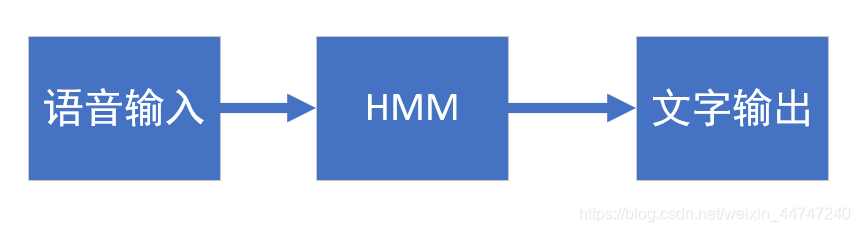
识别过程是隐马尔可夫模型HMM进行的
HTK说到底就是建立隐马尔可夫模型HMM过程中的工具,过程如下: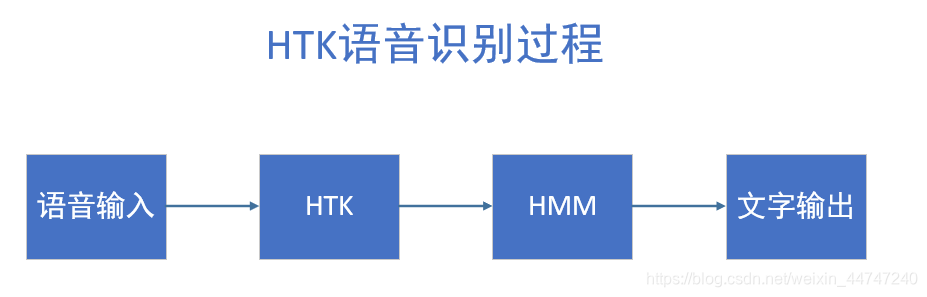 M的工具,如下图:
M的工具,如下图:
文件目录树构建
构建一个目录框架,创建命令如下:
mkdir -p htk_color/{config,data/{test/{mfc,speech},train/{mfc,speech}},dict,hmm0,hmm1,hmm2,hmm3,hmm4,hmm5,hmm6,hmm7,labels,lists,results,scripts}查看命令及结果:
tree -d htk_color
构建完成后,以后的命令都是在此文件夹下运行终端。
语音数据采集
Linux下安装音频录放工具sox,命令如下:
sudo apt-get install sox安装完成后,运行命令进行录音:
rec -b 8 data/train/speech/01.wavCtrl+c结束录音,依次输入命令进行语音数据采集即可
通过以下命令播放录音结果:
play data/train/speech/01.wav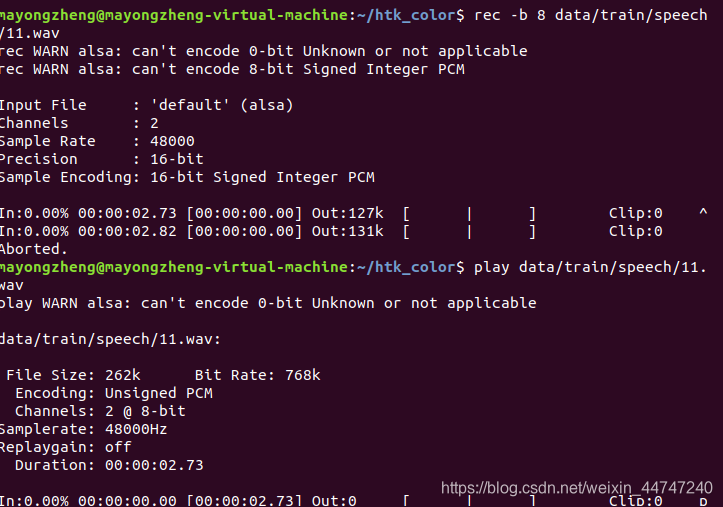
收集数据的过程,是一个十分折磨人的工作,语音文件的收集更是难办,搭建一个效果好的语音模型,你不仅需要一个人的语音,你还需要其他人的语音,过程很艰巨,慢慢体会,比图像的收集要麻烦多,但是用数量很少的样本,也可以训练出相对准确的结果。
接下来我用了十个录音文件进行了尝试,到此数据集的准备已经完成,下一节完成训练过程的配置。
