一、hadoop介绍
1.大数据概念
大数据只的是哪些数据量特别大,数据类型特别复杂的数据集。这些数据集无法使用传统的数据库进行存储、管理和处理。大数据的主要特点为:数据量大(Volume),数据类型特别复杂(Variety),数据处理速度快(Velocity)和数据真实性高(Veracity),合起来称为 4V。
2.what hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker组成.如下图所示:
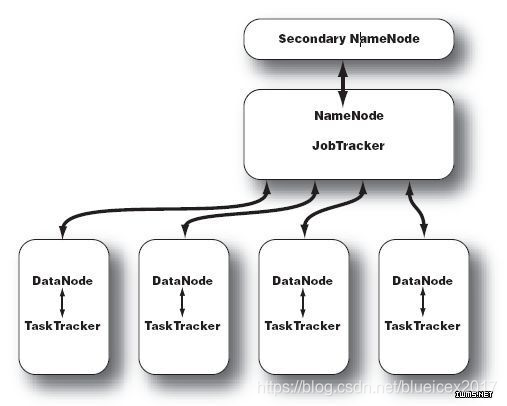
NameNode中记录了文件是如何被拆分成block以及这些block都存储到了那些DateNode节点.NameNode同时保存了文件系统运 行的状态信息. DataNode中存储的是被拆分的blocks.Secondary NameNode帮助NameNode收集文件系统运行的状态信息.JobTracker当有任务提交到Hadoop集群的时候负责Job的运行,负责调 度多个TaskTracker.TaskTracker负责某一个map或者reduce任务。
Hadoop是一个开源的框架,可编写和运行分不是应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。 HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.所谓非结构化数据存储就是说HBase是基于列的而不是基于行的模式,这样方面读写你的大数据内容。 HBase是介于Map Entry(key & value)和DB Row之间的一种数据存储方式。不仅仅是简单的一个key对应一个 value,你很可能需要存储多个属性的数据结构,但没有传统数据库表中那么多的关联关系,这就是所谓的松散数据。 简单来说,在HBase中的表创建的可以看做是一张很大的表,而这个表的属性可以根据需求去动态增加,在HBase中没有表与表之间关联查询。只需要告诉数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。但是需要注意HBase中不包含事务此类的功能。 Apache HBase 和Google Bigtable 有非常相似的地方,一个数据行拥有一个可选择的键和任意数量的列。表是疏松的存储的,因此用户可以给行定义各种不同的列,对于这样的功能在大项目中非常实用,可以简化设计和升级的成本。 Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Hadoop 是 Apache 旗下的一套开源软件平台。Hadoop 可以利用计算机集群,根据用户自定义的业务逻辑对海量数据进行分布式处理。通常我们说的 Hadoop 是指一个更广泛的概念–Hadoop 生态圈。
3.hadoop 生态圈
Hadoop 生态圈是指以 Hadoop 为基础发展出来的一系列技术。这些技术都是为了解决大数据处理过程中不断出现的新问题而产生的。
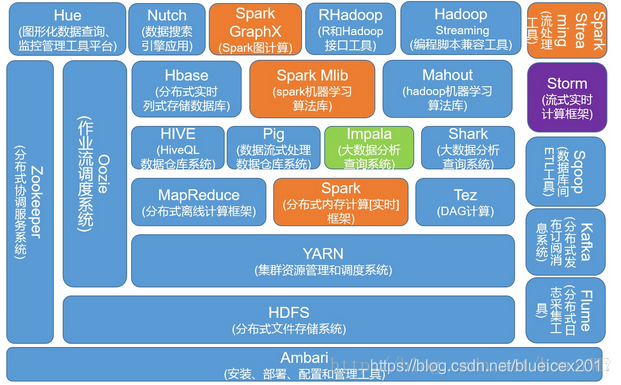
图中包含目前最流行的两个大数据处理框架 Hadoop 和 Spark。蓝色部分是 Hadoop 的生态圈组件,黄色部分是 Spark 生态圈组建。这两个框架之间的关系并不是互斥的,它们之间既有合作,补充又有竞争。比如 Spark 提供的实时内存计算是比 Hadoop 中 MapReduce 快的多的技术,但是 Spark 又依赖于 Hadoop 中的 HDFS 来存储数据。虽然 Spark 也可以基于于别的系统进行搭建,但是大家一致认为 Spark 和 Hadoop 更配。
4.hadoop 起源
一切起源于谷歌的三遍论文:
Google FileSystem:用普通计算机存储海量的数据;
Google MapReduce:快速的计算海量的数据;
Google BigTable:实现海量数据的快速查询;
Doug Cutting 在完成 Java 搜索引擎 Nutch 的时候接触到了这三篇论文,根据其理论作出了 Java 的实现,就是 Hadoop 系统。随后将其开源并交与 Apache 基金会进行管理,Hadoop 就逐渐壮大起来。
5.hadoop生态圈组件
HDFS
大数据技术首要的要求就是先把数据存下来。HDFS(Hadoop Distributed FileSystem)的设计本质就是为了大量的数据能够横跨成千上万台机器存储,但是对于用户来说看到的是一个文件系统而不是许多文件系统。比如说你要获取 /hdfs/tmp/aaa 的数据,虽然使用的是一个路径,但找个文件的数据可能存放在很多台不同的机器上。作为用户来说不需要知道数据到底存储在哪儿,就像你在单机上并不关心文件到底存储在磁盘那个扇区一样。这些数据交由 HDFS 来管理,用户可以更关注于数据的使用和处理。
