Yolo的环境
我写下我的环境
win10
python 3.6.4
tensorflow 1.8.0
tensorllow-gpu 1.8.0
cudatoolkit 9.0
cudnn 7.1.4
最好是使用anaconda进行环境配置
配置完后下载yolov3,
地址 https://github.com/qqwweee/keras-yolo3
导入我们配置的环境就可以直接用了,但是如果想训练自己的模型的话最好还是使用darknet.weight 地址 https://pjreddie.com/media/files/darknet53.conv.74
下载完之后更改名字,改为darknet53.weights
放入到yolo的根目录,这个时候先不要着急,跟目录里还有一个配置文件darknet53.cfg
打开这个文件,会发现有很多可以配置的东西:
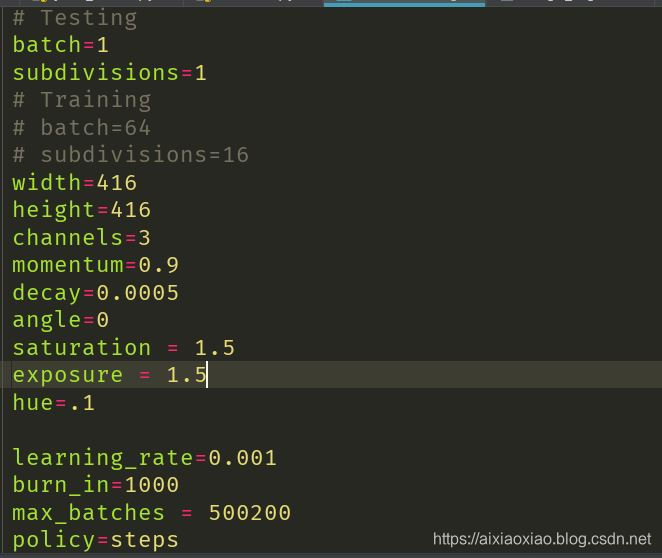
这里会发现有很多我们看的懂的或者看不懂的参数,不过都没关系,重点是batch和subdivisions两个数,分别改成64和16,如果想看具体的解释可以参照这篇文章https://blog.csdn.net/phinoo/article/details/83022101
这个时候执行python convert.py -w darknet53.cfg darknet53.weights model_data/darknet53_weights.h5
这样就能生成一个darknet53_weights.h5文件,我们训练的时候就用这个
数据集的预处理
在目录里有一个这样的文件voc_annotation.py,它是用来转换xml文件变为text文件的,那么xml文件是什么呢,首先yolo3是用来进行进行图像识别的(我感觉是),那么给你五万个数据,你想让程序直接识别出来是不可能的,这个时候你就需要给它先标注个1000张(具体情况具体分析),让他学习一下,我这里的例子是人民币编码的识别,一共九种面值,这样

我觉得他们是一类,所以就没有标注那么多,这里说一下标注工具:labelimage, https://download.csdn.net/download/qq_39226755/11562443
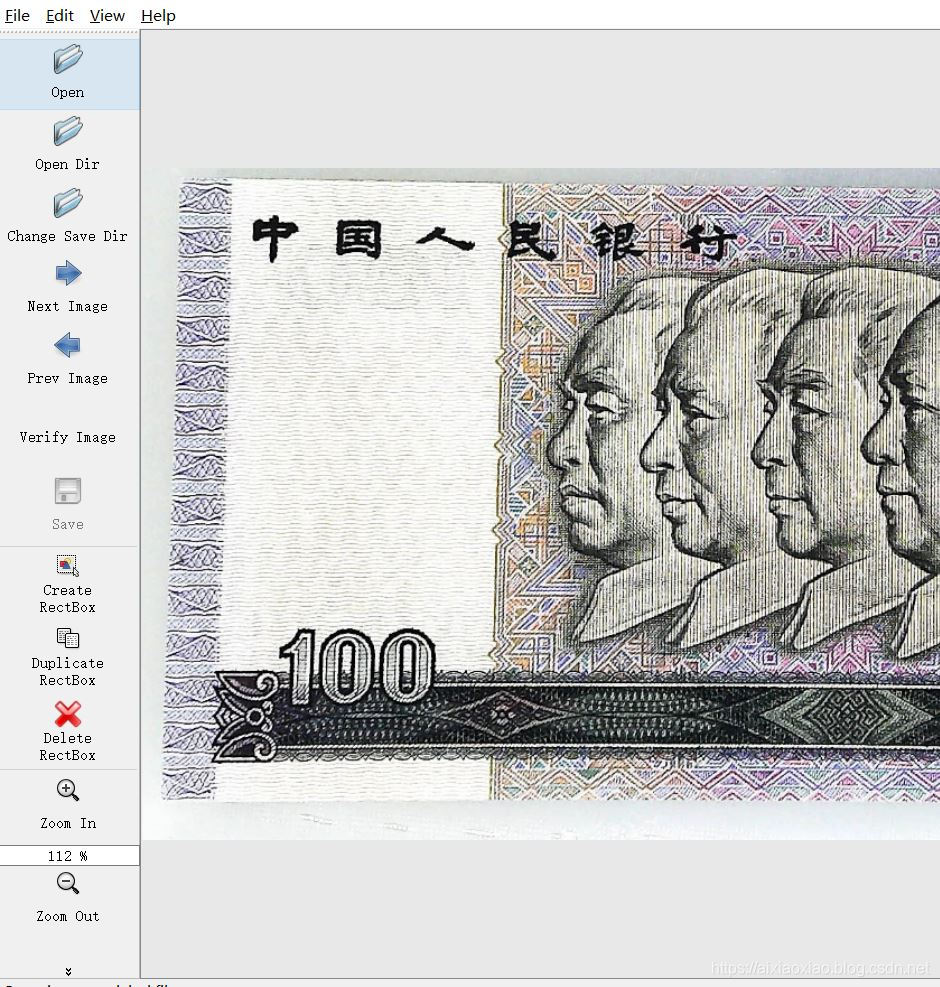
用起来也比较简单,设置导入导出目录,然后就可以点那个Creat RectBox创建标注框了,快捷键是W,下一张图片的快捷键是D。
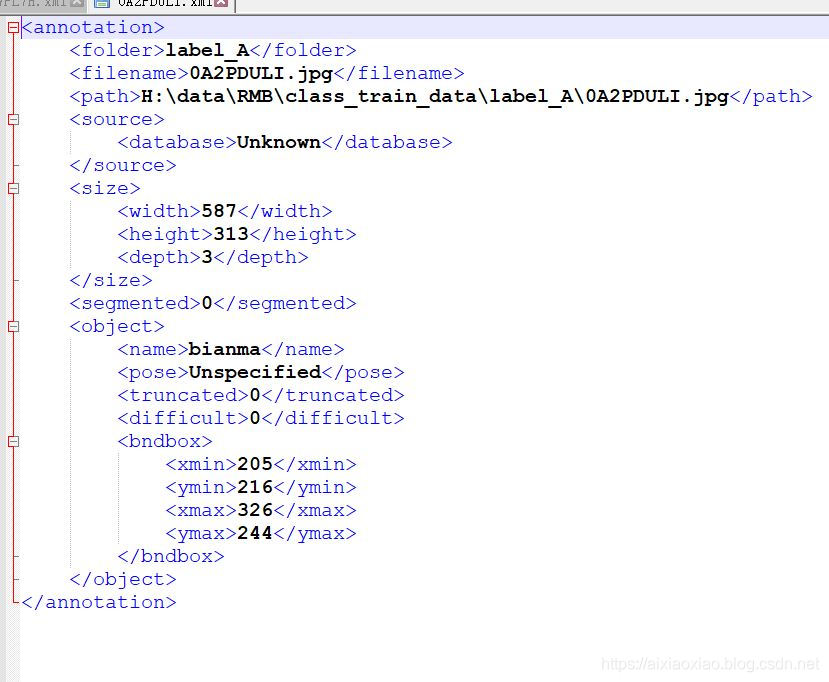
