今天起床时,发现这篇关于GCN的文章讲的不错,通俗易懂,为了更一步加深对GCN的理解,所以特此把它整理在图神经网络专栏中(编不下去了,其实是今天不想继续学习,就简单整理一些东西吧,至少良心不会痛。我发誓以后一定要早睡早起,哭唧唧......)。
傅里叶变换是论文中采用的比较正统的思路(谱域)。不过这些视角对于新人来说可能没那么好理解,空域(不进行傅里叶变换,直接利用相邻节点求卷积)角度的说明可能更符合 CV 同学的视角。这里从空域的角度推导谱域的结论,不知道同学们会不会有一种万法归一的感觉୧( ⁼̴̶̤̀ω⁼̴̶̤́ )૭ 。阳光下没有新鲜事,但是,换个角度看总会看到不一样的景象
目录
1. 鸟瞰图卷积
图卷积的核心思想是利用『边的信息』对『节点信息』进行『聚合』从而生成新的『节点表示』。有的研究在此基础上利用『节点表示』生成『边表示』或是『图表示』完成自己的任务。
矩阵式聚合:在早期的研究中,由于没有什么并行库支持聚合节点信息,而图的规模往往很大。学术大佬们主要利用邻接矩阵的变换来完成这种聚合,然后使用 Pytorch 和 Tensorflow 这类库为矩阵运算加速。为了证明变换的有效性和合理性,很多工作借鉴了信号处理的思路,进行图上的傅里叶变换。
消息式聚合:随着图卷积越来越火,工业界逐渐加入了基础设施建设的队伍。借鉴 GraphX 等思路,出现一些不依赖邻接矩阵(或是屏蔽了邻接矩阵细节的)的消息聚合库,比较有名的有 PyG(比较早,实现多)和 DGL(比较新,易上手)。在这些库中,节点可以发出信息,并接受周围节点的信息,显式地完成消息聚合。在这种情况下,越来越多复杂的聚合方法出现了。
2. 罗马是六天建成的
这里从简单到复杂讲解几种我们常用的图卷积公式(有时候简单的效果也不错)。在开始前先说明几个符号的含义:
N = 1,2,3,...,n代表所有节点的编号
X代表所有节点的特征矩阵,其中表示节点i的特征
A代表邻接矩阵,其中表示节点i和节点j之间的边的权重(无权图 ij之间有边是1,无边是0)
注意:通常我们讨论的图都是简单图,没有自环,即
- 平均法
以前,有一句很有名的鸡汤 『你朋友圈的平均工资就是你的工资』。算是日常生活中的一个规律吧:利用社交网络(graph)中的关联信息(edge),我们可以得到其他的有效信息(node represent)。
如果把『我』看成当前节点,『我的朋友』看做『我』的相邻节点,要估算『我的工资』该怎么做呢?

鸡汤告诉我们,当前节点可以用相邻节点推断出来。我们先考虑用相邻节点的加和来代表当前节点(平均数只需要对加和的系数归一化就行了,后面再完善):

如果是无权图,。在
时,
。既然不相邻节点(无边相连)的系数
总为0,加上他们也不会对结果产生任何影响,上式可以写成:

我们可以将其写成矩阵运算(矩阵式聚合):

- 加权平均法
平均法有一个小问题:它没有考虑到『我们与朋友的亲密度是不同的』。比如,我们都认识马化腾,但是张志东与马化腾的亲密度要比我们和马化腾的亲密度高得多。因此,可以预测张志东的工资比我们更接近马化腾。
严谨来说,上式忽略了边的权重。我们只需要把无权图(为0或1)变为有权图(
可以为任何数)。有很多工作都是在研究如何更巧妙的构建有权图(比如用节点间的相似度等等)。
我们仍可以用上式表达加权平均:
- 添加自环
加权平均法也一个小问题:它没有考虑到『你可能很会吹牛逼』。比如,虽然我们能力和朋友们差不多,但是我们很会吹牛逼所以特别受到领导赏识(误)被提拔的很快。这时,可以预测我们的工资会比我们的朋友要高。
严谨来说,上式忽略了节点自身的特征。因此一般我们会通过添加一个自环把节点自身特征加回来:

从化简后的公式可以看到,通过 A+I操作,已经将节点本身的特征加回来了。
- 另一种思路
有一些任务对工资的绝对值不感兴趣。比如,『检测凤凰男防止相亲采坑』的任务。凤凰男可能会因为某些机遇工资飙升,但是他的朋友圈工资水平仍然不高,从而产生较大的贫富差距。而对于富二代而言,他们的朋友圈通常也是富二代,贫富差距较小。
严谨来说,有些任务可能更关注相邻节点间的“差分”。因此我们一般会用拉普拉斯矩阵 L = D - A来做,其中D为图的度矩阵(对角矩阵,对角线的值,为邻接矩阵相应行的和):
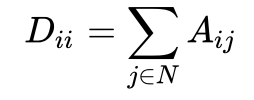
节点的“差分”可以表示为:

从化简后的公式可以看到,通过拉普拉斯矩阵的相乘,我们求得是以边为权、节点特征的差分。
- 归一化
然而,无论是A+I还是D-A,其实存在一个重大的问题,我们求的是和而不是平均。我们可能会面临『大佬可能没有多少朋友』的问题。在聚合后,即使大佬的朋友圈都是高收入群体,也没办法超过一个拥有低端朋友圈的交际花。

归一化的加权平均法:
严谨来说,这会导致离群较远或者度较小的节点在聚合后特征较小,离群较近或者度较大的节点在聚合后特征较大。因此,我们需要通过归一化消除这个问题。这里,我们令或D-A,其中
为
的度矩阵:

从化简后的公式可以看到,通过 操作,已经将求和变成了加权平均啦,权值之和归一化为 1 了~
- 对称归一化
解决了平均的问题,我们能不能更进一步呢?现在朋友很少的大佬满意了。然而和朋友很少的大佬交朋友的都是什么人呢?除了高收入的程序员,还会有一些绿茶婊、交际花。表面上看,这些『交际花似乎也是大佬为数不多的朋友之一』,然而她的工资和大佬们天差地别。之所以她与大佬是朋友,是因为她跟每个人几乎都是朋友,想要扩展自己的人脉圈。因此,我们要剔除这一部分交际花对大佬工资预测的影响。

对称归一化的加权平均法
严谨来说,我们除了应该考虑聚合节点 i的度,还应该考虑被聚合节点j的度
。如何同时考虑两者呢,我们可以使用几何平均数
:

从化简后的公式可以看到,通过 操作,已经在加权时将
拆分成了
的几何平均,从而剔除了被聚合节点
j的度的影响。
-
以小人之心度君子之腹
好了,到这里 GCN 的公式已经进化成完全体了。然而,大佬们是如何想到这种方法的呢?不难发现,大佬们的这个公式很接近拉(就是)普拉斯变换或者说谱聚类:
1. 首先计算出标准化后的拉普拉斯矩阵
2. 将拉普拉斯矩阵进行 SVD 特征分解,得到U (每一列为拉普拉斯矩阵对应的特征向量)
3. 选取较小的k个特征值对应的特征向量丢进其他聚类算法,诸如 KMeans
大声说出来,由传统方法设计机器学习方法的时候应该怎么办!
加训练参数!
加训练参数!
加训练参数!
个人觉得,GCN 就是借鉴了谱聚类的思路加个参数:
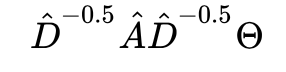
搞定,阳光下没有新鲜事啦~ 当然,很多论文中在推导时为了保证严谨性,从傅立叶变换进行约简也是很有趣的角度呦。
3. 矩阵式聚合与消息式聚合的实现
上文中介绍了邻接矩阵变换公式和其等价的加权平均公式。在代码实现时,邻接矩阵变换公式对应了矩阵式聚合,加权平均公式对应了消息式聚合。
学术界的大佬似乎更喜欢邻接矩阵变换,稀疏矩阵的乘法优化使得规模较小 graph 上的矩阵式聚合速度较快。使用矩阵式聚合可以让我们在诸如拳击俱乐部这样的数据集上迅速获得聚合结果:
import math
import torch
from torch.nn.parameter import Parameter
from torch.nn.modules.module import Module
class GraphConvolution(Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'『DGL 示例』工业界一贯的做法是消息传递,一个节点可以捕获周围节点发出的消息,并根据消息内容计算节点新的表达方式。这种实现在边稠密的 graph 效率较低,但试用于大规模 graph 的卷积,聚合方式也更加灵活一点:
import torch.nn as nn
import torch.nn.functional as F
# Define the message & reduce function
# NOTE: we ignore the GCN's normalization constant c_ij for this tutorial.
def gcn_message(edges):
# The argument is a batch of edges.
# This computes a (batch of) message called 'msg' using the source node's feature 'h'.
return {'msg' : edges.src['h']}
def gcn_reduce(nodes):
# The argument is a batch of nodes.
# This computes the new 'h' features by summing received 'msg' in each node's mailbox.
return {'h' : torch.sum(nodes.mailbox['msg'], dim=1)}
# Define the GCNLayer module
class GCNLayer(nn.Module):
def __init__(self, in_feats, out_feats):
super(GCNLayer, self).__init__()
self.linear = nn.Linear(in_feats, out_feats)
def forward(self, g, inputs):
# g is the graph and the inputs is the input node features
# first set the node features
g.ndata['h'] = inputs
# trigger message passing on all edges
g.send(g.edges(), gcn_message)
# trigger aggregation at all nodes
g.recv(g.nodes(), gcn_reduce)
# get the result node features
h = g.ndata.pop('h')
# perform linear transformation
return self.linear(h)4. 更多拓展
当然,聚合的方法有很多种,CNN 已经为我们提供了很多参(照)考(抄)。
Attention 的思路很棒,有 GAT 和 AGNN。
Pooling 的思路很棒,有 GraphSAGE。
Deep 的思路很棒,有 DeepGCN。
扩大感受野的思路也很棒,比如 High-Order GCN(矩阵式)和 PinSAGE(消息式)。
做 Graph Deep Learning 的大家加油吖!