(1)设计思想:一次写入,多次读取,写入后存储在HDFS上就不能修改,但可以把文件下载到本地,把HDFS上的文件删除,修改后再上传到HDFS上,实现文件的修改。
(2)文件属性(文件元数据):文件名称、存储位置、副本数、权限(RWX)、有哪些存储块,各个块存储在哪些DataNode上。
(3)存储的形式:块block,块的大小:默认128MB,可以用户自定义大小。
比如:文件大小为500MB,块大小是256MB,第一个块:256MB,第二个块:244MB。
如果文件大小小于数据块的大小,它是不会占据整个块的空间的。而且多个文件不能放到一个块中。
HDFS不太适合存储大量的小文件,可以将小文件进行合并。
(4)主从架构
主节点namenode:管理存储元数据;
从节点datanode:真正存储文件,消耗硬盘。
NameNode是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在DataNode等。
DataNode在本地文件系统存储文件块数据,以及块数据的校验和。
SecondaryNameNode是用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
(5)读写流程
首先client通过RPC协议请求namenode获取文件的位置,然后到具体datanode上读写。在哪个datanode上读写遵循就近原则,选择距离client近的datanode读写,目的是减少网络传输的时间消耗和资源消耗。
client -> namenode
client -> datanode
淘宝文件系统是TFS,在github上开源。
MapReduce
能够存储数据后,接下来就要考虑怎么处理数据了。一台计算机处理成 T 上 P 的数据可能需要几天甚至好几周,对于大部分公司都是不可接受的。比如微博的热搜,每 24 小时更新一次,就要求必须在 24 小时内分析完所有数据。如果我们使用很多台计算机进行处理就面临了计算机之间如何分配任务,如何通信,如何进行数据交换等问题。这就是 MapReduce/Tez/Spark 所要解决的问题:提供一种可靠的,能够运行在集群上的计算模型。
Hive
在使用了一段时间的 MapReduce 以后,程序员发现 MapReduce 的程序写起来太麻烦。希望能够封装出一种更简单的方式去完成 MapReduce 程序,于是就有了 Pig 和 Hive。Pig 是以类似脚本的方式去描述 MapReduce,而 Hive 则是以 SQL 的方式。它们会自动把脚本或者 SQL 翻译成 MapReduce 程序,然后丢给计算引擎去计算处理。有了 Hive 以后人们发现 SQL 的优势太大了。一是容易写,一两行的 SQL 换成 MapReduce 可能要几十上百行。二是容易上手,即使非计算机背景的用户也可以很快的学会。三是易写易改,一看就懂,容易维护。所以自从 Hive 问世很快就成长为大数据仓库的核心技术。使用了一段时间的 Hive 后人们发现 Hive 运行在 MapReduce 上太慢了。于是有开发出了针对于 SQL 优化的技术 Impala,Drill 和 Presto 等。这些技术牺牲了系统的通用性和稳定性来提高 SQL 的效率,最终并没有流行起来。
Storm
如果想要更快的计算速度,比如视频网站的热博榜,要求更新延迟在一分钟内,上面的任何一种手段都无法胜任。于是 Streaming(流)计算模型被开发出来了。Storm 是最流行的流计算平台。流处理的思路就是在数据进入系统的时候就进行处理,基本无延迟。缺点是不灵活,必须事先直到需要统计的数据,数据流过就没有了,没法进行补算。因此它是个好东西,但还是无法代替上述体系的。
HBase
HBase 是一个构建与 HDFS 的分布式,面向列的存储系统。以 kv 对的方式存储数据并对存取操作做了优化,能够飞快的根据 key 获取绑定的数据。例如从几个 P 的数据中找身份证号只需要零点几秒。
yarn
为了使这么多工具有序的运行在同一个集群上,我们需要使用一个调度系统进行协调指挥。目前流行的是使用 yarn 来进行管理。
(1)主从架构
主节点:resourcemanager,管理并分配整个集群的资源;
从节点:nodemanager,消耗资源。
(2)作用:集群资源分配管理,多任务调度。
总的资源:CPU、内存、硬盘。
多任务调度:运行的任务需要时间和资源。
ApplicationMaster应用管理者:每一个应用都会有一个应用管理者。
Container容器:每个map都是在各自独立的环境中去运行(资源独立),任务就在容器中运行。
(3)ResourceManager:负责处理客户端请求,启动/监控ApplicationMaster,监控NodeManager,资源分配与调度。
NodeManager:负责单个节点上的资源管理,处理来自ResourceManager的命令和来自ApplicationMaster的命令。