创建完之后生成了许多的xml文件,打开是这个样子,到时候用脚本将里边的信息提取出来,包括图片目录,四个方向的坐标,还有类别。
当我们训练的时候,导入的txt文件的格式应该是这个样子:
图片地址 x_min,y_min,x_max,y_max,类别序号
如果有很多类就在后边叠加,不过得用空格隔开
我整理成了这个样子:

因为我只有一个类别,所以最后那个都是0,我的脚本里甚至都没有提取类别,因为每个人的需求都不一样,最好是从官方给的文件上改,不然越改越乱,我这里把自己的脚本粘贴出来,用作参考:
import xml.etree.ElementTree as ET
xml_dir = 'H:\data\RMB\class_train_data\\xml_data'
def convert_annotation(xml_dir, image_id, list_file): #对每个XML文件的信息进行提取
in_file = open('{0}/{1}'.format(xml_dir, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
path = root.find('path').text
list_file.write(path)
error_bool = False
for obj in root.iter('object'):
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
if len(b)!=4:
error_bool = True
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(0))
return error_bool
import os
lists = os.listdir(xml_dir)
list_file = open('RMB_train.txt', 'w')
for xml in lists:
error_bool = convert_annotation(xml_dir,xml,list_file)
list_file.write('\n')
list_file.close()
if error_bool == False:#检查数据是否由五个数构成 xmin,ymin,xmax,ymax,class
print('转换成功!')
else:
print('出错啦!')
训练模型
训练模型的话要找到train.py这个文件,这里说一下我训练时会经常用到的参数,
annotation_path = 'train.txt'
