前言:本章针对工作中比较常用的几种排序算法进行了总结,主要有直接插入排序,冒泡排序,简单选择排序以及快速排序四种算法,从算法基本思想,各种排序的过程示意图,代码示例,最后再分析了算法的空间,时间复杂度以及稳定性,本文C代码示例经过测试,可以使用,如果需要获取全面的demo可以通过git 仓库获取https://github.com/github-mcchen/sort/tree/develop
一:直接排序
1. 插入排序的基本思想:在一个已排好序的记录子集的基础上,每一步将下一个待排序的记录有序的插入到已排好序的记录子集中,知道将所有待排序记录全部插入为止。例如:打扑克牌时的抓牌就是插入排序的一个例子,每抓一张牌,插入到合适位置,知道抓完牌为止,即可得到一个有序序列。下面的示意图演示直接排序算法的排序过程
2. 直接插入排序示意图

3. 算法实现
/**
* @brief 直接插入排序
* @param data
* @param length
* @return 成功 = E_OK 其它 = E_ERROR
*/
int insert_sort(RecordType data[], int length)
{
RecordType tmp;
int i, j;
if (NULL == data)
{
return E_ERROR;
}
tmp = data[i];
for (i = 1; i < length; i++)
{
tmp = data[i];
j = i-1;
while ( (j >= 0) && (tmp < data[j]) )
{
data[j+1] = data[j];
j --;
}
data[j+1] = tmp;
}
return E_OK;
}4. 算法分析:
空间复杂度:排序过程只需要借用一个辅助空间tmp,其空间复杂度为S(n) = O(1)。
时间复杂度:直接插入排序的时间耗费在比较和移动记录上,最好的情况是比较次数为n-1,移动次数为0,最坏的情况是待排序记录为逆序排列,第i趟时第i个记录必须与前面i-1个记录都做排序码的比较,并且每做一次比较就要做一次数据移动,则在最坏的情况下排序码的排序码比较次数KCN和元素移动次数RMN分别为:

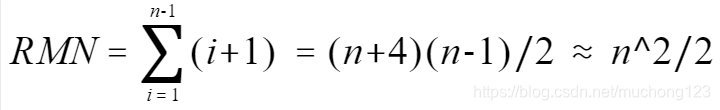
若待排序记录是随机的,即待排序记录可能出现的各种排序的概率相同,则可以取上述最小值和最大值的平均值,约为n^2/4,因此直接插入排序的时间复杂度T(n) = O(n^2)。
稳定性:直接插入排序算法是稳定的排序算法,由于待插入元素的比较是从后向前进行的,这样保证了后面出现的记录不可能插入到与前面相同的记录之前,因此保证了直接插入排序算法的稳定性
二:冒泡排序
1. 冒泡排序的基本思想:冒泡排序是一种简单的交换类排序算法,它是通过对相邻的数据记录进行交换,逐步将待排序序列变成有序序列的过程。
2. 冒泡排序示意图


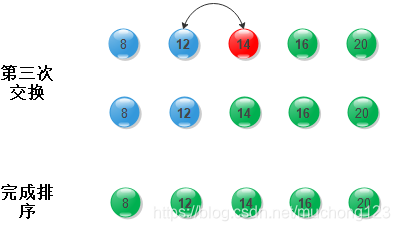
3. 算法实现
/**
* @brief 冒泡排序
* @param data
* @param length
* @return 成功 = E_OK 其它 = E_ERROR
*/
int bubble_sort(RecordType data[], int length)
{
RecordType tmp;
int i, j;
bool change = E_TRUE;
if (NULL == data)
{
return E_ERROR;
}
for (i = 0; i < length-1 && change; i++)
{
change = E_FALSE;
for (j = 0; j < length-i-1; j++)
{
if (data[j] > data[j+1])
{
tmp = data[j];
data[j] = data[j+1];
data[j+1] = tmp;
change = E_TRUE;
}
}
}
return E_OK;
}4. 算法分析
空间复杂度:排序过程只需要借用一个辅助空间tmp,其空间复杂度为S(n) = O(1)。
时间复杂度:冒泡排序算法最坏的情况是待排序记录是逆序序列,此时,第i躺冒泡排序需进行n-i次比较,3(n-i)次移动,经过n-1躺排序后,总的比较次数为KCN,总的移动次数为RMN,因此冒泡排序算法的时间复杂度为O(n^2)。
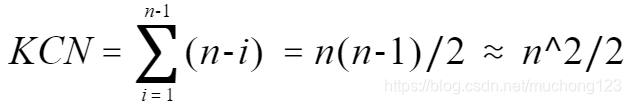
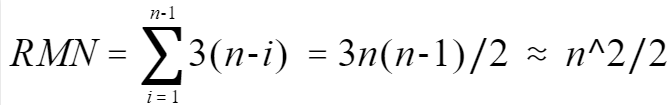
稳定性:冒泡排序是一种稳定的排序算法,因为交换的顺序是从前往后,保证了前面相同的记录不会插入到后面相同记录的后面
三:简单选择排序
1. 简单选择排序算法的思想:第i趟简单选择排序时,从第i个记录开始,通过n-i次记录的比较,从n-i+1个记录中选出关键字最小的记录,并和第i个记录进行交换,经过n-1趟简单选择排序,将把n-1个记录排到位,剩下一个最小记录直接在最后,所以共需进行n-1趟简单选择排序
2. 简单选择排序示意图
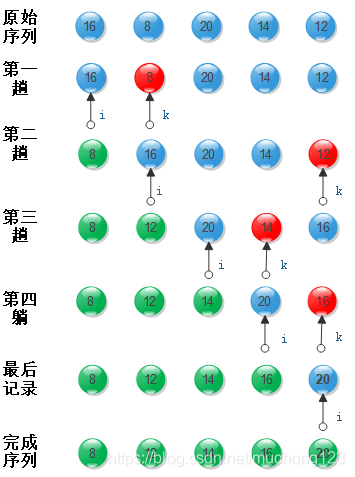
3. 算法实现
/**
* @brief 简单选择排序
* @param data
* @param length
* @return 成功 = E_OK 其它 = E_ERROR
*/
int select_sort(RecordType data[], int length)
{
RecordType tmp;
int i, j, k;
if (NULL == data)
{
return E_ERROR;
}
for (i = 0; i < length-1; i++)
{
k = i;
for (j = i + 1; j < length; j++)
{
if (data[j] < data[k])
{
k = j;
}
if (k != i)
{
tmp = data[i];
data[i] = data[k];
data[k] = tmp;
}
}
}
return E_OK;
}4. 算法分析
空间复杂度:排序过程只需要借用一个辅助空间tmp,其空间复杂度为S(n) = O(1)。
时间复杂度:在简单选择排序过程中,最好的情况下,即待排序记录初始状态就已经是正序排列,故不需要移动记录,最坏的情况下,即第一个记录最大,其余记录从小到大有序排列,此时移动记录的次数最多,为3(n-1)次。由于简单选择排序的比较次数和初始状态下待排序的记录序列的排列情况无关,当i = 1时,需进行n-1次比较,当i=2时,需进行n-2次比较,故需要进行的比较次数为KCN,所以进行简单排序的时间复杂度为O(n^2)。

