面试的时候经常会问到的问题?这三个之间有什么区别.
Hashtable是遗留类,现在基本上不使用,其内部都是通过关键字synchronized来实现线程安全,所以Hashtable是HashMap的线程安全版本,可以这样说.因为加了锁,使得效率变低.
ConcurrentHashMap
ConcurrentHashMap是JDK1.5引入的Concurrent包中类,这个包的主代码由多线程大师Doug Lea编写,ConcurrentHashMap现在已经基本取代了Hashtable,因为它在保证线程安全的前提大,大大提高并发环境下的处理能力,ConcurrentHashMap采用分段锁的概念,在ConcurrentHashMap的内部有一个类叫Segment,它类似于HashTable,继承于ReentrantLock以达到线程安全的目的.



ConcurrentHashMap不同于Hashtable在于分段锁消除不同分段锁之间的竞争,只有锁内部存在竞争.而Hashtable是在整个Map上添加同步.ConcurrentHashMap默认Segment的个数是16,当对象要存入集合内时,首先通过对象的键计算HashCode值来找到对应的Segment,然后将对象添加到对应的Segment之中,相对于Hashtable的效率提高了16倍.
HashMap
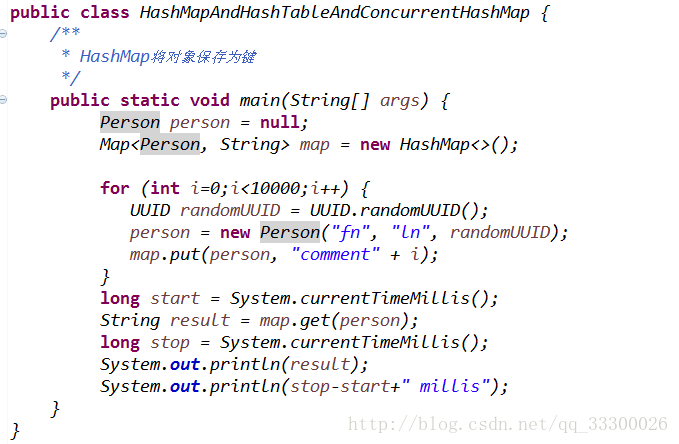
HashMap是我们使用得最多的集合,就通过一个代码实例来说吧!使用对象的形式做为HashMap的键.


结果:

结论:
HashMap可以存放键值对,如果要以对象(自己创建的类等)作为键,实际上是以对象的散列值(以hashCode方法计算得到)
作为键。hashCode计算的hash值默认是对象的地址值。这样就会忽略对象的内容,不是以对象的内容来判断。如果要以对象
的内容进行判断,就要覆盖掉对象原有的hashCode方法。另外HashMap是以equals方法判断当前的键是否与表中存在的键
是否相同,所以覆盖hashCode方法之后,还不能正常运行。还要覆盖equals方法先判断hash(hash函数)值是否相同,相
同了说明某个位置上有多个元素,再用equals(线性查找)方法判断。这里上次面试回来仍然搞错了,因为我记得HashMap
的键要实现Compareable接口,其实是我记错了,JDK1.7HashMap的数据结构如下:
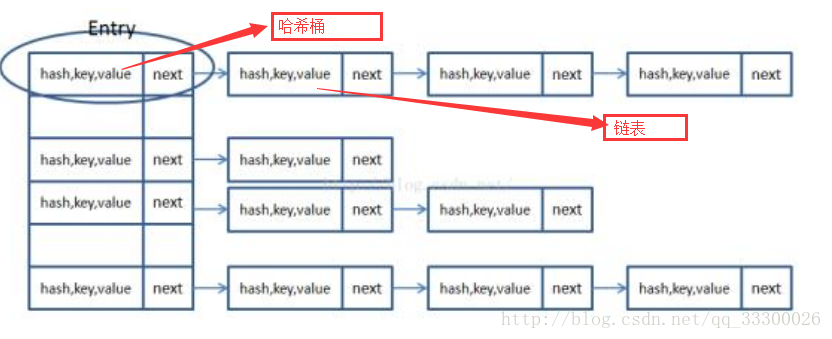
这也纠正了好久以来一个错误的认知,HashMap的键必须实现Compareable接口,因为它的键是一个Set集合,值是List集合,我一
定是记错了,记成TreeMap和TreeSet,数据结构树必须实现Compareable接口.
JDK1.8HashMap的数据结构如下:

JDK1.8HashMap的底层实现可以参考:
http://www.th7.cn/Program/java/201607/892575.shtml
JDK1.8HashMap与Compareable接口的那点事可以参考:
http://blog.csdn.net/zly9923218/article/details/51656920