写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Hive 3.x的安装部署 - Ubuntu
本文关键字:Hive、安装、部署、Linux、Ubuntu
文章目录
一、Hive简介
1. 什么是Hive
Hive是一个基于Hadoop的数据仓库解决方案,用于存储和处理大规模数据。它提供了类似SQL的查询语言(HiveQL)以便于分析和查询数据。

2. Hive的特性
- Hive特点
- HiveQL【SQL-like查询语言】
- 存储和计算分离
- 可扩展性和容错性
- 数据仓库功能
- 自定义函数和自定义聚合函数
- Hive3新特性
- 事务支持
- 性能优化
- 安全性增强
- 添加数据湖功能
- 更多数据类型和函数
二、Hive安装
1. 前置环境
- Hive本身的运行需要JDK环境
- Hive需要将数据存储在HDFS
- Hive需要将元数据存储在关系型数据库
2. 下载安装


- 选择版本

点击选择需要的版本,可以使用wget直接下载到Linux系统。
3. 软件配置
- 解压安装
tar -zvxf apache-hive-3.1.3-bin.tar.gz
- 环境变量配置
编辑.bashrc文件,修改并保存
export HIVE_HOME=/home/hadoop/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
退出后使用source命令刷新
source ~/.bashrc
三、启动验证
1. 元数据初始化
Hive在使用前需要将元数据保存在关系型数据库中,将表数据保存在HDFS,需要保证对应服务开启。
这里以MySQL为例,如果使用该数据库作为元数据存储位置,需要使得Hive能够连接到数据库,因此需要在lib目录下放入驱动jar包:
cd $HIVE_HOME/lib
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.32/mysql-connector-j-8.0.32.jar
- 编辑配置文件
在Hive的配置文件中需要指定MySQL的连接信息,包括连接地址、用户名以及密码等:
cd $HIVE_HOME/conf
# 创建一个新的hive-site.xml
vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_metastore?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=UTC</value>
<description>Metadata store connection URL</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Metadata store JDBC driver</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Metadata store username</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>Metadata store password</description>
</property>
</configuration>
- 执行初始化脚本
schematool -initSchema -dbType mysql
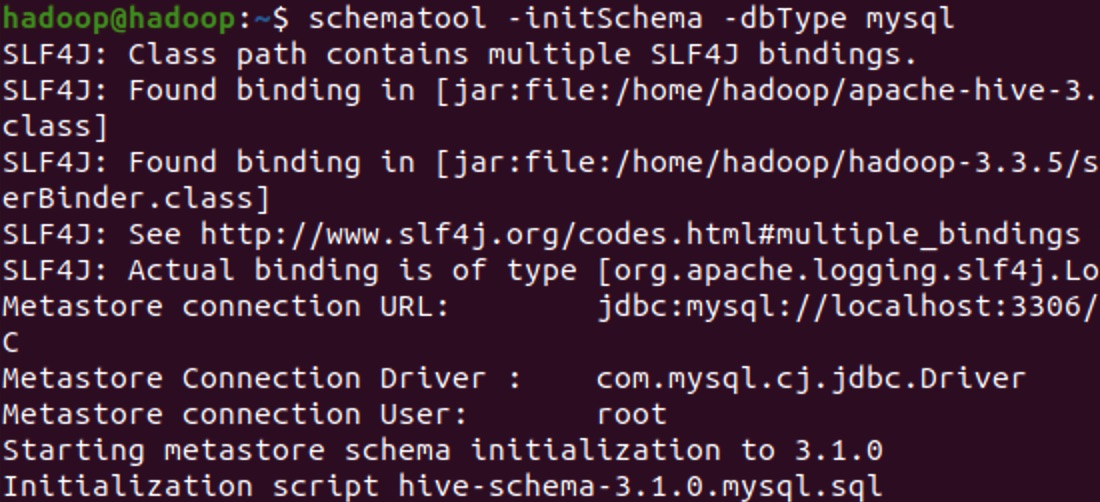
结尾会出现Initialization script completed和schemaTool completed证明成功。
2. 启动测试
在Hive安装完成后,可以使用hive命令直接开启一个连接,默认会出现一个default数据库:

3. HiveServer2与Beeline
完成以上步骤后,已经可以随时通过客户端命令对Hive进行访问,但是很多时候我们需要基于Hive进行开发或在代码中进行访问。此时,需要开启hiveserver2服务,能够方便的处理客户端发起的连接。
- HiveServer2主要作用
处理来自客户端的连接和请求;执行客户端提交的查询;支持多用户并发操作和认证;提供 JDBC/ODBC 接口,使外部应用程序和工具能够访问 Hive 数据仓库。
- Beeline介绍
Beeline 是一个基于 JDBC 的 Hive 客户端工具,用于连接到 HiveServer2 并执行查询。它采用命令行界面,用户可以在命令行中输入 SQL 查询并查看结果。通常我们会使用Beeline来测试HiveServer2服务是否正常工作。
- 开启远程连接
可以使用以下命令开启一个HiveServer2服务,监听10000端口,允许来自任意地址的机器进行远程连接。
nohup hive --service hiveserver2 --hiveconf hive.server2.thrift.bind.host=0.0.0.0 --hiveconf hive.server2.thrift.port=10000 &
也可以将以上命令中出现的两个配置写入到hive-site.xml文件中,在启动时即可省略。
- 开启代理权限
开启远程连接后,需要在Hadoop中配置代理用户,或是允许所有用户都可以连接,修改core-site.xml文件:
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
其中proxyuser后面的名称需要实际替换为启动Hadoop进程的用户,如:hadoop。
修改配置文件后要重启Hadoop服务,如果是分布式集群,需要同步配置文件。
- Beeline测试
开启HiveServer2服务后,使用以下命令进行连接测试
beeline -u jdbc:hive2://hadoop:10000

退出时使用 !quit
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~
