opencv版本是2.4.10,不同版本的haartraining,名称可能不一样,比如2.4.9的可能叫cascade.exe等,请对号入座。首先找到exe文件,如下:
F:\opencv\build\x64\vc12\bin\opencv_haartraining.exe
因为下面正样本描述文件需要的是特征向量描述文件,所以还需要另外一个程序来生成,也在同目录下:
F:\opencv\build\x64\vc12\bin\opencv_createsamples.exe
可以将这两个程序文件拷贝到训练的目录下备用,如:
1.正样本和负样本
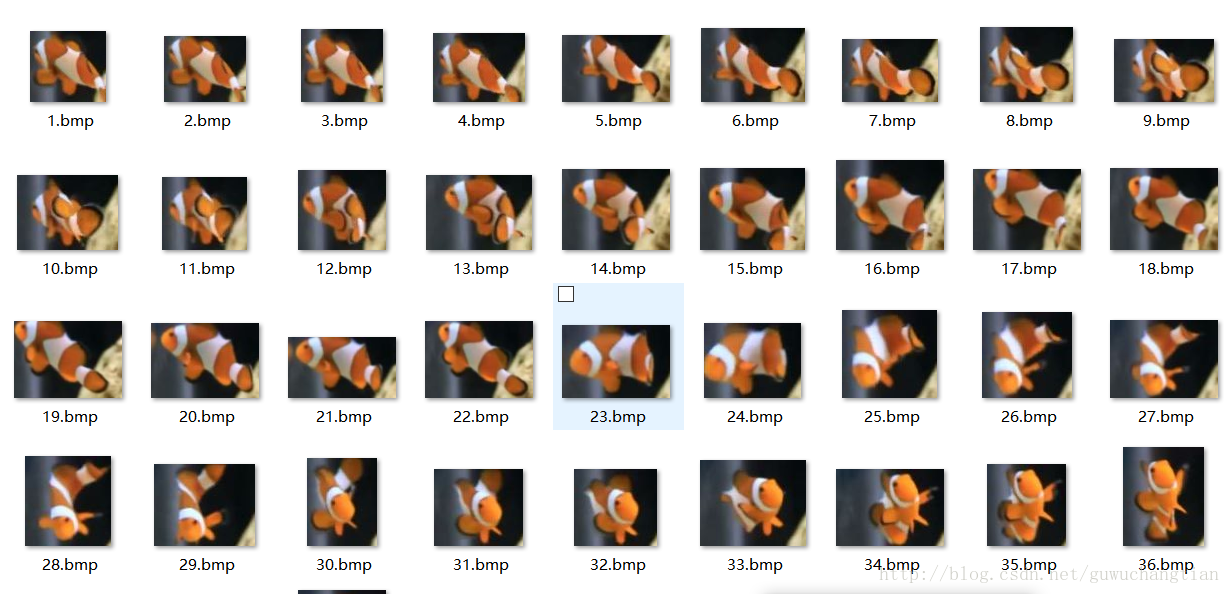
正样本就是你要识别的那个东西的图片,告诉分类器什么是正确的分类,也就是告诉程序你要识别的什么,我要做的是nemo鱼的识别,所以就是nemo鱼的图片了,如下:
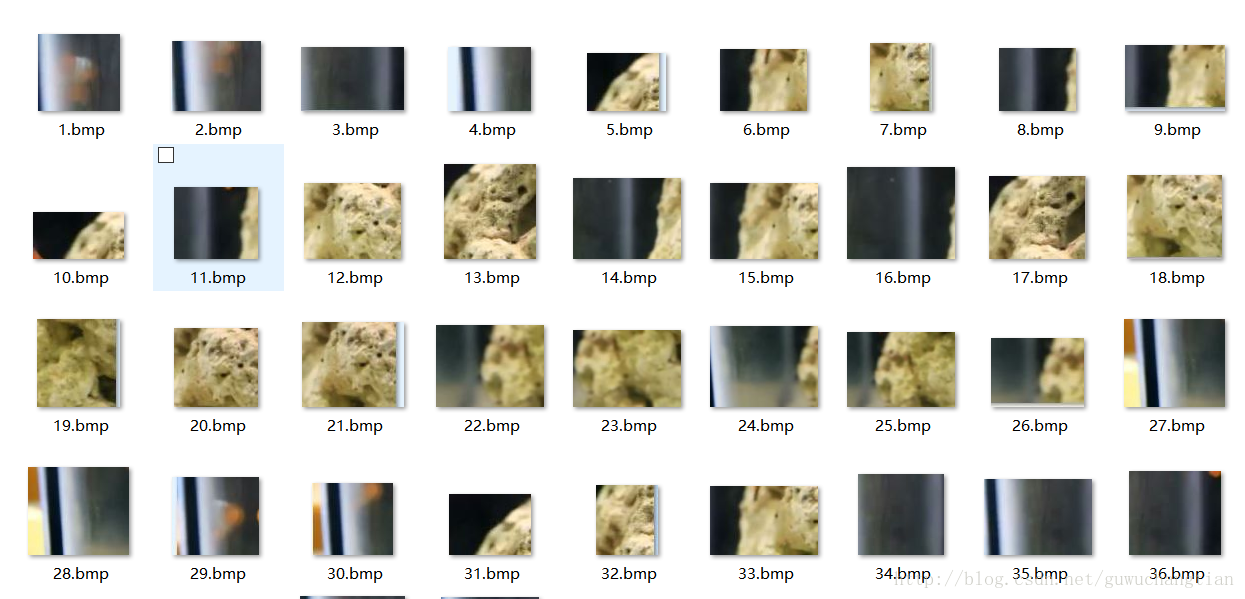
负样本是区别于正样本的图片,告诉分类器什么是错误的分类,也及时告诉程序不能识别什么,我是直接将视频的背景截了一些图片,如下:
正负样本图片的数目越多越好了,越多速度越快,识别越准确。可以先到网上中找找有没有你需要的样本库,像人脸识别,车辆识别都有现成的样本库,有的练分类器都有,直接用就行。如果没有那只有自己使用截图工具截了,截图时尽量保持宽高比,因为训练时程序会进行归一化,保存为bmp格式,截完之后使用图片格式转换工具。正负样本图片以数字命名后分别放到positive和negative目录下。
2.正样本描述文件
首先需要一个过渡描述文件,包含每张图片的图片路径、数目、图片位置信息。如:
路径 图片数目 左上点坐标 宽 高
positive/1.bmp 1 0 0 30 30
positive/2.bmp 1 0 0 30 30
positive/3.bmp 1 0 0 30 30
positive/4.bmp 1 0 0 30 30
positive/5.bmp 1 0 0 30 30
positive/6.bmp 1 0 0 30 30
positive/7.bmp 1 0 0 30 30
positive/8.bmp 1 0 0 30 30
positive/9.bmp 1 0 0 30 30
positive/10.bmp 1 0 0 30 30
positive/11.bmp 1 0 0 30 30
positive/12.bmp 1 0 0 30 30
positive/13.bmp 1 0 0 30 30
positive/14.bmp 1 0 0 30 30
positive/15.bmp 1 0 0 30 30
positive/16.bmp 1 0 0 30 30
positive/17.bmp 1 0 0 30 30
positive/18.bmp 1 0 0 30 30
positive/19.bmp 1 0 0 30 30
positive/20.bmp 1 0 0 30 30
positive/21.bmp 1 0 0 30 30
positive/22.bmp 1 0 0 30 30
…….
可以使用dos,在正样本目录下使用dir /b>pos.txt命令来生成文件名,然后再将bmp替换为“bmp 1 0 0 20 20”,不过这样生成的只有文件名,没有路径,你就必须在样本目录下进行训练,如果你需要加入路径,只能手动天剑或者去了解一下shell脚本,写一个简单脚本来自动完成。
还有一个简单的解决办法是写一个简单的c++程序来生成:
#include <iostream>
