文章目录
1.xpath简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历,用来确定XML文档中某部分位置。
2.xpath节点
节点关系
2.1 父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2.2 子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2.3 同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2.4 先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
2.5 后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
3.xpath语法
XML 实例文档
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
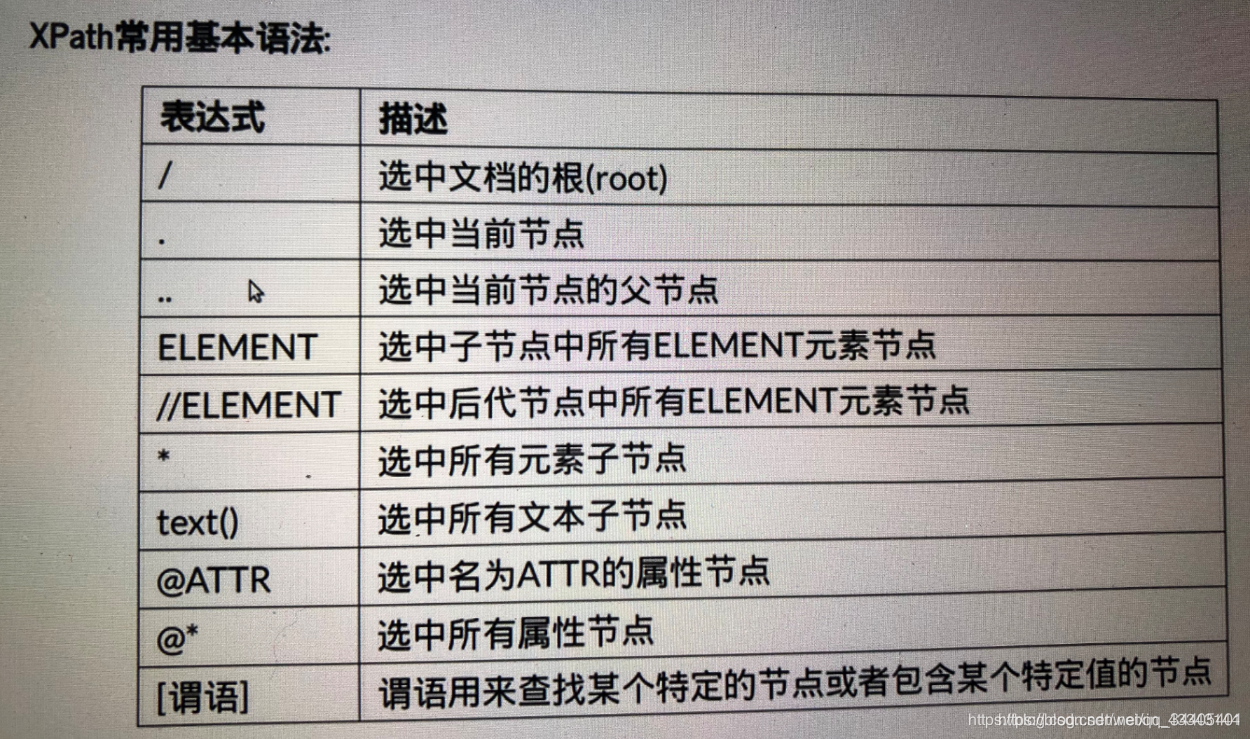
3.1 选取节点
3.1.1 常例
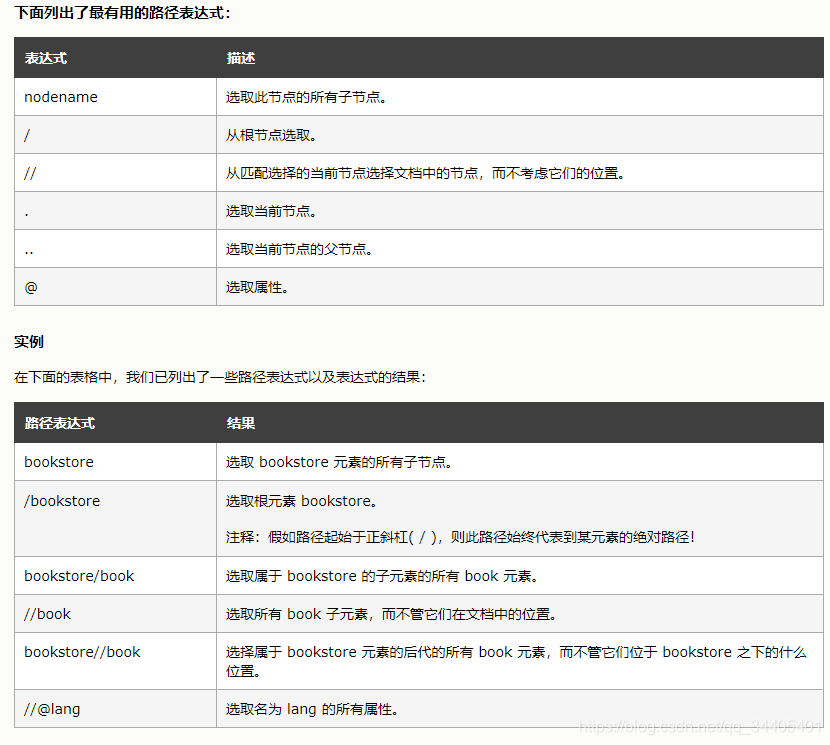
3.1.2 通配

3.1.3 选取多条路径

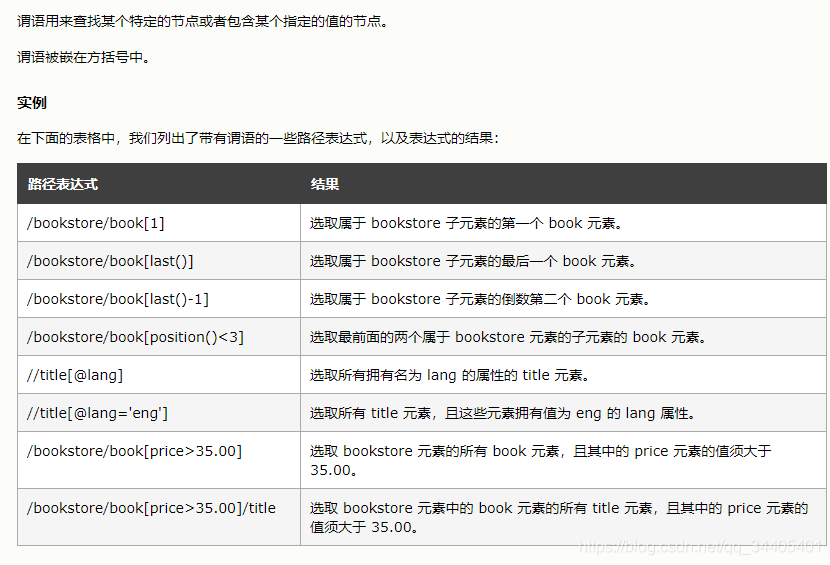
3.2 谓语
4. /text()
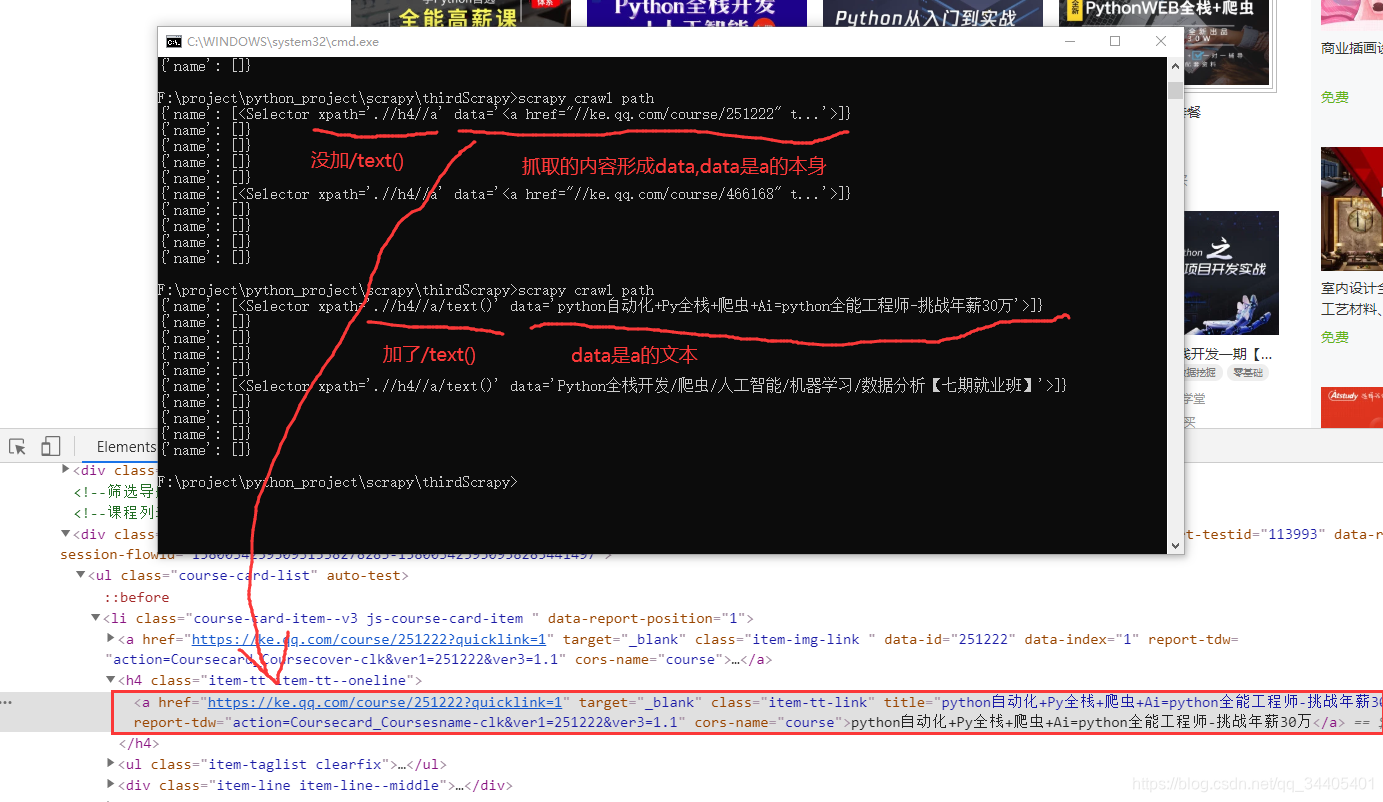
5.extract和extract_first()
注:形成的data属性里的内容就用extract()和extract_first()提取
extract():这个方法返回的是一个数组list,,里面包含了多个string,如果只有一个string,则返回[‘ABC’]这样的形式。
extract_first():这个方法返回的是一个string字符串,是list数组里面的第一个字符串。
