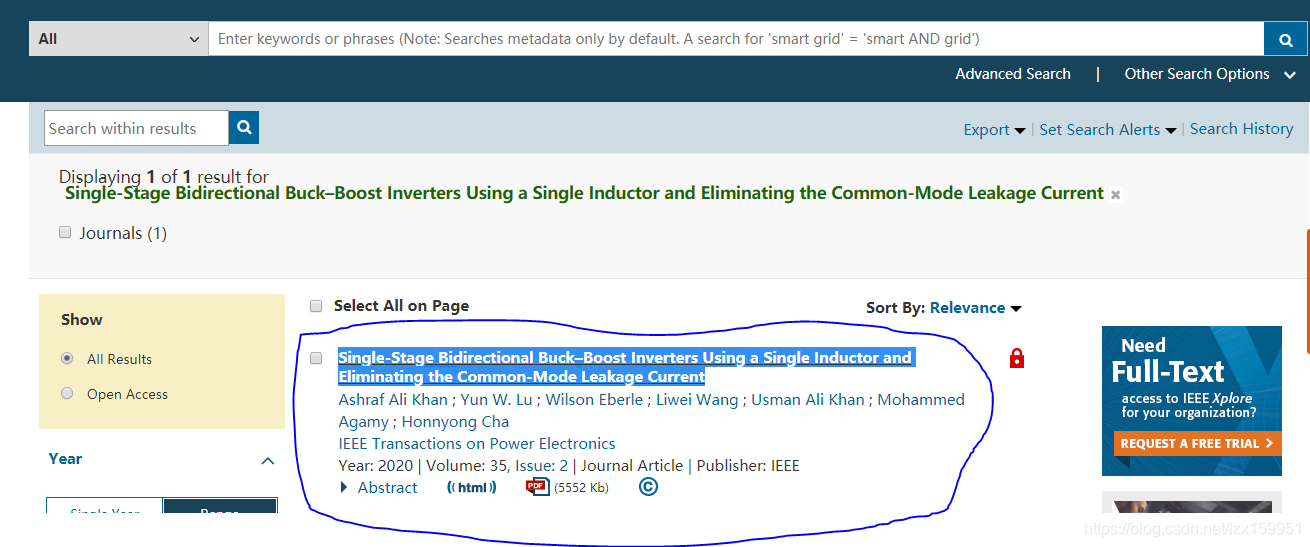
这篇论文就是我们需要的。
这时候,我们发现,此时网址的地址为
https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText=Single-Stage%20Bidirectional%20Buck%E2%80%93Boost%20Inverters%20Using%20a%20Single%20Inductor%20and%20Eliminating%20the%20Common-Mode%20Leakage%20Current
有点长,我们进行拆分
https://ieeexplore.ieee.org/search/searchresult.jsp?
newsearch=true
&queryText=Single-Stage%20Bidirectional%20Buck%E2%80%93Boost%20Inverters%20Using%20a%20Single%20Inductor%20and%20Eliminating%20the%20Common-Mode%20Leakage%20Current
稍微有点网页知识的应该都知道,这是采用了get请求的方式进行数据的提交,newsearch 这个应该是判定是否是新的搜索,后面的值是true ,queryText 后面的值就是咱们所搜索的论文题目了。
太好了,按照咱们以前的开发经验,找到这个规律基本上下面的步骤就没什么难度了。
接下来,咱么看一下这个地址返回值有没有咱们想要的信息。如果有的话,就可以直接写代码获取了。
Skip to Main Content
IEEE.org
IEEE Xplore Digital Library
IEEE-SA
IEEE Spectrum
More Sites
Cart (0)
Create Account
Personal Sign In
Personal Sign In
For IEEE to continue sending you helpful information on our products and services, please consent to our updated Privacy Policy.
I have read and accepted the IEEE Privacy Policy.
Accept & Sign In
Email Address
Email Address
Password
Password
Sign In
Forgot Password?
Institutional Sign In
Browse
Books
Conferences
Courses
Journals & Magazines
Standards
My Settings
Alerts
MyXplore App
Preferences
Purchase History
Search History
What can I access?