ApplicationMaster:负责数据切分,为应用程序申请资源,并分配给内部任务,负责任务监控与容错。
Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
NodeManager和DataNode一般会放在一台机器上。DataNode消耗磁盘空间,NodeManager消耗资源。集群单个节点的资源都在NodeManager中,每个Container容器也都是在不同的NodeManager节点上运行的。
Yarn是在Hadoop 2.x系统中才有的新的框架组件,Hadoop 0.x 和 Hadoop 1.x 版本中的组件服务很少,只有HDFS+MapReduce。
其他定制组件
除此之外还有需要定制的组件。比如:Mahout 是机器学习和推荐引擎,Nutch 是搜索引擎,Zookeeper 是集群管理工具,Sqoop 是 Hadoop 和数据库之间的导入导出工具,Flume 是日志采集工具,Oozie 是作业流调度系统等。
6.Hadoop 的发行版
Hadoop 1.x
该系列有 HDFS + MapReduce 组成。HDFS 负责存储数据,MapReduce 负责处理数据。
Hadoop 2.x
该系列把 1.x 系列的 MapReduce 拆成了 MapReduce + Yarn。MapReduce 负责定义功能,Yarn 负责资源管理和调度,实现功能。
CDH
全称 Cloudera’s Distribution Including Apache Hadoop。是 Cloudera 公司在 Hadoop 的基础上进行了商业化的产品,通常称为 CDH。共有 5 个版本,目前最新的是 CDH 5。虽然是商业化的产品,但是可以免费使用。
2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务和培训。2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司,Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support。CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。Cloudera公司的Hadoop发行版是CDH版。
Hadoop发展十年
(1)2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
(2)2007年10月,第一个Hadoop用户组会议召开,社区贡献开始急剧上升。
(3)2008年1月,Hadoop成为Apache顶级项目。
(4)2008年8月,第一个Hadoop商业化公司Cloudera成立。
(5)2009 年3月,Cloudera推出世界上首个Hadoop发行版——CDH(Cloudera’s Distribution including Apache Hadoop)平台,完全由开放源码软件组成。
(6)2010年-2011年,扩大的Hadoop社区忙于建立大量的新组件(Crunch,Sqoop,Flume,Oozie等)来扩展Hadoop 的使用场景和可用性。
(7)2011年5月,Mapr Technologies公司推出分布式文件系统和MapReduce引擎——MapR Distribution for Apache Hadoop。
(8)2011年7月,Yahoo!和硅谷风险投资公司 Benchmark Capital创建了Hortonworks 公司,旨在让Hadoop更加可靠, 并让企业用户更容易安装、管理和使用Hadoop。
(9)2014年2月,Spark逐渐代替MapReduce成为Hadoop的缺省执行引擎,并成为Apache基金会顶级项目。
7.hadoop模块
Hadoop 2.x主要包括四个模块:
(1)Hadoop Common:为其他Hadoop模块提供基础设施。
(2)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
(3)Hadoop MapReduce:一个分布式的离线并行计算框架。
(4)Hadoop YARN:一个新的MapReduce框架,任务调度与资源管理。
8.hadoop三种模式
Local (Standalone) Mode 本地模式:不使用HDFS文件系统,使用本地文件系统,程序员调试用;
Pseudo-Distributed Mode 伪分布式模式:单节点,一台机器,使用HDFS文件系统,程序员调试用;
Fully-Distributed Mode 完全分布式模式:真实生产环境用,集群。
二、hadoop安装
1.先决条件
jdk1.8
hadoop3.x
ssh互信
firewalld关闭
selinux disabled
时间同步
2.硬件架构
| 序号 | 主机名 | IP |
