- 正则表达式
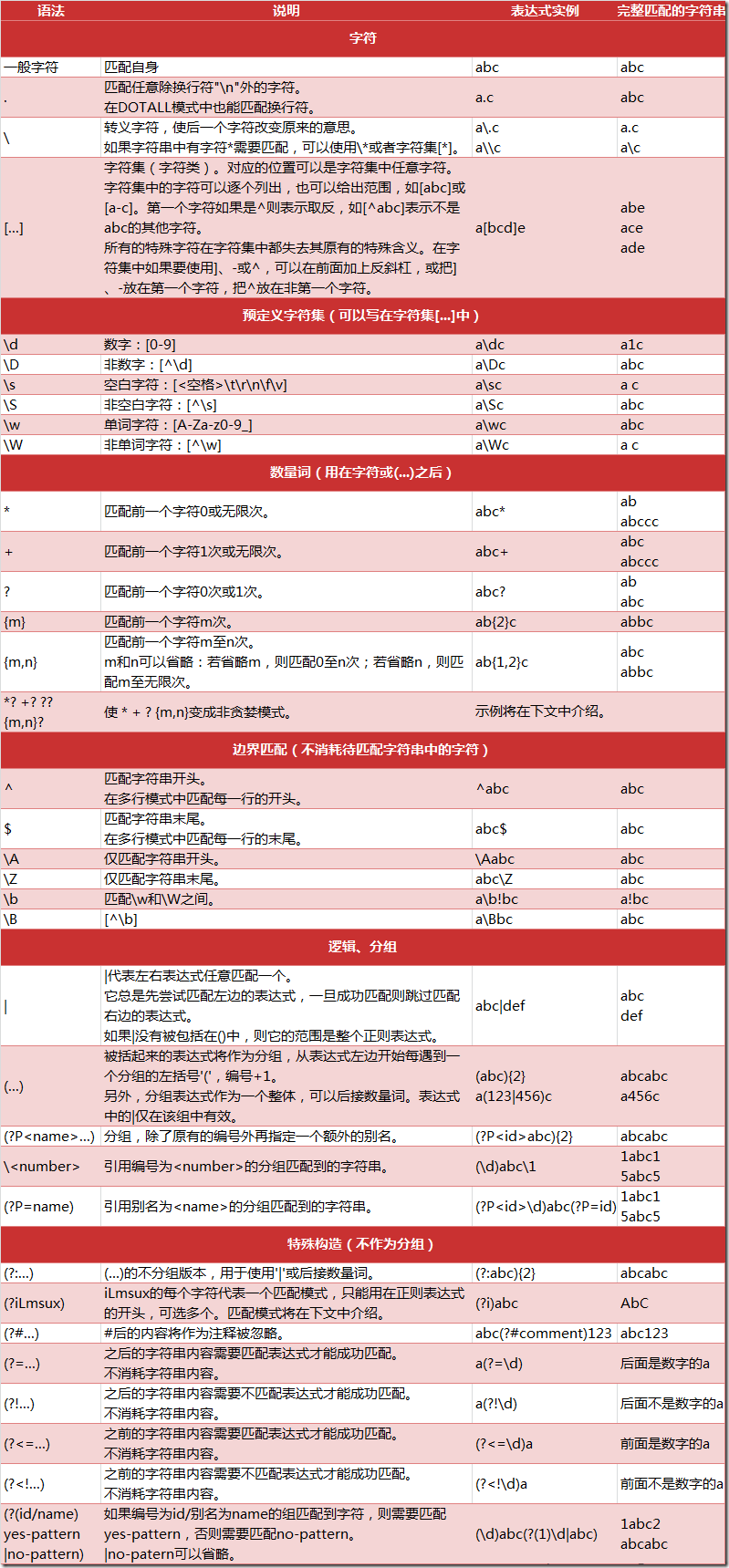
- 数量词的贪婪模式与非贪婪模式
Python中数量词默认是贪婪的,总是尝试匹配尽可能多的字符
例如,正则表达式 "ab*" 如果用于查找 "abbbc",将匹配到 "abbb";如果是非贪婪方式,则会匹配到 "a"
注意:
+或*后跟?表示非贪婪匹配,即尽可能少的匹配
.*? 表示匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复
如:a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab和ab
- re 模块
Python通过re模块提供对正则表达式的支持.
