写在前面:我写博客主要是为了对知识点的总结、回顾和思考,把每篇博客写得通俗易懂是我的原则,因为能让别人看懂,才是真的学会了
从Math到CS的跨专业经历,让我格外珍惜学习时间,更加虚心好学,而分享技术和知识是快乐的,非常欢迎大家和我一起交流学习,期待与您的进一步交流
笔记开始于2020年2月4日 星期二
一. 线性表基本概念
线性表是具有相同特性数据元素的一个序列
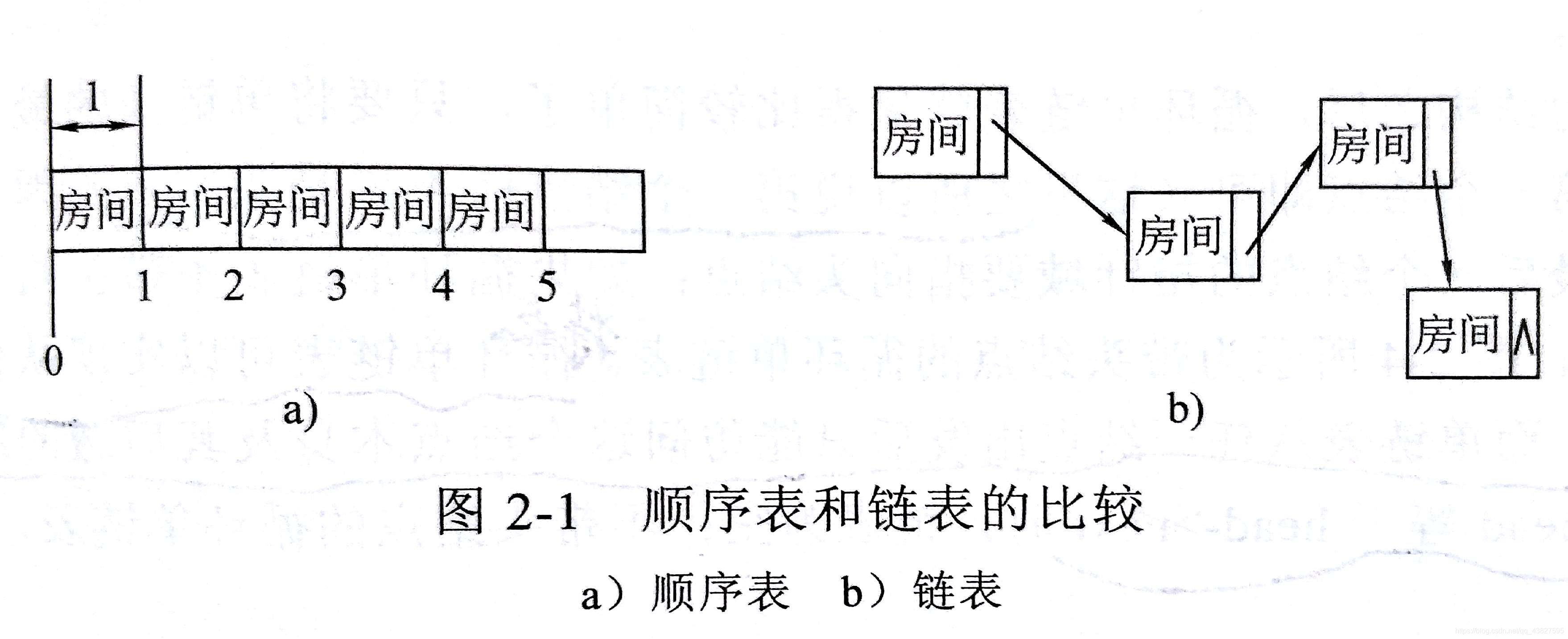
线性表的存储结构有顺序存储结构(顺序表)和链式存储结构(链表)两种
1)顺序表和链表的区别
- 顺序表的存储密度是1,链表的存储密度<1(因为有指针域)
- 顺序表的储存空间是一次性分配的,链表的存储空间是多次分配的
2)链表的几点说明
(单)链表的常见画法

几点说明:
- 单链表L:说明该链表的头指针是L
- 带头结点的单链表的第一个元素是头结点
- 循环链表是没有NULL空指针的
- 循环链表和非循环链表的内存空间是相同的,只不过最后指针,一个指向开头,一个是空指针
- 箭头是从内到外的

二. 链表的5种形式
1)单链表
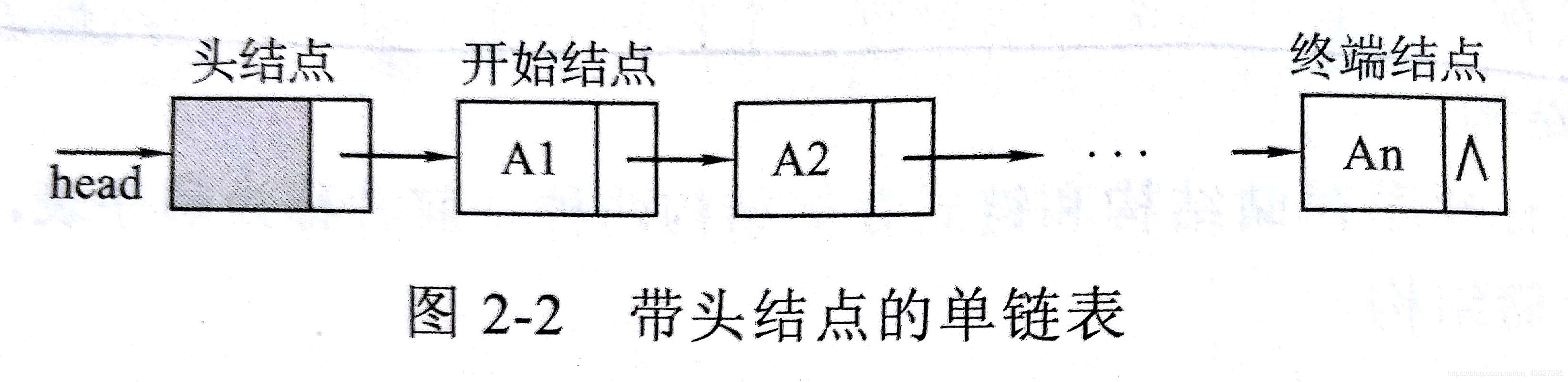
- 带头结点的单链表(第一个元素是头结点):头指针head指向头结点(头结点的值域不包含任何信息)
头指针head始终不等于NULL,当head->next = NULL时,链表为空 - 不带头结点的单链表:头指针直接指向开始结点