|---|---|---|
| 1 | master | 192.168.1.71 |
| 2 | node1 | 192.168.1.72 |
| 3 | node2 | 192.168.1.73 |
| n | noden | 192.168.1.7n |
3.环境准备
A.Linux环境准备
master节点初始化
repo文件下载(永久):https://pan.baidu.com/s/1RACvzqlbY1ExIFPeApMsfA 提取码:26rg
[root@localhost ~]# mkdir /blueicex/{soft,temp} /mnt/cdrom -pv
[root@localhost ~]# echo "/dev/cdrom /mnt/cdrom iso9660 defaults 0 0" >> /etc/fstab
[root@localhost ~]# mount -a
mount: /dev/sr0 is write-protected, mounting read-only
[root@localhost ~]# yum makecache
[root@localhost ~]# yum install ansible vim psmisc net-tools bash-comp* tree fish lftp chrony screen wget lrzsz ntpdate -y
[root@localhost ~]# grep 'DNS' /etc/ssh/sshd_config
#UseDNS yes
[root@localhost ~]# sed -i 's/#UseDNS yes/UseDNS no/g' /etc/ssh/sshd_config
[root@localhost ~]# grep 'DNS' /etc/ssh/sshd_config
UseDNS no
[root@localhost ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
[root@localhost ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.71 master master.blueicex.com master.blueice.com
192.168.1.72 node1 node1.blueicex.com node1.blueice.com
192.168.1.73 node2 node2.blueicex.com node2.blueice.com
192.168.1.74 node3 node3.blueicex.com node3.blueice.com
192.168.1.75 node4 node4.blueicex.com node4.blueice.com
192.168.1.76 node5 node5.blueicex.com node5.blueice.com
192.168.1.77 node6 node6.blueicex.com node6.blueice.com
[root@localhost ~]# scp /etc/{hosts,hostsbak}
B.ssh互信
[root@localhost temp]# vim dmt.sh
#/bin/bash
rm ~/ssh. -rf
mkdir ~/ssh. -pv
ssh-keygen -N "" -f /root/.ssh/id_rsa
ssh-copy-id -i /root/.ssh/id_rsa 192.168.1.71
ssh-copy-id -i /root/.ssh/id_rsa 192.168.1.72
ssh-copy-id -i /root/.ssh/id_rsa 192.168.1.73
ssh-copy-id -i /root/.ssh/id_rsa 192.168.1.74
ssh-copy-id -i /root/.ssh/id_rsa 192.168.1.75
ssh-copy-id -i /root/.ssh/id_rsa 192.168.1.76
[root@localhost temp]# ./dmt.sh
[root@localhost ~]# mkdir sshbak
[root@localhost ~]# cp .ssh/* .sshbak
[root@localhost ~]# for i in {1..6}; do ssh root:blueice1980@node$i rm -rf /root/.ssh/ ; done
[root@localhost ~]# for i in {1..6}; do ssh root:blueice1980@node$i mkdir /root/.ssh/ ; done