使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作
re模块常用的方法有:re.compile() re.match() re.search() re.findall re.split() re.group()
- re.compile()
compile()函数用于编译正则表达式,生成一个正则表达式(Pattern)对象,供match()和search()这两个函数使用
语法格式为:
re.compile(pattern [, flags])
参数:
patten :一个字符串形式的正则表达式
flags :可选,表示匹配模式,具体有以下6中模式
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为. 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
1 import re 2 3 pattern = re.compile(r"\d+") # 用于匹配至少一个数字 4 # 没匹配到返回None,否则返回一个Match对象 5 r1 = pattern.match("one12twothree34four") 6 print(r1) 7 8 r2 = pattern.match("one12twothree34four", 2, 10) 9 print(r2) 10 11 r3 = pattern.match("one12twothree34four", 3, 10) 12 print(r3) 13 print(type(r3)) 14 15 print("\n") 16 print(r3.group()) # group()方法用于获得获得整个匹配的子串 17 print(r3.start()) # start()获取匹配字串在整个字符串中的起始位置(子串第一个字符的索引) 18 print(r3.end()) # end()获取匹配字串在整个字符串中的结束位置(子串最后一个字符的索引+1) 19 print(r3.span()) # span()方法返回 (start(group), end(group))
None None <_sre.SRE_Match object; span=(3, 5), match='12'> <class '_sre.SRE_Match'> 12 3 5 (3, 5)
- re.match()
re.match 只从字符串的起始位置匹配一个模式
匹配成功re.match方法返回一个匹配的对象,否则返回None
使用group(num) 或 groups() 匹配对象函数来获取匹配表达式
1 import re 2 3 string = "You are beautiful yeah hahaha!" 4 pattern = r"(.*) are (.*?) (.*)" 5 m = re.match(pattern, string) 6 7 if m: 8 print("matchObj.group(): {0}".format(m.group())) 9 print("matchObj.group(1): {0}".format(m.group(1))) 10 print("matchObj.group(2): {0}".format(m.group(2))) 11 print("matchObj.group(3): {0}".format(m.group(3))) 12 else: 13 print("No match !") 14 15 print("matchObj.groups: {0}".format(m.groups()))
matchObj.group(): You are beautiful yeah hahaha! matchObj.group(1): You matchObj.group(2): beautiful matchObj.group(3): yeah hahaha! matchObj.groups: ('You', 'beautiful', 'yeah hahaha!')
- re.search()
re.search() 扫描整个字符串并返回第一个成功的匹配
1 import re 2 3 print(re.search("here", "here you are").span()) 4 print(re.search("here", "you are here").span())
(0, 4)
(8, 12)
- re.match() 与 re.search() 的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配
- re.findall()
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表
注意: match() 和 search() 只匹配1次;而 findall() 会匹配所有
1 import re 2 3 pattern = re.compile(r"\d+") 4 string = "1one2two3three4four" 5 6 r1 = pattern.findall(string) 7 r2 = pattern.findall(string, 5, 15) 8 9 print(r1) 10 print(r2)
['1', '2', '3', '4'] ['3', '4']
- re.split()
split()方法按照能够匹配的子串将字符串分割后返回列表
1 import re 2 3 string = "1one# 2two# 3three# 4four# 5#" 4 print(re.split(" ", string)) # 按空格切 5 print(re.split("#", string)) # 按"#"切
['1one#', '2two#', '3three#', '4four#', '5#'] ['1one', ' 2two', ' 3three', ' 4four', ' 5', '']
- re.sub()
re.sub()用于替换字符串中的匹配项
1 import re 2 3 phone = "2004-959-559 # 这是一个国际号码" 4 5 # 删除字符串中的注释 6 r1 = re.sub(r"#.*$", "", phone) 7 print(r1) 8 9 # 删除非数字的字符串 10 r2 = re.sub("\D", "", phone) 11 print(r2)
2004-959-559 2004959559