head=NULL时,链表为空
注意区分头结点和头指针,头指针head永远都指向链表的一个结点的,而头结点只有带头结点的链表才有的
2)双链表
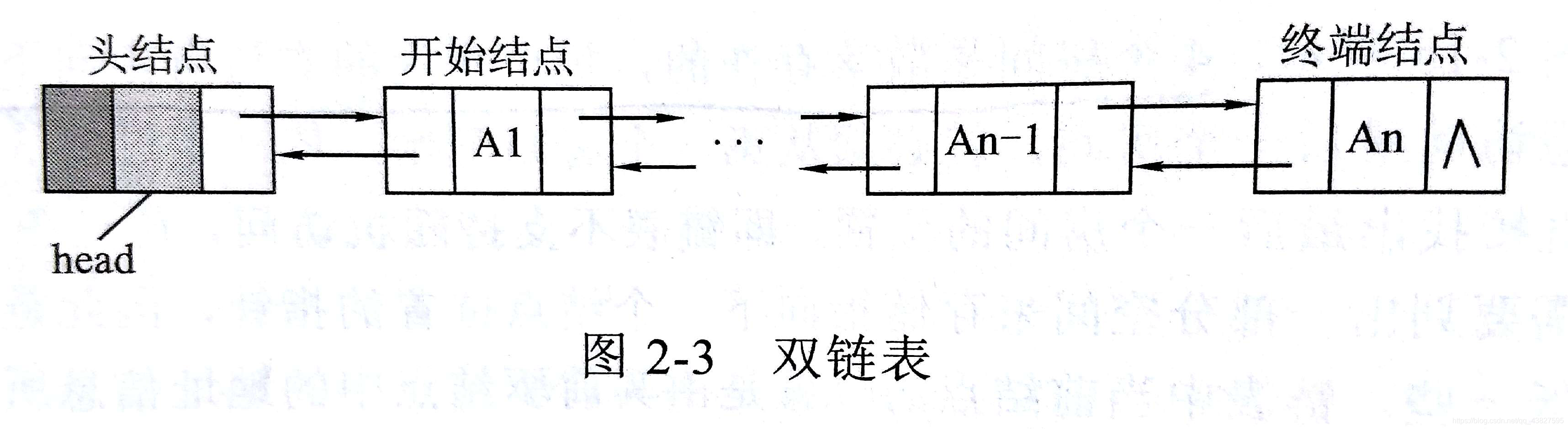
构造双链表可以解决问题:输出从终端结点到开始结点的数据序列
双链表就是在单链表的基础上添加一个指针域
- 带头结点的双链表,当head->next = NULL时,链表为空
- 不带头结点的双链表,当head = NULL时,链表为空
3)循环单链表
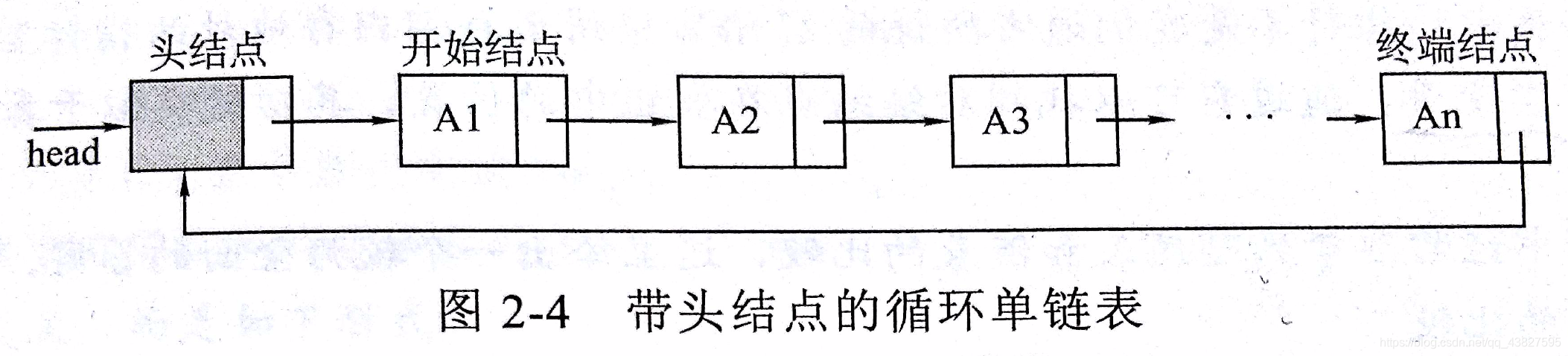
循环单链表只要将单链表的最后一个指针域(空指针)指向链表中的第一个结点(头结点或开始结点)
循环单链表特点:可以实现从任何一个结点出发访问链表中的任何结点
- 带头结点的循环单链表,head->next = head时,链表为空
- 不带头结点的循环单链表,head = NULL时,链表为空
4)循环双链表
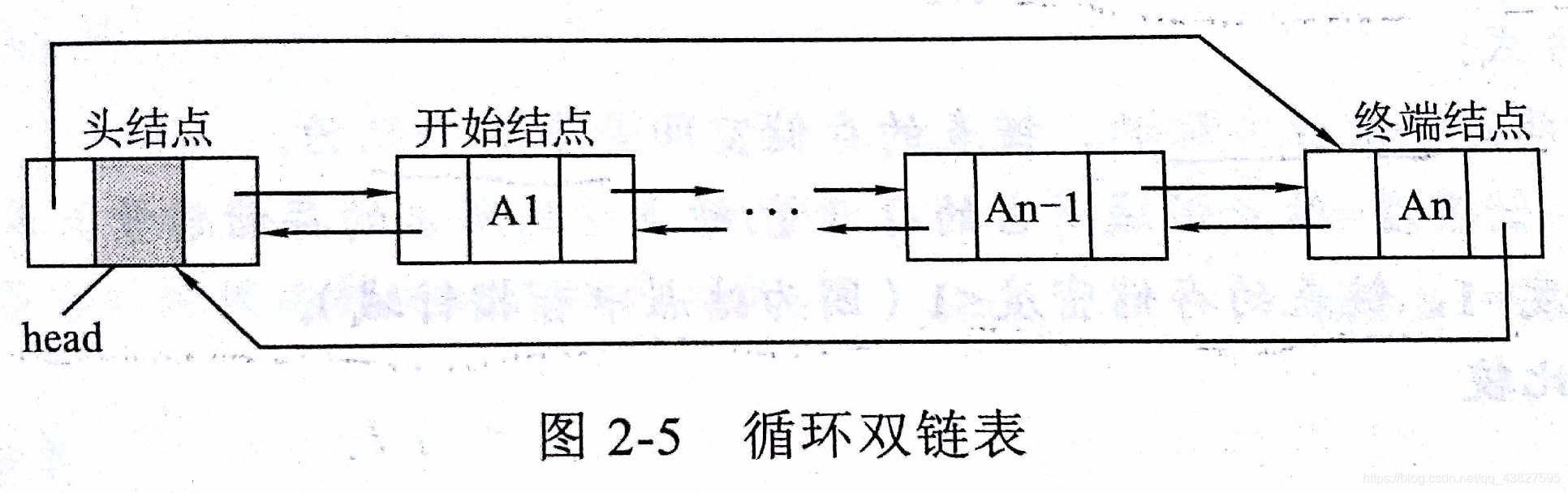
定义:终端结点的next指针指向第一个结点(头结点或开始结点),第一个结点的prior结点指向终端结点
- 带头结点的循环双链表,head->next = head或head->prior = head时,链表为空
- 不带头结点的循环双链表,head = NULL时,链表为空
5)静态链表
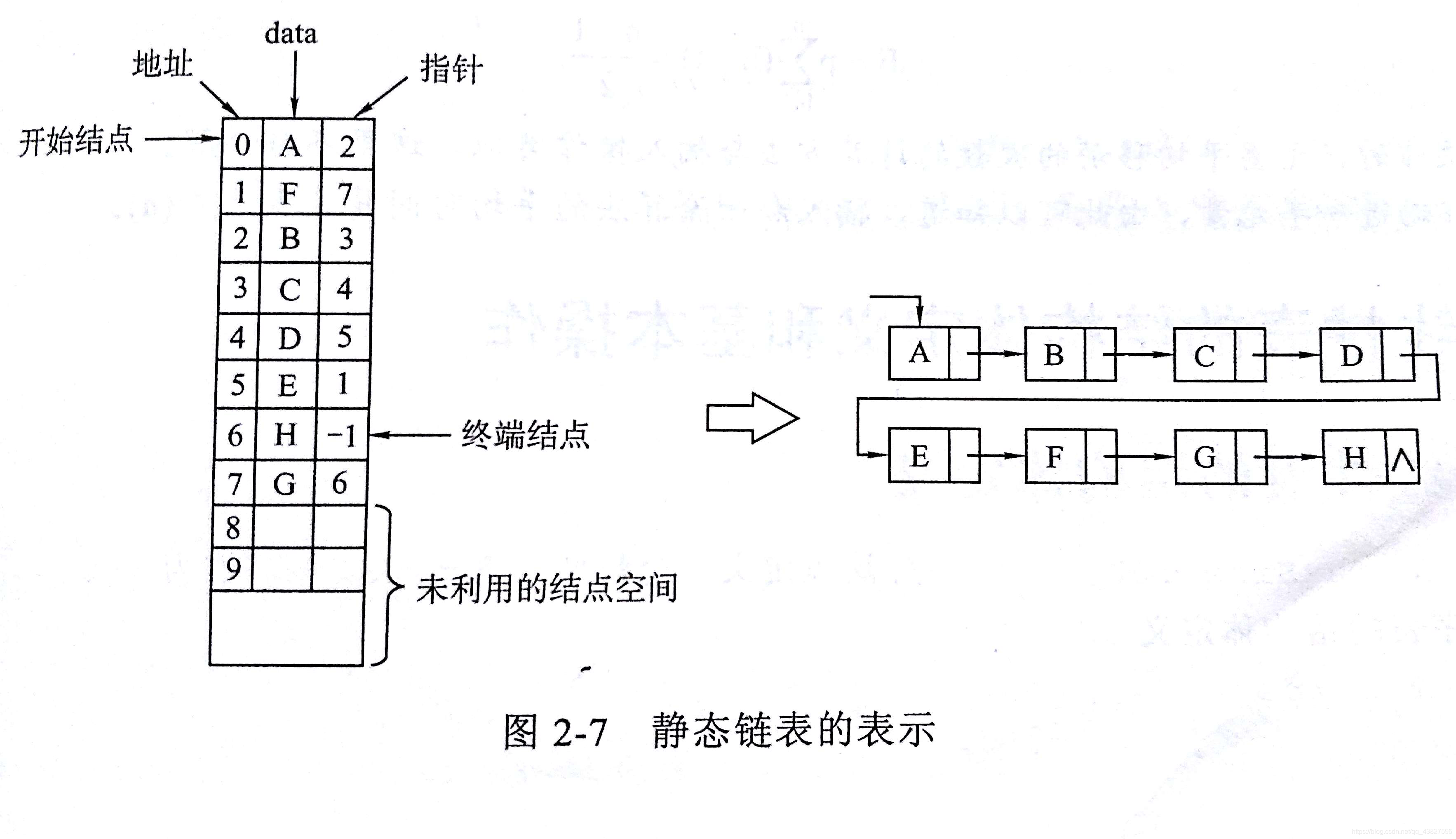