[root@localhost ~]# for i in {1..6}; do scp /root/.ssh/* node$i:/root/.ssh/; done
[root@localhost ~]# for i in {1..6}; do ssh node$i hostnamectl set-hostname node$i; done
[root@localhost ~] hostnamectl set-hostname master
ansible 主机清单
[root@master ~]# vim /etc/ansible/hosts
[all]
192.168.1.71
192.168.1.72
192.168.1.73
192.168.1.74
192.168.1.75
192.168.1.76
[node]
192.168.1.72
192.168.1.73
192.168.1.74
192.168.1.75
192.168.1.76
[master]
192.168.1.71
[node1]
192.168.1.72
[node2]
192.168.1.73
[node3]
192.168.1.74
[node4]
192.168.1.75
[node5]
192.168.1.76
验证ansible
[root@master ~]# ansible all -a 'ls'
node节点初始化
[root@master ~]# ansible all -m shell -a 'mkdir /blueicex/{soft,temp} /mnt/cdrom /usr/local/{jdk1.8,zookeeper,hadoop,hbase,httpd24,pychram,eclipse,hive,mysql,php,nginx} -pv'
[root@master ~]# ansible node -m shell -a 'echo "/dev/cdrom /mnt/cdrom iso9660 defaults 0 0" >> /etc/fstab'
[root@master ~]# ansible node -m shell -a ' mount -a'
[root@master ~]# ansible node -m shell -a 'rm -rf /etc/yum.repos.d/*'
[root@master ~]# cd /etc/yum.repos.d/
[root@master ~]# tar cvzf repos.tar.gz *
[root@master ~]# ansible node -m unarchive -a 'dest=/etc/yum.repos.d/ src=/etc/yum.repos.d/repos.tar.gz'
[root@master ~]# ansible node -m shell -a 'yum install vim psmisc net-tools bash-comp* tree fish chrony lftp screen wget ntpdate lrzsz -y'
[root@master ~]# ansible node -m shell -a "sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config"
[root@master ~]# ansible node -m copy -a 'dest=/etc/hosts src=/etc/hosts'
C.firewalld关闭
[root@master ~]# ansible all -m shell -a 'systemctl stop firewalld && systemctl disable firewalld'
D.selinux disabled
[root@master ~]# ansible node -m shell -a "sed -i 's/#UseDNS yes/UseDNS no/g' /etc/ssh/sshd_config"
E.时间同步
[root@master ~]# ansible all -m shell -a 'systemctl start chronyd && systemctl enable chronyd'
[root@master ~]# ansible all -m shell -a 'echo "allow 192.168.0.0/16" >> /etc/chrony.conf'
[root@master ~]# ansible all -m shell -a 'echo "local stratum 10" >> /etc/chrony.conf'
[root@master ~]# ansible all -m shell -a 'echo "server master iburst" >> /etc/chrony.conf'
