项目实施情况(包括取得成果描述)及项目作品描述:
最下方附有检测代码和项目训练下载以及正负样本下载(附带在百度网盘中)
- 此项目是想要对去年一度很火热的声控游戏进行拓展玩法,增加了人脸识别功能,并且此功能所使用的分类器为自己进行训练的,此次训练主分为数据采集,分类器训练,和运用训练好的分类器进行人脸检测并归一化保存,为以后测试所用,此次介绍主要为对训练过程进行叙述
- 主要是haar特征提取+adaboost算法,adaboost算法简单理解就是迭代训练,训练完一个弱分类器之后,去除不正确的样本,保存正确的样本训练结果继续反复训练保存,直至样本利用率达到完全生成强分类器,haar特征提取则是通过特征提取公式在10几种模式中进行特征提取。
样本采集:
- 在训练前,我们需要进行正样本和负样本的采集,正样本在这里本来选用了ORL人脸库进行训练,共40*10,400张,但是最后的结果并不太好,猜测可能是训练样本数目太少的原因,所以在此训练时候,增添了另一组人脸库,正样本共计18000张左右,部分截图如下:

- 其中训练时候出现了内存不足的警告,所以经过py脚本修改,将所有的人脸按照百分百比例进行了缩放,修改成了20*20,代码如下:
- 负样本在这里部分选用weizmann团队的图片样本,并进行了灰度化,方便对比
- http://www.wisdom.weizmann.ac.il/~vision/Seg_Evaluation_DB/dl.html (网站允许爬取)
- 因为样本稀缺的原因放入了其他的负样本进行填补,这里选择了中科院放出来的训练样本,共计11000多张,部分截图如下:
- 进行完数据采集后,
将采集到的数据分批放置,在这里我将正样本数据放在了pos_img文件中,将负样本放在了neg_img中,并建立了一个xml文件(其中会放置有训练过程中产生的弱分类器),再将所有的弱分类器训练完成之后,会根据每个弱分类器的权重生成最终的强分类器,也就是xml.xml 分类器(与建立的xml文件名字一致) - 接下来需要进行的则是opencv所提供的两份工具(类似于tf中封装用来训练的优化器等函数),所用版本为opencv-2-4-11,在进行完opencv的环境配置后,在其主目录下进行如下跳转build->x64,找到需要的文件,opencv_createsample.exe和opencv_haartraining.exe,
简单介绍下两个工具的作用:
-
Opencv_creaatesamples.exe是用来创建样本描述的,创建生成的文件后缀名为.vec,专门为opencv训练准备,只需要对正样本进行创建
-
Open_haartraining.exe里面封装了haar特征的提取(小波提取,特征黑白提取公式,具体不再这里累述,适用于所有训练的特征,人脸,人眼,人耳等),以及adaboos算法的训练过程。
-
在进行多次小批量的训练测试后,发现正负样本比例为1:2.67左右的训练结果较好,在这里采取1:3的比例。这个比例不是绝对的,但理论上说,负样本的多样性越大越好,这样的话我们可以有效的降低误检率,而不仅仅是通过正样本的训练让其能够识别物体,在最后训练的时候,我选取了2700个正样本和9000个负样本,且均已转换成灰度图像
-
在样本准备好之后,打开windows下的cmd窗口,cd到指定目录下,生成所需要的txt
图像目录文件,代码如下(neg_img和pos_img的操作一致):
C:\Users\wz>cd Desktop
C:\Users\wz\Desktop>cd pos_img
C:\Users\wz\Desktop\pos_img>dir /b >pos.txt
- 打开pos.txt,并且删除pos.txt这一行,并将jpg 修改为jpg 1 0 0 20 20
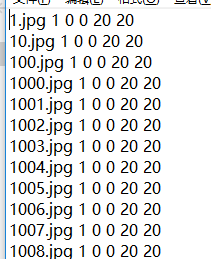
在这里面,1代表该图片只会出现一次,0 0 20 20 表示该图片大小是矩形框从(0,0)到(20,20), - 同样的,在neg.txt里面删除neg.txt这一行,其余不做改动
- 做完之前的操作之后将txt文件拷贝出来,两个exe封装工具也拷贝出来,类似于下图:

- 之后就可以进入cmd’使用openve_createsamples.exe进行创建vec样本描述文件了
- 根据其的帮助文件:
[-info <collection_file_name>] //目标图片描述文件,下属命令中为pos.txt
[-img <image_file_name>]
[-vec <vec_file_name>] //指令生成的文件,在下述命令中生成的为pos.vec
[-bg <background_file_name>] //背景图片描述文件,为neg.txt
[-num <number_of_samples = 1000>] //产生的正样本数量
[-bgcolor <background_color = 0>]
[-inv] [-randinv] [-bgthresh <background_color_threshold = 80>]
[-maxidev <max_intensity_deviation = 40>]
[-maxxangle <max_x_rotation_angle = 1.100000>]
[-maxyangle <max_y_rotation_angle = 1.100000>]
[-maxzangle <max_z_rotation_angle = 0.500000>]
[-show [<scale = 4.000000>]]
[-w <sample_width = 24>] //输出的样本宽度20
[-h <sample_height = 24>] //输出的样本高度20
[-pngoutput]
- 使用以下命令创建一个包含2700样本的样本描述文件pos.vec :
opencv_createsamples.exe -vec pos.vec -info pos_img\pos.txt -bg neg_img\neg.txt -w 20 -h 20 -num 2700
- 同样cmd,在所放目录使用openc_haartraining.exe ,查看其的帮助如下:
-data <dir_name> //指定存放训练好的分类器的路径名字,在这里为之前在当前目录下建立的xml文件
-vec <vec_file_name> //正样本的文件名(pos.vec)
-bg <background_file_name> //背景描述文件
[-bg-vecfile]
[-npos <number_of_positive_samples = 2000>] //正样本数目2700个
[-nneg <number_of_negative_samples = 2000>] //负样本数目9000个
[-nstages <number_of_stages = 14>] //训练层数
[-nsplits <number_of_splits = 1>] //分裂节点数目为2
[-mem <memory_in_MB = 200>]
[-sym (default)] [-nonsym]
[-minhitrate <min_hit_rate = 0.995000>]
[-maxfalsealarm <max_false_alarm_rate = 0.500000>]
[-weighttrimming <weight_trimming = 0.950000>]
[-eqw]
[-mode <BASIC (default) | CORE | ALL>] //级联器的类型,all表示所有类型
[-w <sample_width = 24>] //样本宽度
[-h <sample_height = 24>] //样本高度
[-bt <DAB | RAB | LB | GAB (default)>]
[-err <misclass (default) | gini | entropy>]
[-maxtreesplits <max_number_of_splits_in_tree_cascade = 0>]
[-minpos <min_number_of_positive_samples_per_cluster = 500>]
- 使用命令:
opencv_haartraining.exe -vec pos.vec -bg neg_img\neg.txt -data xml -w 20 -h 20 -men 2048 -npos 2700 -nneg 9800 -nstages 9 -mode all
- 之后就是等待训练结束了,训练部分截图如下:
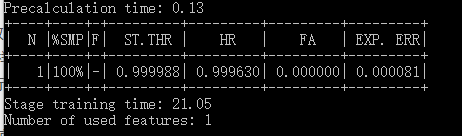
参数意思分别为:
N 对应训练的层数
%SMP 提供样本的使用率
ST.THR 分类器的阈值(这里是极大值)
HR 当前分类器对正样本识别正确的概率
FA 当前分类器对负样本识别错误的概率
EXP.ERR 分类器的期望错误率(基于所提供的样本)
- 最终最终分类器为如下,及每层的弱分类器如下:

- 因为环境配置问题(这是后来跑的9层,识错率还有待调整),在作品里面使用的是去年跑的16层识别器
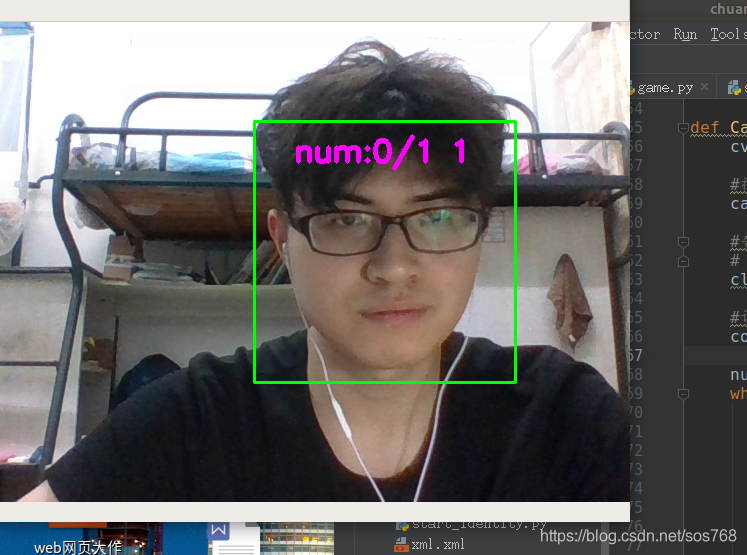
- 整体运行如下:

项目存在的不足或欠缺,尚需深入研究的问题:
-
这方面其实有很多,第一就是原先想要加入的方向键控制,在cocos2d里面可能因为疏漏只找到了任意键盘响应,更多的实现实在cocos3d-x中,这一方面是需要后续改进的
-
还有的方面,比如在识别训练上,haar+adaboost的分类训练虽然是很经典,不过其也有很多缺憾,不够灵活,不过从一个方面看稳定也是他的优点
-
至于后续,还想研究的就是真正的换脸技术了,dlib的后续模型训练,下一步我想要进行的是将角色的头像进行完美拼接,像下面这样:


------------------------------------------------ 合成------------------------------------------------------

-
实现最简单的当然是调用shape_68特征点进行替换,并且通过转换进行脸模覆盖
-
所以下一步,比较想要研究的就是进行完美替换人脸了。
附录:
测试代码:
# -*- coding: utf-8 -*-
# import 进openCV的库
import cv2
import sys
import dlib
import cv2
import os
import glob
import numpy as np
import os.path
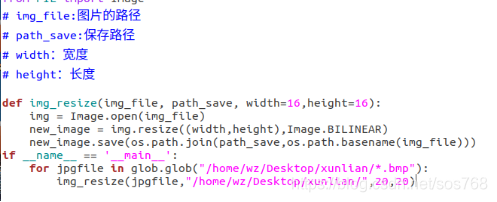
from PIL import Image
# img_file:图片的路径
# path_save:保存路径
# width:宽度
# height:长度
def img_resize(img_file, path_save, width=16,height=16):
img = Image.open(img_file)
new_image = img.resize((width,height),Image.BILINEAR)
new_image.save(os.path.join(path_save,os.path.basename(img_file)))
#调用电脑摄像头检测人脸并截图
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):
cv2.namedWindow(window_name)
#视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx)
#告诉OpenCV使用人脸识别分类器
classfier = cv2.CascadeClassifier('xml.xml')
#识别出人脸后要画的边框的颜色,RGB格式, color是一个不可增删的数组
color = (0, 255, 0)
num = 0
while cap.isOpened():
ok, frame = cap.read() #读取一帧数据
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #将当前桢图像转换成灰度图像
#人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.01, minNeighbors = 3, minSize = (212, 212))
if len(faceRects) > 0: #大于0则检测到人脸
for faceRect in faceRects: #单独框出每一张人脸
x, y, w, h = faceRect
#画出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
#显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame,'num:%d/1 %d' % (num,len(faceRects)),(x + 30, y + 30), font, 1, (255,0,255),4)
#超过指定最大保存数量结束程序
# if num > (catch_pic_num): break
#显示图像
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
#释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
# 连续截100张图像,存进image文件夹中
# CatchPICFromVideo("get face", 0, 2, "C:\\Users\\Administrator\\Desktop\\face_recognition\\faces")
CatchPICFromVideo("get_face", 0, 100, "/home/wz/Desktop/chuangke/simple/")
for jpgfile in glob.glob("/home/wz/Desktop/chuangke/simple/*.jpg"):
img_resize(jpgfile,"/home/wz/Desktop/chuangke/simple/",96,96)
参考blogs:
- https://blog.csdn.net/wanty_chen/article/details/79949258
- https://blog.csdn.net/u014365862/article/details/52997019
- https://www.cnblogs.com/chensheng-zhou/p/5542887.html //训练常见问题
链接:
-
链接: https://pan.baidu.com/s/1ZsBxTdfka0YH2X-gBZSUfA 提取码: 4dx2 //opencv2-4-11版本的exe安装包
-
链接: https://pan.baidu.com/s/1qP9zR6AUw4xohYriDsvVNw 提取码: inxt //训练所用到的数据data和文件都分享在这里了
-
若有问题,请评论在博客下方,博主有时间会看的~