RHCS(Red Hat Cluster Suite),也就是红帽子集群套件,RHCS是一个能够提供高可用性、高可靠性、负载均衡、存储共享且经济廉价的集群工具集合,它将集群系统中三大集群架构融合一体,可以给web应用、数据库应用等提供安全、稳定的运行环境。更确切的说,RHCS是一个功能完备的集群应用解决方案,它从应用的前端访问到后端的数据存储都提供了一个行之有效的集群架构实现,通过RHCS提供的这种解决方案,不但能保证前端应用持久、稳定的提供服务,同时也保证了后端数据存储的安全。
RHCS提供了集群系统中三种集群构架,分别是高可用性集群、负载均衡集群、存储集群。
什么是集群:
采用集群系统(Cluster),将各个主机系统通过网络或其他手段有机地组成一个群体,共同对外提供服务
高可用集群工作方式的原理:
多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管。
负载均衡服务器的高可用性:
主服务器和备份机上都运行High Availability监控程序,通过传送诸如“I am alive”这样的信息来监控对方的运行状况。当备份机不能在一定的时间内收到这样的信息时,它就接管主服务器的服务IP并继续提供服务;当备份管理器又从主管理器收到“I am alive”这样的信息时,它就释放服务IP地址,这样的主管理器就开始再次进行集群管理的工作了。为在主服务器失效的情况下系统能正常工作,我们在主、备份机之间实现负载集群系统配置信息的同步与备份,保持二者系统的基本一致。
一.下载工具并初始化配置
server1:
1.配置yum源(server1和server2)
vi /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.77.250/westos
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.77.250/westos/HighAvailability
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.77.250/westos/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.77.250/westos/ResilientStorage
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.77.250/westos/ScalableFileSystem
gpgcheck=0
yum clean all
yum repolist
2.在server1上安装图形网页管理工具ricci(推广更新的集群信息)和luci(Conga 用户界面服务器)。server2上下载安装ricci
yum install -y ricci luci
3.在server1和server2上设置ricci用户密码
passwd ricci


4.server1打开ricci和luci并开机启动。
/etc/init.d/ricci start
/etc/init.d/luci start
chkconfig ricci on
chkconfig luci on

server2打开ricci并开机启动

在物理机的浏览器访问https://172.25.34.1:8084


二. 配置实现apache的高可用
1.在luci界面添加新的集群westos_ha,添加两个节点server1和server2
 2.添加节点成功
2.添加节点成功

3.建立错误恢复域webfail,设置sever1和server2的优先级(数字小优先级高)

4.添加服务中所要用到的资源
apache服务需要的资源有VIP(对外虚拟IP)和启动apache服务的脚本script


5.集群添加服务

三. fence设备
如何解决如下问题:当主机没有问题,但是主机与备机的通信出现问题,集群资源被多个节点占有,两个服务器同时向资源写数据,破坏了资源的安全性和一致性,这种情况的发生叫做“脑裂“
答:fence 控制物理电源
主机没有问题,备机也没有问题。但是主机与备机通信出问题,fence拔掉电源,防止主备强抢资源,保证服务可用
fence的工作原理是:
当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。Fence 一个节点所需时间取决于所使用的整合 fence 设备。有些整合 fence 设备的功能与长按电源开关一致,因此 fence设备可在 4-5 秒内关闭该节点。其他整合 fence 设备性能与按一下电源开关一致,要依靠操作系统关闭该节点,因此 fence设备关闭该节点的时间要大大超过 4-5 秒钟。
下面来具体配置环境:
1.物理机上安装
yum search fence-virtd

2.开启服务
systemctl start fence_virtd
systemctl status fence_virtd.service

3.编辑fence的配置文件
fence_virtd -c
4.建立密钥目录,截取密钥
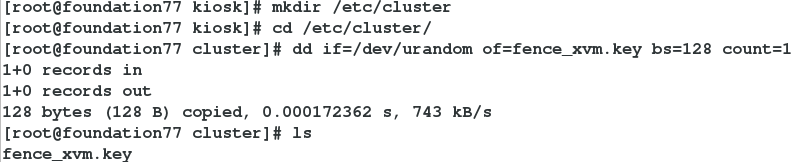
mkdir /etc/cluster
dd if=/dev/urandom of=fence_xvm.key bs=128 count=1
5.将修改好的密钥文件发送给高可用节点server1和server2,保证server1和server2使用相同的密钥

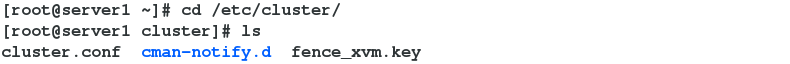
 5.添加fence设备
5.添加fence设备

 6.节点上添加fence
6.节点上添加fence

1)server1添加 vmfence-1
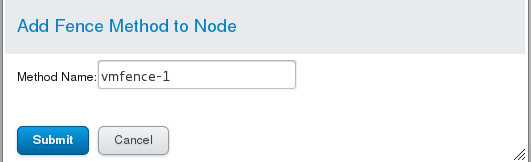
2)查看server1的UUID
 3)提交
3)提交
 4)server2添加 vmfence-2
4)server2添加 vmfence-2
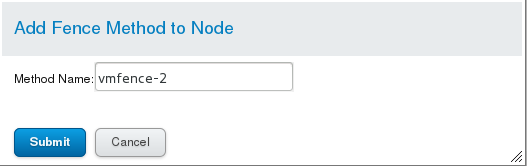
5)查看server2的UUID
 6)提交
6)提交
 测试:
测试:
1.让apache服务运行在server2上

2.让server2服务器挂掉
# echo c > sysrq-trigger ##让内核发生故障,也就是让server2挂掉
 3.发现apache服务现在是运行在server1上
3.发现apache服务现在是运行在server1上