Get Help
Contact Us
Resources and Help
Subscribe
IEEE Account
Change Username/Password
Update Address
Purchase Details
Payment Options
Order History
View Purchased Documents
Profile Information
Communications Preferences
Profession and Education
Technical Interests
Need Help?
US & Canada: +1 800 678 4333
Worldwide: +1 732 981 0060
Contact & Support
About IEEE Xplore
Contact Us
Help
Accessibility
Terms of Use
Nondiscrimination Policy
Sitemap
Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity.
© Copyright 2019 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
这些就是这个地址的返回内容,并没有我们需要的。出现这种情况,我猜测,上一张图片我画圈里面的内容是通过js请求加载进来的,我们如果使用正常返回html内容并没有办法获取这些内容。
好了,是时候介绍主角了
selenuim自动化测试工具
如果不知道是什么,请看这个百度百科
如果不知道如何在python使用,请看这个python+selenuim中文教程
为什么要使用这个呢,前面我们也有说到,我们无法通过返回html内容来获取js加载进来的数据,使用这个测试化工具,他就可以将js加载进来的数据渲染到html中,这样,我们返回html 就可以将加载后的内容全部获取到。
好了,直接上代码。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
def load_chrome():
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(1)
return driver
titleset=[]
linkset=[]
titleset.append("A Cooperative Caching Scheme Based on Mobility Prediction in Vehicular Content Centric Networks")
driver = load_chrome()
for i in range(1):
link = "https://ieeexplore.ieee.org/search/searchresult.jsp?newsearch=true&queryText="+str(titleset[i])
driver.get(link)
try:
element = WebDriverWait(driver,10).until(
EC.presence_of_element_located((By.CLASS_NAME,""List-results-items"))
)
except Exception:
pass
result =driver.find_element_by_class_name("List-results-items")
print(result.find_element_by_tag_name("h2").text+"\n"+result.find_element_by_class_name("author").text+"\n"+result.find_element_by_class_name("publisher-info-container").find_element_by_tag_name("span").text+"\n"+result.find_element_by_partial_link_text("Papers").text)
load_chrome() 是配置一下selenium的一些配置,分别启动chrome浏览器,窗口最大化,等待1s加载。其他具体的可以查看上面关于python使用selenium的中文教程链接。
driver.get(link)
这个就相当于我们平常将链接复制到浏览器地址栏,然后回车访问。
try:
element = WebDriverWait(driver,10).until(
EC.presence_of_element_located((By.CLASS_NAME,""List-results-items"))
)
except Exception:
pass
这几行代码我重点说一下,为什么要加几行代码呢,因为在之前的测试发现,浏览器加载网页的速度不一样,导致js数据渲染到html中的时间也不一样,有时候就会出现数据还没有渲染进去,就将html进行了返回,导致返回的html中没有我们需要的数据。
这几行作用就是等待10s,直到元素类名=“col result-item-align”被找到,否则如果超时还没找到的话,就捕捉异常,直接进行接下来的步骤。
这个类名在哪里,我们来看一张图:

就是我们需要的数据这一块,也就是做一个判定,等待这些数据加载出来后,我们再进行之后的数据获取处理操作。
result =driver.find_element_by_class_name("List-results-items")
这一行代码就是获取一个类名=“"List-results-items”这样一个对象,这个同样也是包裹着咱们的数据

最后就是获取咱们需要的数据,获取的原理和BeautifulSoup获取元素的道理很相似。
result.find_element_by_tag_name("h2")
result.find_element_by_class_name("author")
result.find_element_by_class_name("publisher-info-container").find_element_by_tag_name("span")
我们看一下输出结果
A City-Wide Real-Time Traffic Management System: Enabling Crowdsensing in Social Internet of Vehicles
Xiaojie Wang ; Zhaolong Ning ; Xiping Hu ; Edith C.-H. Ngai ; Lei Wang ; Bin Hu ; Ricky Y. K. Kwok
Year: 2018
Papers (23)
我们就获取到我们需要的数据了。
最后我们总结一下:
1.因为使用普通方法无法获取js加载进来的数据,所以使用selenium自动化测试工具。
2.浏览器加载速度不同,需要进行一个显示等待判断,找到某元素或者超时进行下一步。
3.解析数据,具体解析方法文档写的很清楚,看一下就知道了。
