DNN的模型参数{W,b}需要通过每个任务的训练样本S={o,y}来训练得到。这个过程即训练过程或者参数估计过程,需要一个给定的训练准则和学习算法,也即需要定义一个损失函数。实际训练中交叉熵准则应用最多。
模型参数的训练应该最小化期望损失函数。
交叉熵训练准则能独立地处理每一帧语音向量,而语音识别本质上是一个序列分类问题。序列鉴别性训练方法,常用的有MMI,BMMI,MPE,MBR。
- 均方误差准则MSE
对于回归任务,MSE(mean square error)准则经常被使用:
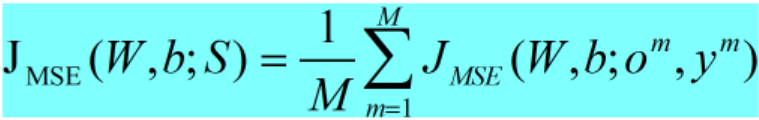
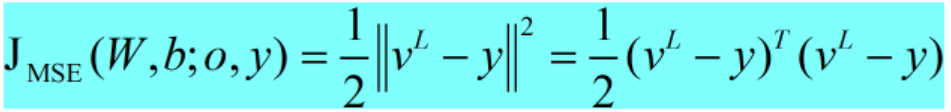
- 交叉熵准则CE
对分类任务来说,设y是一个概率分布,则CE(cross entropy)准则经常被使用:
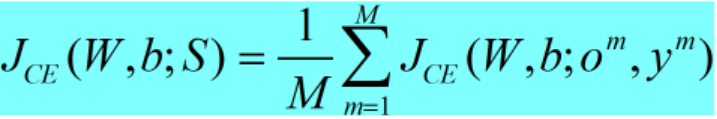
其中:
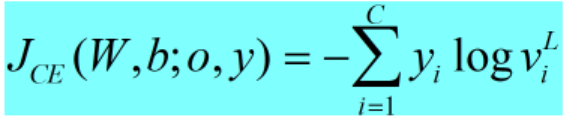
yi=Pexp(i|o)是观察特征o属于类i的经验概率分布(从训练数据的标注中来),viL=Pdnn(i|o)是采用DNN估计的概率。最小化交叉熵准则等价于最小化经验分布和DNN估计分布的KL距离。
3. 对数似然准则ML
在大部分情况下,CE准则退化为负的对数似然准则(negative log-likelihood,NLL):
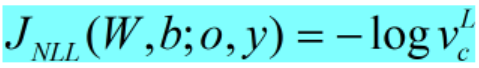
4. 序列鉴别性训练准则
在逐帧训练中,使用CE准则来最小化期望帧错误;序列鉴别性训练则希望能更好地利用大词汇连续语音识别中的最大后验准则(maximum a posteriori,MAP),这可以通过建模处理隐马尔科夫的序列(即序列)限制、字典和语言模型(language modek)限制来实现。
5. 最大互信息准则MMI

MMI(maximum mutual information,最大化互信息准则)旨在最大化单词序列分布和观察序列分布的互信息,定义Om和Wm分别是第m个音频样本的观察序列和正确的单词序列标注,对一个训练集S来说,MMI准则为:
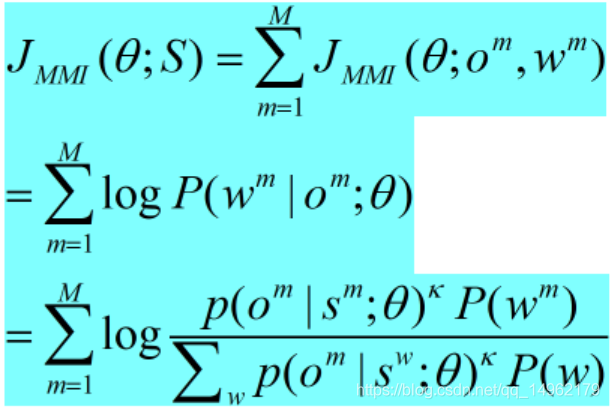
其中,theta是模型参数,包括DNN的转移矩阵和偏移系数(biases),sm是wm的状态序列,kappa是声学缩放系数,求和运算是限制在解码得到的词图(lattice)上做的,这样可以减少运算量。
6. 增强型最大互信息准则BMMI
7. 最小因素错误准则MPE
8. 最小贝叶斯风险训练准则MBR