一般链表结点空间来自于整个内存,静态链表则来自于一个结构体数组
三. 线性表的结构体定义
1)单链表结点的定义
typedef struct LNode{
int data; // 数据域
struct LNode *next; // 指向后继结点的指针
}LNode; // LNode类似于int,表示单链表结点类型
2)双链表结点的定义
typedef struct DLNode{
int data; // 数据域
struct DLNode *prior; // 指向前驱结点的指针
struct DLNode *next; // 指向后继结点的指针
}LNode; // DLNode类似于int,表示双链表结点类型
3)动态分配malloc或new
// malloc
LNode *A = (LNode *)malloc(sizeof(LNode));
// new
// 创建一个LNode内存空间,并让B指向这个空间
LNode *B = new LNode; // 编译器定义隐式默认构造函数
示例:
struct ListNode {
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {} // 初始化列表法
};
ListNode* p;
p = new ListNode(-1); // 构造函数
// 初始化一个头结点为-1的链表(因为初始化列表法,所以-1可以这样初始化)
4)指针p和结点p的说明
LNode *A = (LNode *)malloc(sizeof(LNode));
用户分配了一片LNode型空间,并让A指向这个结点,同时我们也把A当做这个结点的名字
注意:A可能有两种意思:指针A,结点A(根据具体情况分析)
例如:“p指向q”,则p是指针,q是结点”,“用函数free()释放p的空间”,因为指针是会自动释放的,所以这里的p指的是结点p
5)结构体指针的定义方法
下面是一种特殊写法,知道有这种写法就行了
// 结构体指针的定义方法
typedef struct STU *linklist;
linklist head; // head是一个指向结构体STU的指针
等价于
struct STU *head;
本质:struct STU * 简写为linklist,类似pair<int, int> 简写为PII
四. 链表基本操作
1)创建一个单链表(尾插法)
Create a single linked list 1->2->3->4->NULL(尾插法)
#include <iostream>
using namespace std;
struct ListNode {
int data;
ListNode *next;
ListNode(int x): data(x), next(NULL) {}
};
int main() {
// Create a single linked list 1->2->3->4->NULL 1->2->3->4->NULL