[root@master ~]# ansible all -m service -a 'name=chronyd state=restarted'
[root@master ~]# ansible node -m shell -a 'ntpdate master'
G.JDK环境
JDK1.8下载位置(永久):https://pan.baidu.com/s/11MD0MGObGnYpp8E0Izoc3A 提取码:jvfn
[root@master ~]# ansible all -m shell -a 'echo "export JAVA_HOME=/usr/local/jdk1.8" >> /etc/profile'
[root@master ~]# ansible all -m shell -a 'echo "export JRE_HOME=\$JAVA_HOME/jre" >> /etc/profile'
[root@master ~]# ansible all -m shell -a 'echo "export CLASSPATH=\$JAVA_HOME/lib:\$JRE_HOME/lib:\$CLASSPATH" >> /etc/profile'
[root@master ~]# ansible all -m shell -a 'echo "export PATH=\$JAVA_HOME/bin:\$JRE_HOME/bin:\$PATH" >> /etc/profile'
[root@master ~]# ansible all -m shell -a 'echo "export JAVA_HOME=/usr/local/jdk1.8" >> /root/.bashrc'
[root@master ~]# ansible all -m shell -a 'echo "export JRE_HOME=\$JAVA_HOME/jre" >> /root/.bashrc'
[root@master ~]# ansible all -m shell -a 'echo "export CLASSPATH=\$JAVA_HOME/lib:\$JRE_HOME/lib:\$CLASSPATH" >> /root/.bashrc'
[root@master ~]# ansible all -m shell -a 'echo "export PATH=\$JAVA_HOME/bin:\$JRE_HOME/bin:\$PATH" >> /root/.bashrc'
[root@master soft]# lftp 192.168.1.46
lftp 192.168.1.46:~> get jdk-8u231-linux-x64.tar.gz
194151339 bytes transferred in 2 seconds (109.56M/s)
lftp 192.168.1.46:/> exit
[root@master ~]# ansible all -m unarchive -a 'dest=/usr/local/jdk1.8 src=/blueicex/soft/jdk-8u231-linux-x64.tar.gz'
[root@master ~]# ansible all -m shell -a 'mv /usr/local/jdk1.8/jdk1.8.0_231/* /usr/local/jdk1.8/'
H.重启环境
[root@master ~]# ansible all -m shell -a 'reboot'
验证JDK安装
[root@master ~]# ansible all -m shell -a 'java -versionn'
I.下载hadoop包
hadoop各大镜像站点都有
https://mirrors.huaweicloud.com/apache/hadoop/common/hadoop-3.2.1/
[root@master soft]# pwd
/blueicex/soft
[root@master soft]# wget https://mirrors.huaweicloud.com/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
[root@master soft]# tar xvf hadoop-3.2.1.tar.gz -C /usr/local/hadoop/
[root@master hadoop]# pwd
/usr/local/hadoop
[root@master hadoop]# mv hadoop-3.2.1 hadoop3.2.1
设置hadoop启动环境路径
[root@master hadoop]# echo ‘export HADOOP_HOME=/usr/local/hadoop/hadoop3.2.1’ >> /etc/profile
[root@master hadoop]# echo ‘export PATH=
