PYTHON大数据分析-IWC赛题1(企业投资价值评估)数据分析方法总结
一、目的
本次比赛主要解决的问题是根据官方提供的37个EXCEL表信息与企业评分,训练出一个模型,使之能够根据对新企业进行评分估计。

表格的数据是这样的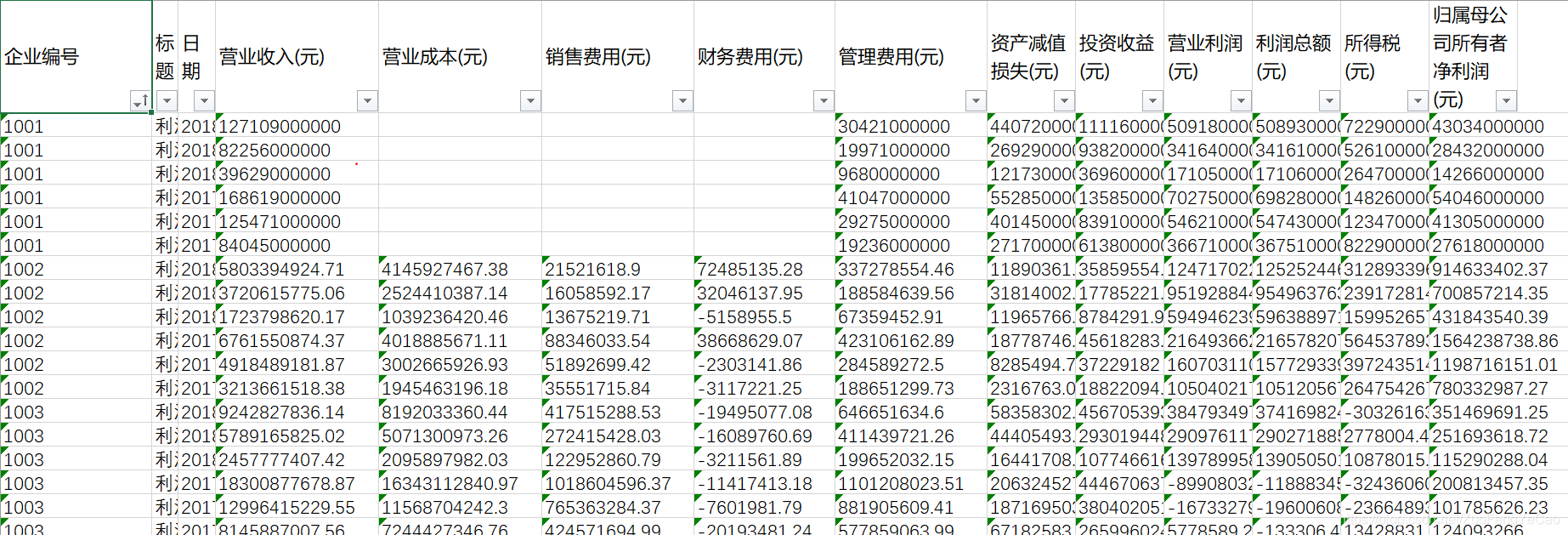
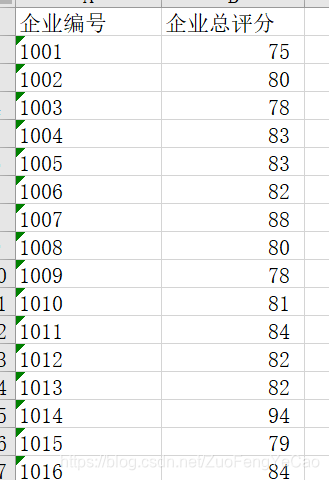
企业评分是这样的
二、代码结构简述
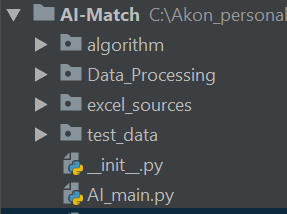
整个工程包括原始数据(excel_sources)、训练数据(test_data)、算法(algorithm)、数据清洗(Data_Processing) 四个部分,如下图:
- Algorithm ,包含目前测试中使用到的算法模型,可通过在main.py中通过train函数注释来选择训练的算法
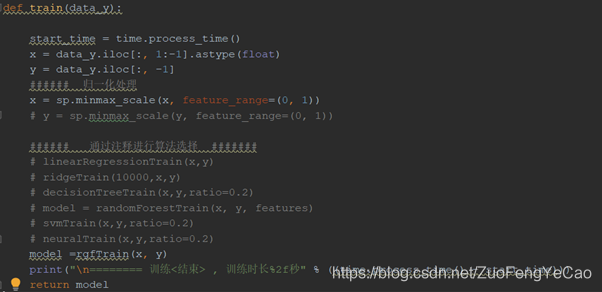
- Data_processing:此次比赛官方提供的37个表中的数据格式不尽相同,为方便数据表格之间处理的独立性,每个表由一个python模块清洗,并提供一个接口函数,可在main.py中调用,最后通过concat函数拼接在一个dataframe变量中,使用注释选择需要选取的表格。
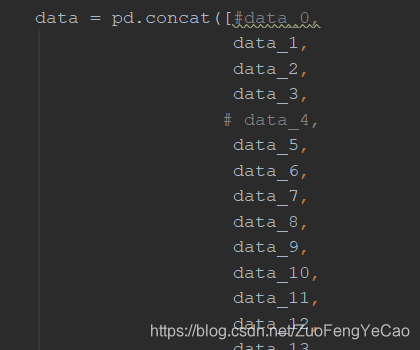
- excel_sources与test_data:分别放置未经处理的训练数据excel文件与 预测数据的excel文件 ,以便工程迁移到其他电脑后直接运行。
三、数据分析过程
大致步骤分为:
数据清洗 -->模型选型 -->参数调优 -->模型校验 -->结果预测
1、数据清洗
数据清洗的作用:
- 把EXCEL表格中的数值、字符、分类列表转化成代码可处理的浮点型或整型格式;
- 去重、补缺、空值替换;
- 生成透视表,行列变换;
- 提取相关特征,去掉无用特征(如时间,标题,),特征变换(如专利名称列表转为专利个数);
- 多行数据整合成一行(如样本提供9个季度的财务报表数据,模型训练就是根据每个样本的多种特征值与结果进行拟合,所以样本的每个属性有且只有一个数值,方法可以取多个季度的均值、和或者最大值)
模块实现架构:
接口函数(模块名)
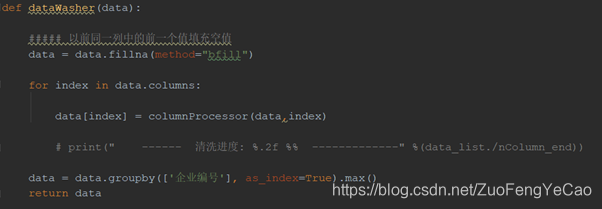
--清洗器(dataWasher)
--列处理器(columnProcessor)
接口函数:EXCEL表读取与保存,重置索引(最后的数据以企业编号为索引)
清洗器:增删属性列,去重补缺,异常值处理,作用是把生成可训练的样本数据
列处理器: 由于每种属性数据格式不同,需要按列进行特殊清洗,作用是生成浮点型或整型数据
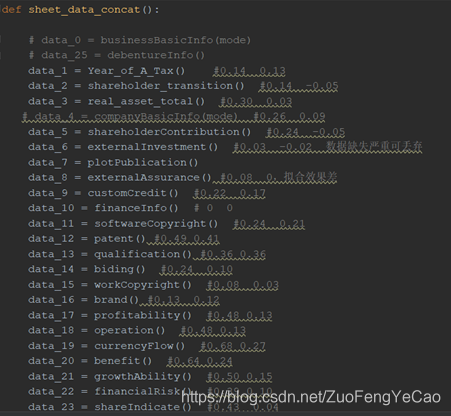
以 《海关信用》表为例,进入customCredit模块后分别看到三个函数:
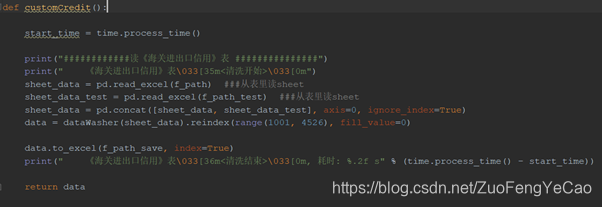
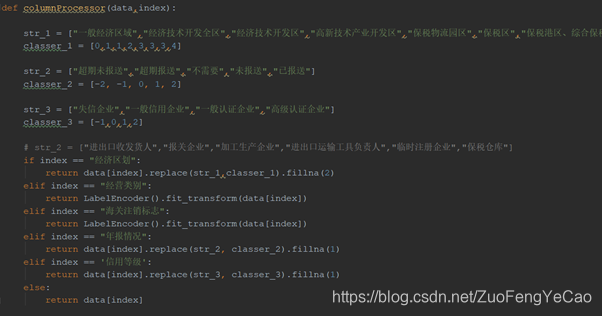
这里主要实现的是按列对属性值作有序编码与无序编码。Sklearn库提供的LabelEncoder编码器能够实现对一列字符型数据进行无序编码,但有些数据是存在重要性或者排名区别,如果也进行无序编码则会毁掉其大小顺序,所以就使用了比较笨的replace方法进行字符替换。