ListNode *head = new ListNode(-1);
ListNode *a = head;
for (int i = 1; i <= 4; i ++) {
ListNode *b = new ListNode(i);
// 尾插法
a->next = b;
a = b;
}
a->next = NULL;
// 遍历输出链表
ListNode *p = head->next;
while(p != NULL) {
printf("%d ", p->data);
p = p->next;
}
puts("");
return 0;
}
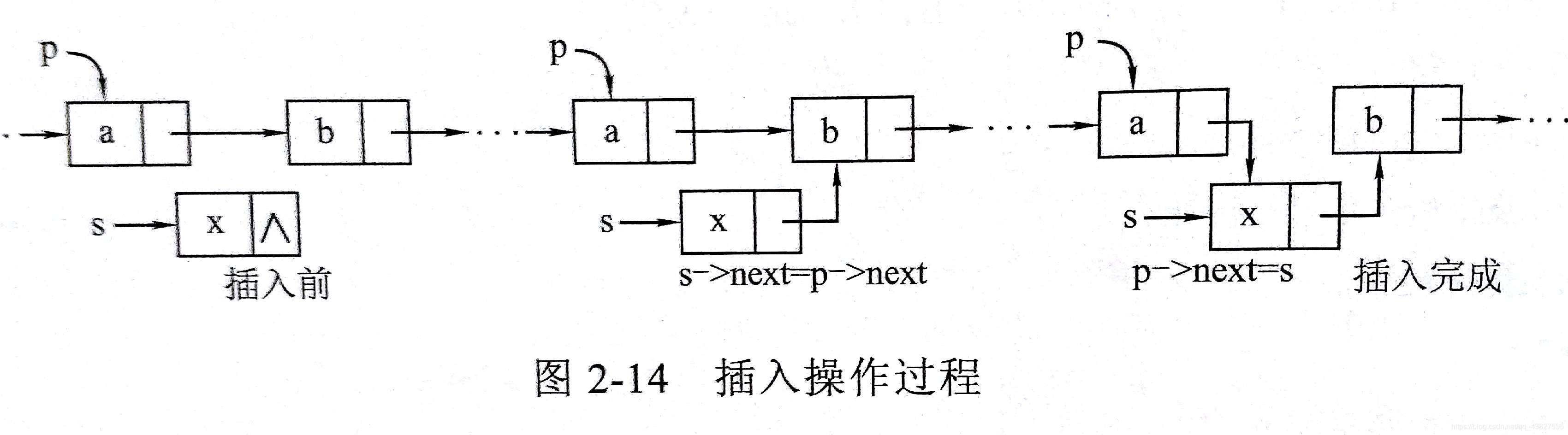
2)单链表结点插入操作(先连后断)
假设p指向一个结点,要讲s所指的结点插入p所指结点之后
其语句如下
s->next = p->next;
p->next = s;
例:两个有序递增链表合并成一个递减链表(头插法)
一般常用的插入方法有:尾插法和头插法。这里使用头插法

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
auto End = new ListNode(-1);
auto p = End->next; // p == NULL
while(l1 && l2) {
if (l1->val <= l2->val) {
// 头插法