HADOOP_HOME/sbin:$PATH’ >> /etc/profile
3.standalone模式安装
[root@master hadoop3.2.1]# pwd
/usr/local/hadoop/hadoop3.2.1
[root@master hadoop3.2.1]# mkdir input output
[root@master hadoop3.2.1]# vim input/1.txt
[root@master hadoop3.2.1]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input/1.txt output/2.txt
[root@master hadoop3.2.1]# cd output/
[root@master output]# cd 2.txt/
[root@master 2.txt]# ls
part-r-00000 _SUCCESS
[root@master 2.txt]# cat part-r-00000
(show). 1
Before 1
Best 1
Break 1
[root@master ~]# hadoop version
Hadoop 3.2.1
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842
Compiled by rohithsharmaks on 2019-09-10T15:56Z
Compiled with protoc 2.5.0
From source with checksum 776eaf9eee9c0ffc370bcbc1888737
This command was run using /usr/local/hadoop/hadoop3.2.1/share/hadoop/common/hadoop-common-3.2.1.jar
[root@master ~]# hadoop --help
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
4.Pseudo-Distributed Mode伪分布配置
hadoop所有配置文件都在安装目录etc/hadoop下
[root@master etc]# pwd
/usr/local/hadoop/hadoop3.2.1/etc/hadoop
[root@master etc]# mkdir hadoopbak
[root@master etc]# cp -R hadoop/. hadoopbak/
需要配置5个文件
A.设置hadoop环境变量
[root@master hadoop]# echo $JAVA_HOME
/usr/local/jdk1.8
[root@master hadoop]# echo 'export JAVA_HOME=/usr/local/jdk1.8 ’ >> hadoop-env.sh
B.配置文件系统和目录
[root@master hadoop]# vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop3.2.1/tmp</value>
<description>a base for other tempory directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
C.配置HDFS副本数和数据目录
[root@master hadoop]# vim hdfs-site.xml
<configuration>
<!-- namenode 上存储 hdfs 名字空间元数据-->
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hadoop3.2.1/tmp/dfs/name</value>
</property>
<!-- datanode 上数据块的物理存储位置-->
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hadoop3.2.1/tmp/dfs/data</value>
</property>
<!-- 设置 hdfs 副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
D.指定mapreduce程序在yarn集群上运行
[root@master hadoop]# vim mapred-site.xml
<configuration>
<!-- 指定yarn运行-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
</configuration>
E.配置yarn集群参数
[root@master hadoop]# vim yarn-site.xml