稳定性:简单排序算法是不稳定的,如 初始序列为3 3 2, 排序后为2 3 3 ,两个相同记录排序后顺序变了,故是不稳定的。
四:快速排序
1. 快速排序算法基本思想:首先选择一个基准记录作为枢轴,一般选择第一个记录K1,然后将其余关键字小于K1的记录移动到前面,而将关键字大于K1的记录移动到后面,结果将待排序记录序列分成两个子表,最后将关键字为K1的记录插入到其分界线的位置处,这样就完成了一趟快速排序,后面将递归的按照前面的方法继续快速排序,知道所有子表的记录数不超过1为止,此时待排序记录序列就变成了一个有序表
2. 快速排序算法示意图

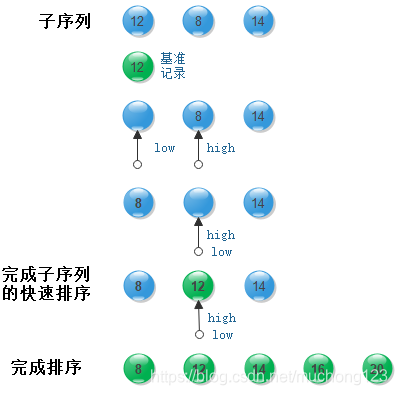
3. 算法实现
/**
* @brief 快速排序
* @param data
* @param low
* @param high
* @return 成功 = 基准记录位置 其它 = E_ERROR
*/
int quick_pass(RecordType data[], int low, int high)
{
RecordType tmp;
if (NULL == data || low > high)
{
return E_ERROR;
}
tmp = data[low];
while (low < high)
{
/*high从右往左寻找小于基准记录的记录*/
while (low < high && data[high] >= tmp)
{
high --;
}
/*找到小于基准记录的记录,则插入到空单元data[low]*/
if (low < high)
{
data[low] = data[high];
low ++;
}
/*low从左往右寻找大于基准记录的记录*/
while (low < high && data[low] < tmp)
{
low ++;
}
/*找到大于基准记录的记录,则插入到空单元data[high]*/
if (low < high)
{
data[high] = data[low];
high --;
}
}
/*将基准记录保存到low=high的位置,并且返回基准记录的位置*/
data[low] = tmp;
return low;
}
/**
* @brief 递归的快速排序
* @param data
* @param low
* @param high
* @return 成功 = E_OK 其它 = E_ERROR
*/
int quick_sort(RecordType data[], int low, int high)
{
int pos;
if (NULL == data || low > high)
{
return E_ERROR;
}
if (low < high)
{
pos = quick_pass(data, low, high);
if (E_ERROR != pos)
{
quick_sort(data, low, pos-1);
quick_sort(data, pos+1, high);
}
else
{
return E_ERROR;
}
}
return E_OK;
}
4. 算法分析
空间复杂度:快速排序递归算法的执行过程对应一棵二叉树,理想情况下是一棵完全二叉树,递归工作栈的大小与上诉递归调用二叉树的深度对应,平均情况下辅助空间复杂度为![]()
时间复杂度:快速排序的最好情况是每趟将排序序列一分两半,正好在表中间,将表分成两个大小相等的子表,其时间复杂度为![]() ,快速排序的最坏情况是已经排好序,第一趟经过n-1次比较,第一个记录定在原位置,左部子表为空表,右部子表为n-1个记录,第二趟n-1个记录经过n-2次比较,第二个记录定在原位,左部子表为空表,右部子表为n-2个记录,以此类推,共需进行n-1趟排序,其比较次数为KCN
,快速排序的最坏情况是已经排好序,第一趟经过n-1次比较,第一个记录定在原位置,左部子表为空表,右部子表为n-1个记录,第二趟n-1个记录经过n-2次比较,第二个记录定在原位,左部子表为空表,右部子表为n-2个记录,以此类推,共需进行n-1趟排序,其比较次数为KCN

稳定性:和简单排序算法一样,快速排序算法也是不稳定的,如 初始序列为3 3 2, 排序后为2 3 3 ,两个相同记录排序后顺序变了,故是不稳定的。
总结:最后谢谢大家的阅读,对于上文总结不到位的地方欢迎评论指正,后续将会针对链表数据结构原理及使用进行总结。
参考资料:《数据结构---用C语言描述》