auto tmp = l1->next;
l1->next = p;
p = l1;
l1 = tmp;
} else {
auto tmp = l2->next;
l2->next = p;
p = l2;
l2 = tmp;
}
}
while(l1) {
auto tmp = l1->next;
l1->next = p;
p = l1;
l1 = tmp;
}
while(l2) {
auto tmp = l2->next;
l2->next = p;
p = l2;
l2 = tmp;
}
return p;
}
};
3)单链表结点删除操作(先找到前驱结点)
删除第 个结点,必须先找到它前一个结点第 个结点,再其后继结点
假设 为指向 的之后怎,则只需将 的 指向原来 的下一个结点的下一个结点即可
p->next = p->next->next;
更加规范的写法(释放堆空间)
q = p->next;
p->next = p->next->next;
delete q;

例:判断链表中是否存在值为x的结点,若存在则删除该结点
// When it comes to deleting, it is best to use a linked list with leading nodes
int findAndDelete(ListNode *head, int x) {
auto p = head;
// Delete: find the precursor node first
while(p->next != NULL) {
if (p->next->data == x) break;
p = p->next;
}
if (p->next == NULL) return 0; // No x found
else {
// delete x
auto q = p->next;
p->next = p->next->next;
delete q;
return 1;
}
}
4)创建一个双链表(尾插法)
Create a double linked list 1->2->3->4->NULL
#include <iostream>
using namespace std;
struct ListNode {
int data;
ListNode *prior;
ListNode *next;
ListNode(int x): data(x), next(NULL) {}
};
int main() {
// create a double linked list 1->2->3->4->NULL
ListNode *head = new ListNode(-1);
ListNode *a = head;
for (int i = 1; i <= 4; i ++) {
ListNode *b = new ListNode(i);
// 尾插法
a->next = b;
b->prior = a; // The only difference with single list
