一.线程不安全的HashMap
多线程环境下,使用HashMap进行put操作会引起死循环(jdk1.7 Entry链表形成环形数据结构),导致CPU利用率接近100%。
结构:数组 table[]+链表entry<k,v>
put 对key做hash
默认初始化数组长度 16
加载因子 0.75
扩容 大于16*0.75时
rehash
hash冲突:链表解决。原来的entry移出去,后来的进来,然后next指向原来的entry
线程不安全:多个线程扩容时闭环,引起死循环。
为什么会形成闭环:
线程1 A>B>C
线程2 B>A倒置。会变成A>B>A
解决:
1.8 红黑树:数组+链表+红黑树。阈值:8
hashmap扩容过程:
传入新的容量
初始化新的Entry数组,将数据转移到新的Entry数组里(遍历旧数组,取得每个元素,释放旧数组的引用,重新计算位置)
table属性引用新的entry数组
修改阈值
hash算法:取key的hashcode值,高位运算,取模运算
put 对key做hash
默认初始化数组长度 16
加载因子 0.75
扩容 大于16*0.75时
rehash
hash冲突:链表解决。原来的entry移出去,后来的进来,然后next指向原来的entry
线程不安全:多个线程扩容时闭环,引起死循环。
为什么会形成闭环:
线程1 A>B>C
线程2 B>A倒置。会变成A>B>A
解决:
1.8 红黑树:数组+链表+红黑树。阈值:8
hashmap扩容过程:
传入新的容量
初始化新的Entry数组,将数据转移到新的Entry数组里(遍历旧数组,取得每个元素,释放旧数组的引用,重新计算位置)
table属性引用新的entry数组
修改阈值
hash算法:取key的hashcode值,高位运算,取模运算
1.8的优化
1.resize时不需要重新计算hash,只要看看原来的hash新增的那个bit是0还是1。0的话索引没变,1的话索引变成原索引加oldcap。找到新数组下标,确定索引位置,增加随机性。
2.不会形成闭环,扩容时不再使用头插法改成尾插法。
1.resize时不需要重新计算hash,只要看看原来的hash新增的那个bit是0还是1。0的话索引没变,1的话索引变成原索引加oldcap。找到新数组下标,确定索引位置,增加随机性。
2.不会形成闭环,扩容时不再使用头插法改成尾插法。
二.效率低下的HashTable
多个线程访问HashTable的同步方法,会引起阻塞或轮询状态。
三.ConcurrentHashMap
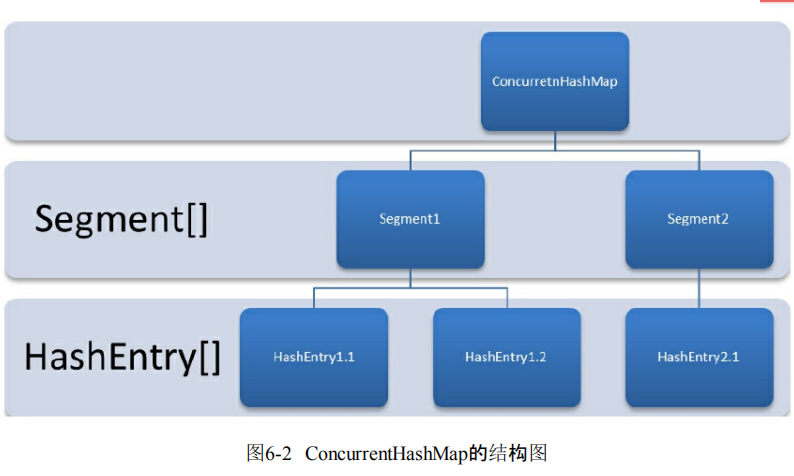
jdk1.7 锁分段技术
数据分段存储,每段配一把锁,当一个线程访问其中一段时,其他线程也可访问其他段。
结构:Segment数组,每个数组下面维护HashEntry链表(存键值对)