#include <string>
#include <fstream>
#define STR "positive/"
using namespace std;
int main(int argc, const char** argv){
fstream f("./src/training_data/pos.txt",ios::out);
string str;
int i = 1;
while (1){
str = STR + to_string(i)+".bmp 1 0 0 30 30";
cout << str << endl;
f << str << endl;
i++;
if (i == 201)//我的正样本数目是200,有点少,手动截的orz
break;
}
return 0;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
过渡文件生成之后,拷贝到之前放opencv自带的那个软件的目录下,开始生成特征向量文件,在目录下按住shift+鼠标右键,选择在此处打开命令窗口,输入命令运行:
opencv_createsamples.exe -info pos.txt -vec pos.vec -num 200 -w 30 -h 30
此时在同目录下应该生成了一个pos.vec文件。
3.负样本描述文件
负样本描述文件要简单的多,只需要文件路径就行了,如下:
negative/1.bmp
negative/2.bmp
negative/3.bmp
negative/4.bmp
negative/5.bmp
negative/6.bmp
negative/7.bmp
negative/8.bmp
negative/9.bmp
negative/10.bmp
negative/11.bmp
negative/12.bmp
……
可以使用之前的方法生成,此时你的文件应该都齐了,如下:

4.训练
使用之前的方法打开命令窗口,输入如下命令:
opencv_haartraining.exe -data cascade -vec pos.vec -bg neg.txt -sym -npos 200 -nneg 120 -mem 2000 -mode ALL -w 30 -h 30
完结~
=========================================================
错误分析:
首先正样本与负样本的比例最好是1;2到1:3之间
其次在用haar做训练的时候出现的那个npos还有nneg参数的时候,后面的数字最好注意一下,npos的值取全体正样本的三分之一,比如我有400个样本我取了120,这样训练的时候就不会出现下面这个错误了。
Opencv Error: Assertion failed (elements_read==1) in icvGetHaarTraininData From vecCall Back, file....../......../......./opencv/apps/haartraining/cvhaartraining.cpp.line 1859
英文网站上的回答大概是这么个意思,也就是在第一层训练的时候已经用完了vec文件中所有的正样本,以至于在后续的样本训练中没有新的正样本可以加入使用了,导致出现了错误的现象。
那个vec文件中的正样本数目=npos+(nstages-1)*(1-minHitRate)*npos+s
S的意思是指在正样本中能够直接识别成背景的样本个数,如果npos=120的话,s的取值为个位数就行,不用太大。