其他表格的处理涉及的方法:
columnProcessor中的处理方法:
- 百分比数据去除“,”,“%”等字符后转为浮点型
- 金额数据去除”万”、“亿”、“万亿”、“万美元”、“万人民币”等单位后转为浮点型数据
- 有序编码、无序编码处理
DataWasher中的处理方法:
- 多行数据折透视表处理、哑变量处理(一列属性转为多列)
- 列运算,特征扩展
- 同一企业多行数据合并处理,数值类取均值,有序数值取最大值
- 异常值处理,通过boxplot把同一属性的数值分布情况显示出来,使用numpy提供的percentile函数对数据比例划线,超过部分当异常值处理,使用上下限数值替换。
- 空值补0、补前值 、补后值、补均值处理,具体依据数据实际含义与拟合结果而定
- 多个表格融合填充缺失值
数据总表中的处理方法:
- 所有表格整合后在train函数中再做归一化处理
- 划分训练数据与预测数据
- 部分算法还使用的正则化处理
2、模型选型
把处理后的数据随机划分为训练集与检验集
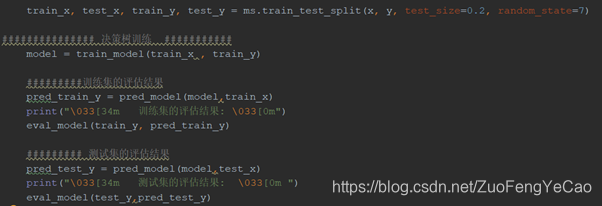
分别使用决策树、增强决策树、正则化贪婪树、随机森林、SVR、神经网络等算法跑出训练集的拟合度与校验集的预测得分(R2S评分),最终结果是随机森林的拟合度最高,正则化贪婪树次之,训练速度上正则化贪婪树占优势。选定随机森林做为最终算法。
由于是初学者对算法模型没有直观感受,只能用此笨方法啦。哈哈哈。。。
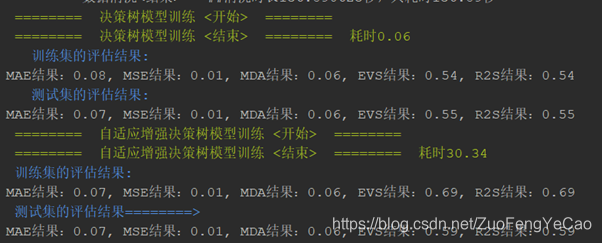
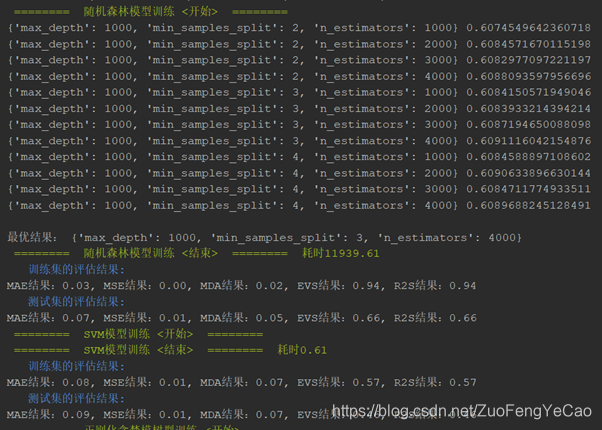
