写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Kafka 3.x的解压安装 - Linux
本文关键字:Linux、Kafka、解压、安装、console测试
文章目录
一、Kafka介绍
来自维基百科:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。
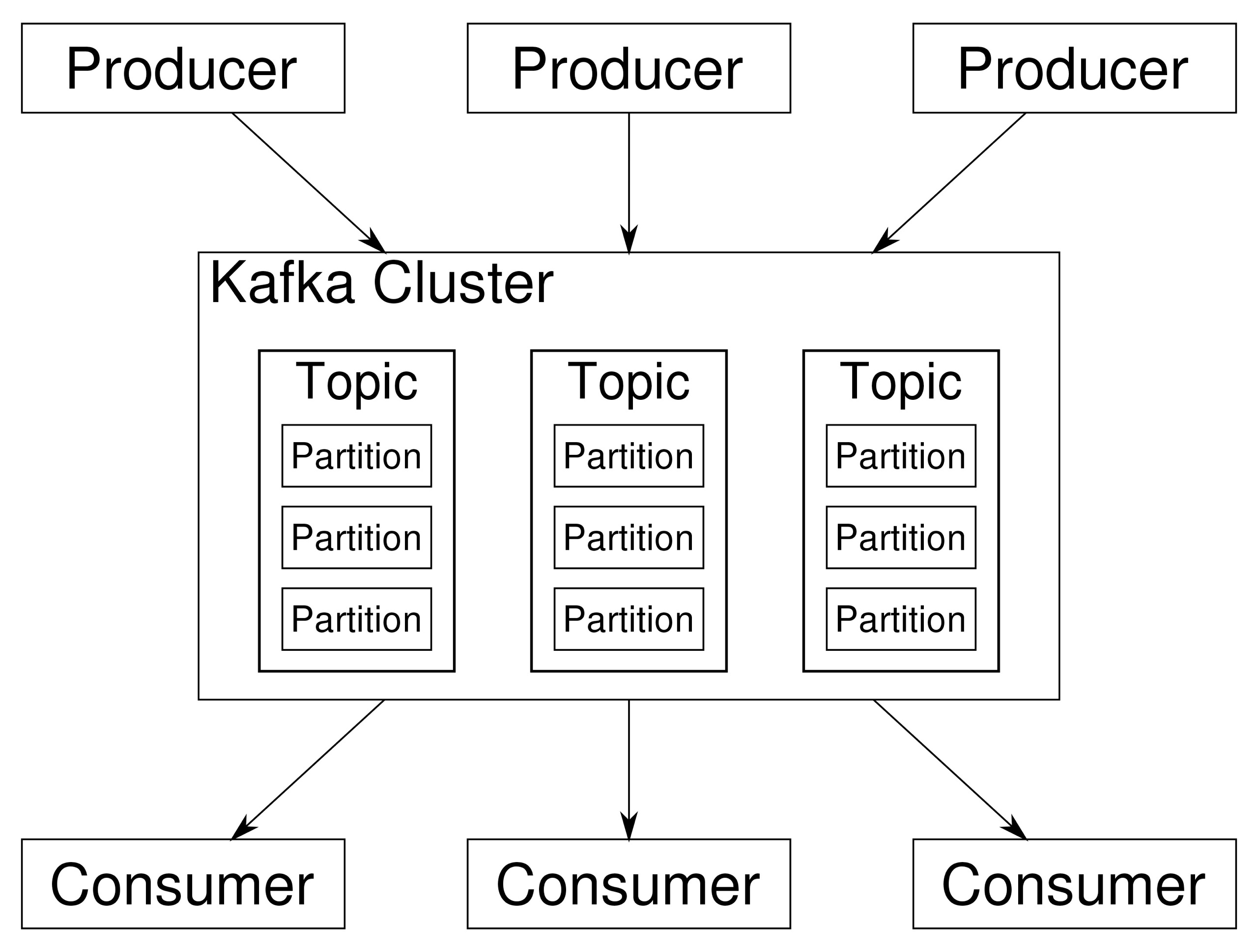
1. 应用场景
Kafka可以看作是一个能够处理消息队列的中间件,适用于实时的流数据处理,主要用于平衡好生产者和消费者之间的关系。
- 生产者
生产者可以看作是数据源,可以来自于日志采集框架,如Flume,也可以来自于其它的流数据服务。当接收到数据后,将根据预设的Topic暂存在Kafka中等待消费。对于接收到的数据将会有额外的标记,用于记录数据的被消费【使用】情况。
- 消费者
消费者即数据的使用端,可以是一个持久化的存储结构,如Hadoop,也可以直接接入支持流数据计算的各种框架,如Spark - Streaming。消费者可以有多个,通过订阅不同的Topic来获取数据。
2. 版本对比
Kafka的0.x和1.x可以看作是上古版本了,最近的更新也是几年以前,从目前的场景需求来看,也没有什么特别的理由需要使用到这两个版本了。
- 2.x
在进行版本选择时,通常需要综合考虑整个数据流所设计到的计算框架和存储结构,来确定开发成本以及兼容性。目前2.x版本同样是一个可以用于生产环境的版本,并且保持着对Scala最新版本的编译更新。
- 3.x
3.x是目前最新的稳定版,需要注意的是,Kafka的每个大版本之间的差异较大,包括命令参数以及API调用,所以在更换版本前需要做好详细的调查与准备,本文以3.x的安装为例。
二、Kafka安装
解压安装的操作方式可以适用于各种主流Linux操作系统,只需要解决好前置环境问题。
1. 前置环境
此前,运行Kafka需要预先安装Zookeeper。在Kafka 2.8.0版本以后,引入了Kraft(Kafka Raft)模式,可以使Kafka在不依赖外部Zookeeper的前提下运行。除此之外Kafka由Scala语言编写,需要JVM的运行环境。
- 检查已有的JDK环境
- Ubuntu/Debian:update-java-alternatives --list【需要已安装sudo apt install java-common】
- CentOS/RedHat:rpm -qa|grep java
检查已经安装的环境也可以使用find来搜索,或者使用java -version命令辅助验证,主要为了保证不会与即将安装的JDK版本产生冲突。
- 卸载不需要的JDK环境
- Ubuntu/Debian:sudo apt remove xxx
- CentOS/RedHat:sudo rpm -e --nodeps xxx
使用已经查到的软件包完整名称替换掉xxx的部分,可以卸载掉系统预装的JDK版本。
- 安装JDK
- Ubuntu/Debian:sudo apt install openjdk-8-jdk
- CentOS/RedHat:sudo yum install java-1.8.0-openjdk
安装完成后可以使用java-version命令验证【可省去环境变量配置】。
2. 软件安装
wget https://downloads.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgz

- 解压安装
tar -zvxf kafka_2.13-3.4.0.tgz
- 环境变量配置
- 系统环境变量:/etc/profile
- Ubuntu/Debian:~/.bashrc
- CentOS/RedHat:~/.bash_profile
需要在环境变量中指定Kafka的安装目录以及命令文件所在目录,系统环境变量与用户环境变量配置其中之一即可。
export KAFKA_HOME=/home/parallels/Software/kafka_2.13-3.4.0
export PATH=$PATH:$KAFKA_HOME/bin
在文件结尾添加以上内容后执行source命令,使其立即生效。
[Ubuntu/Debian]source ~/.bashrc
[CentOS/RedHat]source ~/.bash_profile
执行后可以输入kafka,然后按Tab尝试补全【需要按多次】,如果出现命令列表则证明配置成功。
3. 服务启动
如果使用Kraft模式,则需要先进行集群初始化【即使是单个节点】,以下为操作步骤:
- 创建Kafka的集群ID
调用kafka-storage.sh生成一个UUID,并存储在一个临时变量KAFKA_CLUSTER_ID中。
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"

- 执行格式化操作
进入到Kafka的家目录后,执行以下命令:
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties

- 启动Kafka集群
进入到Kafka的家目录后,执行以下命令
bin/kafka-server-start.sh config/kraft/server.properties
这种方式并不是后台运行,需要保证终端开启,等测试稳定后可以在后台执行或者注册为系统服务。

三、Console测试
1. 基础命令
- 查看Topic列表
kafka-topics.sh --list --bootstrap-server localhost:9092
- 创建Topic
- 默认:分区数为1
- 默认:副本因子为1
- 默认:删除策略为delete,即删除后数据不可恢复
- 默认:压缩类型为producer,即由生产者决定是否压缩消息
- 默认:清理策略为delete,即按照时间和大小进行日志清理
当创建一个Topic时,如果只填写Topic名称,会使用以上的默认配置
kafka-topics.sh --create --topic <topic-name> --partitions <num-partitions> --replication-factor <replication-factor> --bootstrap-server localhost:9092

- 查看Topic
kafka-topics.sh --describe --topic <topic-name> --bootstrap-server localhost:9092

- 删除Topic
kafka-topics.sh --delete --topic <topic-name> --bootstrap-server localhost:9092
2. 启动生产者
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-topic
启动一个基于console的生产者脚本,可以方便的进行数据输入的测试,直接进行数据输入即可。
3. 启动消费者
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning
添加from-beginning参数来从头消费数据。
4. 验证消费流程
在生产者脚本中持续输入数据,然后查看消费者脚本中的消费情况,使用Ctrl + C终止。

四、注册系统服务
为了方便的控制Kafka服务的启动和停止,可以将其注册为系统服务。
1. Systemd服务配置
- 创建Systemd服务文件
sudo vi /etc/systemd/system/kafka.service
在文件中添加以下内容,需要手动替换User和Group名称以及ExecStart和ExecStop中关于路径的部分:
[Unit]
Description=Apache Kafka
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=parallels
Group=parallels
ExecStart=/path/to/kafka_home/bin/kafka-server-start.sh /path/to/kafka_home/config/kraft/server.properties
ExecStop=/path/to/kafka_home/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target

- 重新加载Systemd配置
sudo systemctl daemon-reload
2. Kafka服务控制
- 开机自动启动
sudo systemctl enable kafka.service

- 启动Kafka服务
sudo systemctl start kafka.service
- 检查Kafka状态
sudo systemctl status kafka.service

- 停止Kafka服务
sudo systemctl stop kafka.service
- 重启Kafka服务
sudo systemctl restart kafka.service
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~