<!-- 指定ResourceManager的地址 -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>5</value>
</property>
</configuration>
F.修改sbin下的脚本文件
增加环境变量,用于root用户权限启动hadoop
[root@master sbin]# pwd
/usr/local/hadoop/hadoop3.2.1/sbin
文件开头处添加
[root@master sbin]# vim start-dfs.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
[root@master sbin]# vim stop-dfs.sh
#!/usr/bin/env bash
TANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
[root@master sbin]# vim start-yarn.sh
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@master sbin]# vim stop-yarn.sh
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@master sbin]# vim start-all.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@master sbin]# vim stop-all.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
G.启动hadoop
hadoop namenode初始化
[root@master hadoop]# hadoop namenode -format
[root@master hadoop]# start-all.sh
查看进程状态
[root@master sbin]# jps
11475 Jps
10438 NameNode
11159 NodeManager
10536 DataNode
11019 ResourceManager
10781 SecondaryNameNode
一台机器上配置Hadoop集群:NameNode、DataNode、SecondaryNameNode,YARN集群:ResourceManager、NodeManager。Hadoop集群负责分布式存储和预算,YARN集群负责任务资源管理和调度。
hdfs测试站点地址 http://192.168.1.71:9870
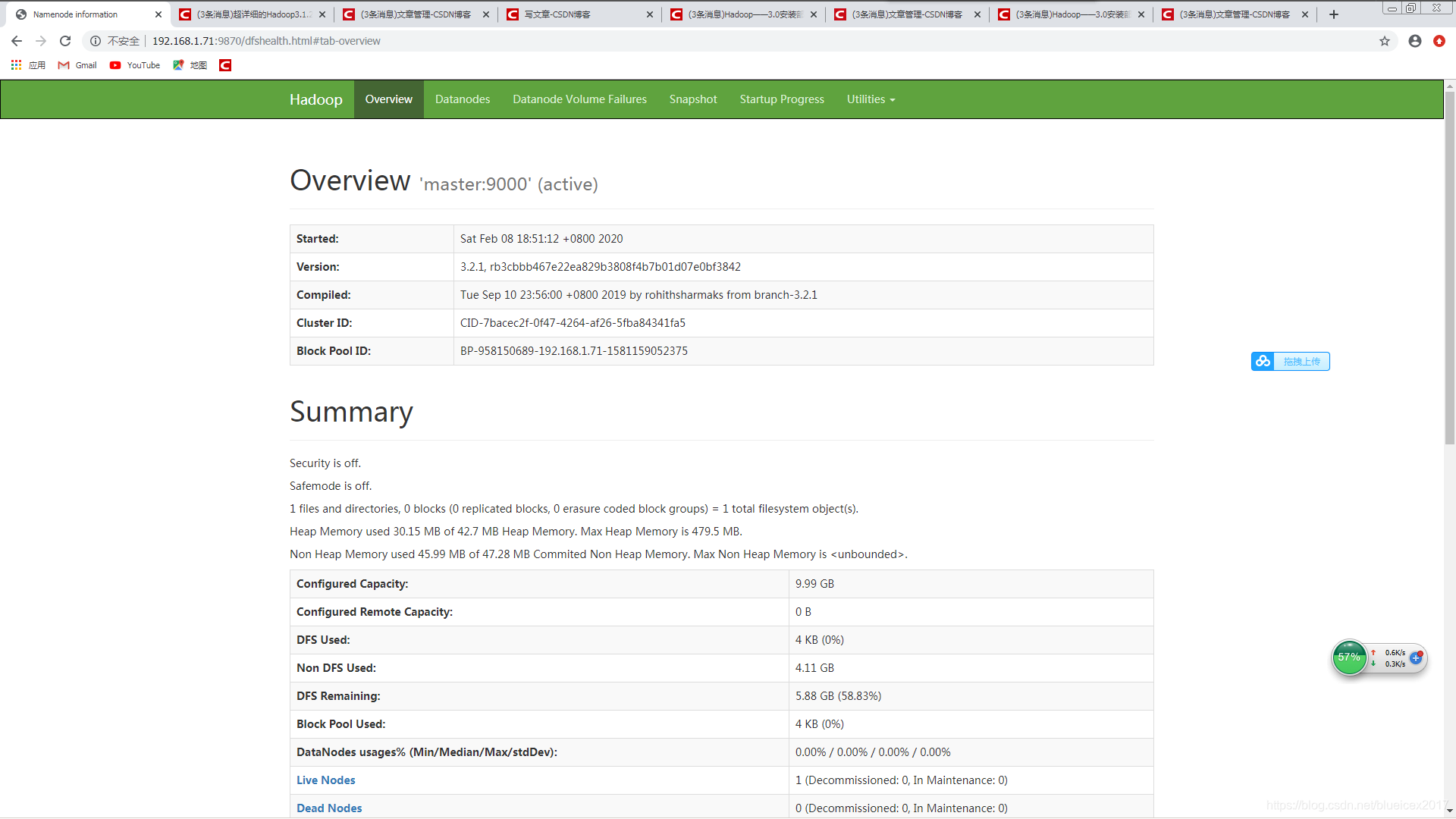
[root@master ~]# hdfs dfs -mkdir /test1
[root@master ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2020-02-09 09:23 /test1
[root@master ~]# hdfs dfs -touch /test1/a.txt
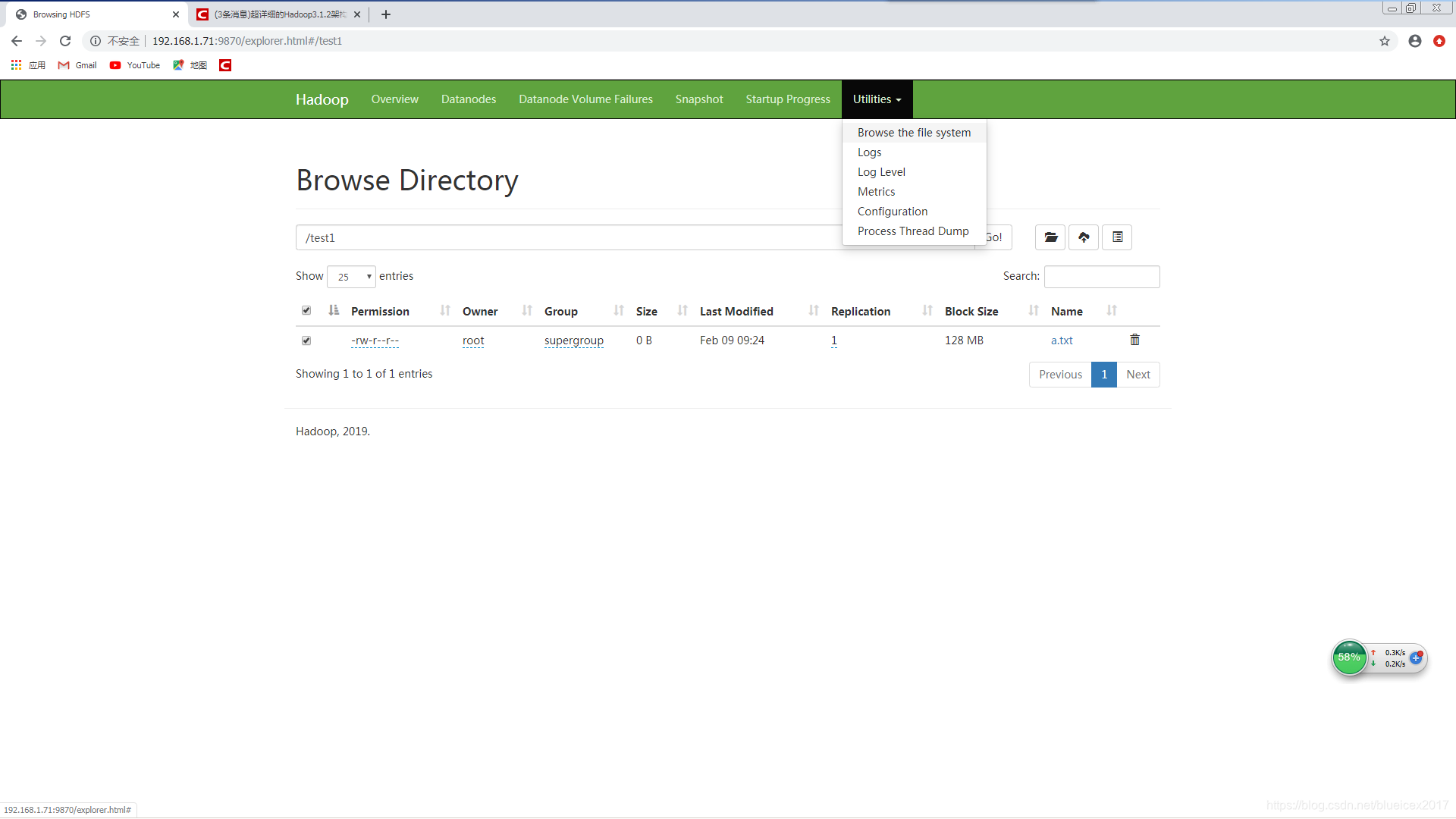
查看YARN集群状况
http://192.168.1.71:8088/cluster/

5.Fully-Distributed Mode 完全分布式模式
A.增加节点
在伪分布集群配置的基础上,修改etc/hadoop/workers
[root@master hadoop]# vim workers
master
node1
node2
node3
node4
node5
B.分发安装程序
[root@master ~]# cd /usr/local/hadoop/hadoop3.2.1/
[root@master hadoop3.2.1]# tar cvzf hadoop.tar.gz .
[root@master hadoop3.2.1]# ansible node -a 'mkdir /usr/local/hadoop/hadoop3.2.1'
[root@master hadoop3.2.1]# ansible node -m unarchive -a 'src=/usr/local/hadoop/hadoop3.2.1/hadoop.tar.gz dest=/usr/local/hadoop/hadoop3.2.1'
C.启动测试
[root@master ~]# hdfs namenode -format
[root@master ~]# start-all.sh
[root@master ~]# jps
————Blueicex 2020/2/8 16:28 [email protected]