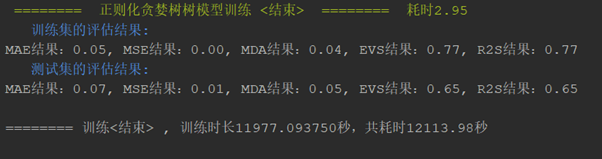
3、参数调优
基本上每个模型中都会有超参数,超参数的选取需要根据模型拟合的结果一点一点的调整。这里使用GridSearchCV网格搜索选择器来进行超参数选择。其工作原理是根据提供的参数选择逐一代进算法模型并计算出拟合结果,返回最优的参数值。


4、模型校验
最终的模型使用全数据进行训练,使用交叉验证方法评估模型准确度

5、结果预测
预测的数据在数据清洗阶段已经完成处理,把数据通过返回的训练好的模型进行预测,评分结果使用四舍五入转化为整数后保存
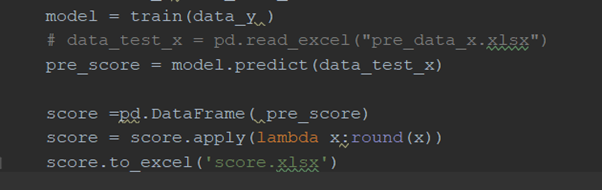
四、比赛心得
1、 正如文中的篇幅所示,80%的精力是在进行数据清洗。而且赛方提供的数据来源格式混杂,部分数据缺失严重,异常值多,数据值相差大,部分数值让人怀疑人生,如付税的结果为负值,注册资本万亿以上,增长1000%以上等等不符合现实逻辑现象。
2、 算法的选择影响更多的体现在处理速度与时间上,拟合的效果差距不会太大,正如那句话所说的算法是决定了模型准确性的下限,数据预处理才是决定了模型准确性的上限。
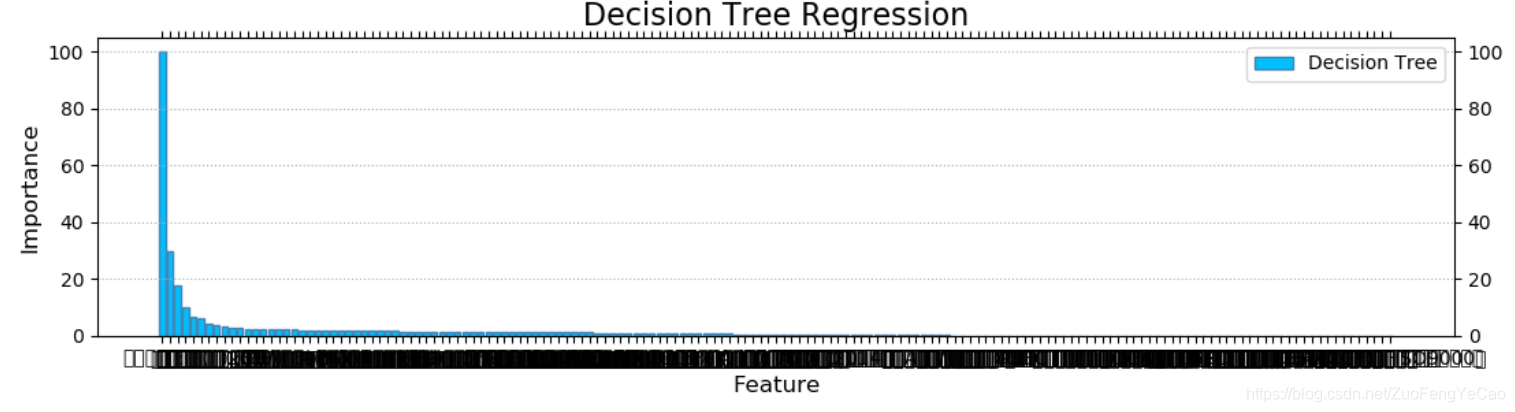
3、 通过随机森林的特征值排名可以得到前十个最重要的特征:‘发明专利数量’, ‘软件著作权数量’, ‘经营类别’,
‘外观设计’, ‘销售费用(元)’, ‘实用新型数量’, ‘存货周转天数(天)’, ‘毛利率(%)’, ‘商标数量’, ‘实际税率(%)’,按常理分析,一个企业的评分更多的应该是依赖财务报表数据,反而专利的数据贡献度更高不合逻辑。各特征的贡献度比例大致如下