a = b;
}
a->next = NULL;
// 顺序遍历链表
ListNode *p = head->next;
while(p->next != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("%d ", p->data);
puts("");
// 输出1 2 3 4
// 逆序遍历链表
while(p != head) {
printf("%d ", p->data);
p = p->prior;
}
puts("");
// 输出 4 3 2 1
return 0;
}
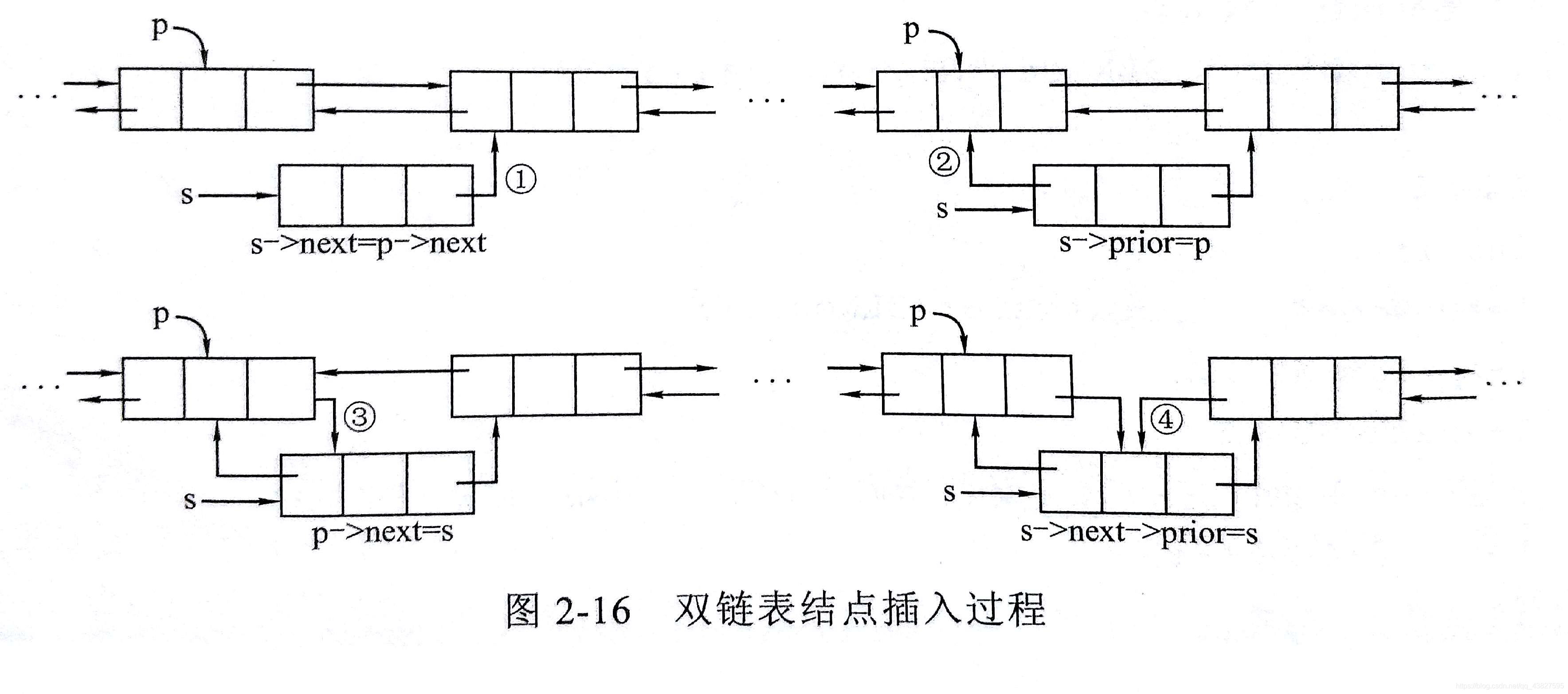
5)双链表结点的插入操作(先连后断)
假设在双链表p所指的结点后插入一个结点s,其语句如下:
s->next = p->next; // 连
s->prior = p; // 连
p->next = s; // 断
s->next->prior = s; // 断
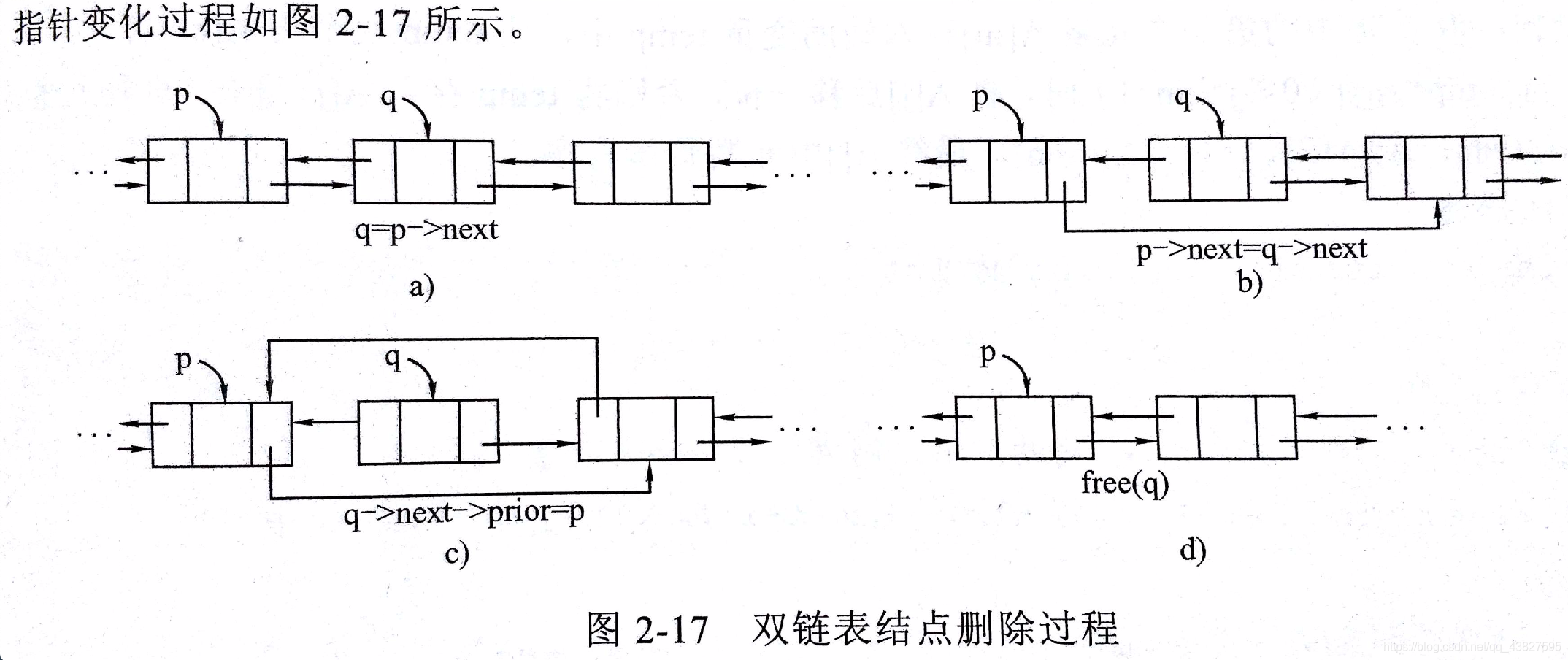
6)双链表结点的删除操作
设删除双链表中p结点的后继结点,其语句如下:
q = p->next;
p->next = q->next; // 核心
q->next->prior = p; // 核心
delete q;
注意:双链表删除结点不一定要找到前驱结点,因为有prior指针