log_dir = 'logs/000/'
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'model_data/yolo_anchors.txt'
首先是这四个,
annotation_path就是你刚刚用脚本转化过来的训练集txt文件
log_dir这个要放好,你训练的时候他会生成一些日志和模型(可以当做是备份),你最后训练好的模型也会放到这个目录里
classes_path 就是你训练集的类别,看一看这个文件就知道怎么写了,把你的类放进去就行了,我就一个类所以就写了一行
bianma
anchors_path 这里有两个选择,一个是tiny版,六类锚生成,一个是正常版有九类锚,当然是九个的比六个的效果好,但是六个的比九个的快一点,就是这么个样子,你要是问我锚是啥,这个就不好解释了,可以去了解一下Yolo3的原理
input_shape = (416,416) 输入的尺寸,到时候会把你的图片自动调成这个尺寸,没啥事最好就不改了,要改的话最好是32的倍数
if is_tiny_version:
model = create_tiny_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path='model_data/tiny_yolo_weights.h5')
else:
model = create_model(input_shape, anchors, num_classes,
freeze_body=2, weights_path='model_data/yolo_weights.h5')
下边是这个,这是两个版本,因为锚的数量不同,导入的模型也不同,需要注意的是freeze_body,weights_path两个参数,
我们先讲一下yolo的模型,yolo一共252层,如果freeze_body设置为1,那么他训练的时候就会将前185层冻结起来,意思就是你只能训练185层之后的参数,如果设置为2,那么就只会解冻后三层,只用后三层来训练,当然也可以设置成其他数,那就是全部解冻,不过这样不可靠,后边官方是给了全部解冻的代码的。
weights_path是你之前生成的darknet53_weight.h5的地址,如果你想要的在其他模型上训练,也可以改成其他模型的地址,比如你训练过一次的模型,你想再训练一次
val_split 表示验证集所占的比例,如果你的训练集不多的话就是0.1就好了,如果多的话可以设成0.3。
再往后有两个if语句:
if True:
model.compile(optimizer=Adam(lr=1e-3), loss={
# use custom yolo_loss Lambda layer.
'yolo_loss': lambda y_true, y_pred: y_pred})
batch_size = 32
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[logging, checkpoint])
model.save_weights(log_dir + 'trained_weights_stage_1.h5')
其实差不多,两个不要都设置成True,前一个是用来做迁移训练的,也就是只训练一部分,后一个是重新训练,它把所有的层都解冻了,因为这行代码,要是显卡够用可以爽一爽
for i in range(len(model.layers)):
model.layers[i].trainable = True
顺便说一下上边的参数,
optimizer=Adam(lr=1e-3)这里边是学习率,只需要改lr参数就行1e-3是科学计数法0.001,要随着训练减小学习率,多次训练的话可以试着在后边多叠加几次这几行代码
batch_size是一批次多少个图片的意思,也就是想同时训练多少个图片,如果显卡不够可以减小这个
steps_per_epoch,validation_steps是指一轮中要训练多少批
epochs是要训练几轮,训练一下就知道啥意思了
initial_epoch是从第几轮开始,感觉没啥实际意义
到后边就没啥了,不过我觉得这部分有点瑕疵,就是只能看日志来确定训练的好不好,一点都不直观,我给他加了一个方法:
import matplotlib.pyplot as plt
def show_history(history,log_dir,pic_name):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
# 损失
plt.figure(0)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.savefig('{0}{1}.png'.format(log_dir,pic_name))
plt.show()
这样就可以把结果画出来了,用的时候这么用
if is_retrain == False :
model.compile(optimizer=Adam(lr=1e-5), loss={
# use custom yolo_loss Lambda layer.
'yolo_loss': lambda y_true, y_pred: y_pred})
batch_size = 16
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
history = model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=30,
initial_epoch=0,
callbacks=[logging, checkpoint])
model.save_weights(log_dir + 'trained_weights_stage_1.h5')
show_history(history,log_dir,'model1')
这样我们就能看到结果了
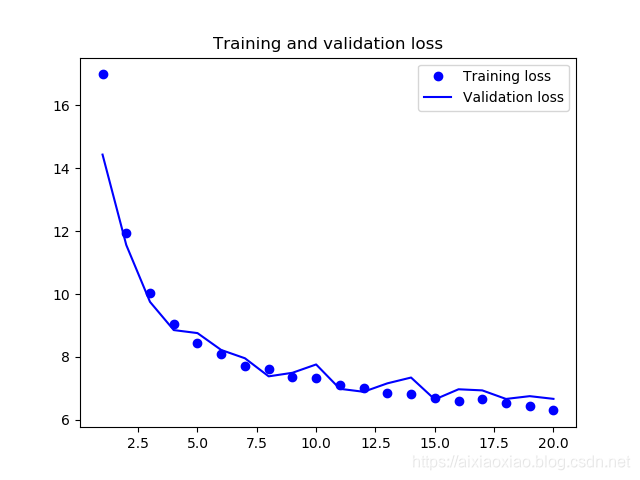
看到它在进步是不是很开心哈哈哈哈啊哈哈哈
最后在日志里生成很多文件,如下:
进行识别
Yolo分为图片识别和视频识别,我们需要用到yolo.py 和yolo_video.py两个文件
理论上这些东西都是用CMD来进行使用的,但是我觉得字有点多,我就喜欢鼠标点点点,所以需要从文件里改东西,打开yolo_video.py从里边找到这段代码:
parser.add_argument(
'--image', default=False, action="store_true",
help='Image detection mode, will ignore all positional arguments'
)
这在问你需要什么模式,我要识别图片,这里默认的False,所以要改成Ture,这样就能直接用来识别图片了
这时候再打开yolo.py
直接就能看到这些参数
"model_path": 'model_data/yolo.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/coco_classes.txt',
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 1,
model_path是你之前训练好的模型
score是分数线(我是这么想的),当你识别物体的时候,高于这个分的他会给你显示出来,低于这个分的就会屏蔽掉了,是不是很像分数线
iou你预测矩形框和真实目标的交集与并集之比,越大越好
有时候你测不出来东西,就把这两个数调小一点就出来了
然后直接运行yolo_video.py就行了,一会会让你输入图片地址,你输入一个,它测试一个,有需求的话就要自己改一下代码了,不要把结果想的太好
我最后识别出来的图片是这样的,因为我已经把代码改的有点面目全非了,所以用labelimage形容一下:



怎么说呢,我总结了一下原因:
1.我训练集标的不标准
2.我训练集数量太少了
3.这是文字,特征不太统一
4.这是yolo,当然没有faster r-cnn准啦
不过也不是不能用,我将结果处理了一下还是能用的:


很神奇对不对,要问我怎么做的,我才不告诉你。
