问题描述:df表是学生的刷卡记录数据,df1表是学生的各个课程的绩点数据,现在要计算每个学生的刷卡频数以及其对应的平均绩点。
解决:先用value_counts计算df表的频数,再用groupby计算每个学生的平均绩点,最后再用merge函数连接。

value_counts()计算频数
value_counts是对计算频数的函数需要注意,value_counts生成的结果索引是sfrzh,值是频数,如果需要将索引转化为列还需要转化一下。
import pandas as pd
from datetime import datetime
df = pd.read_csv(r'G:\zhxy\20190921\tsg.csv')
df.head(15)
#计算Sfrzh频数
tsg_count = df['Sfrzh'].value_counts()
tsg_count.head()
d = pd.DataFrame()#转化为数据框
d['XH_ID'] = tsg_count.index
d['tsg'] = tsg_count.values
d.head(10)
d.shape
可以看到结果,左列为Sfrzh,右列为频数

groupby分类汇总
下面进行分类汇总,其中参数by就是我们要对谁进行分类汇总。
对其分类汇总后是要做什么,就在其后面添加什么函数。我们这里是要求均值,就加mean(),如果是求和就sum,或其它需求。
同样的,groupby的结果也是包含index和一列values
df1 = pd.read_csv(r'G:\zhxy\20190921\term_2.csv')
df1.head()
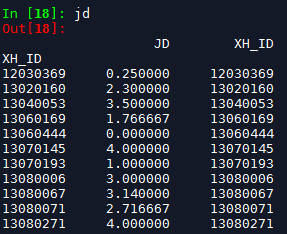
jd = df1[['XH_ID','JD']].groupby(by='XH_ID').mean()#分类汇总
jd.head()
jd['XH_ID'] = jd.index
jd.head()
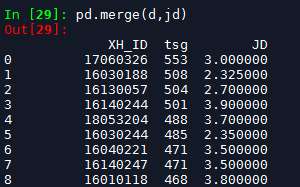
merge匹配
最后进行匹配,如果两个数据表要进行匹配的是列名是相同的,可以不用添加参数,如果不同,需要添加参数left_on,right_on分别对应表要匹配的列名。
参数how默认内连接,把匹配不到的缺失值删掉,可以根据需求设置成外连接。
pd.merge(d,jd)#默认内连接
data = pd.merge(jd,d,how='outer')#外连接
#data = pd.merge(jd,d,left_on='XH_ID',right_on = 'XH_ID',how='outer')#外连接