本文记录了使用python语言中的numpy模块,来对Excel表格数据中的值进行统计的代码,统计全表中某一值或者字符出现的个数,以及某一行,某一列中该值出现的个数。主要使用的函数是.value_counts()。
一、函数介绍
.value_counts() 计数
value_counts( values, sort=True, ascending=False, normalize=False, bins=None, dropna=True)
| 参数名 | 作用 |
|---|---|
| sort=True | 是否要进行排序(默认:进行排序) |
| ascending=False | (默认:降序排列) |
| normalize=False | 是否要对计算结果进行标准化,并且显示标准化后的结果(默认:False) |
| bins=None | 可以自定义分组区间(默认:否) |
| dropna=True | 是否删除缺失值nan(默认:删除) |
二、.value_counts()对一列数据计数
有时候,运算结果中间不完全显示,有人称为“截断数据”。我们把数据输出为csv,输出函数加上mode=‘a’就可以看到全部数据了
输出数据:

将结果全部输出为csv后可以全部看到
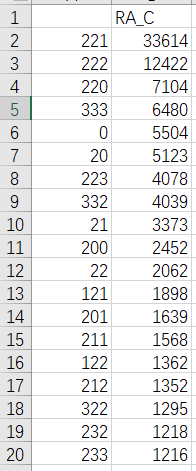
df = df["RA_C"].value_counts()
print(df)
df.to_csv("df.csv",mode='a')
三、统计多列数据(不同列属性相同)中重复出现的值
对Excel表格全部数据计数, 不只是一列。
pieces = []
for col in dfS.columns:
tmp_series = df[col].value_counts()
tmp_series.name = col
pieces.append(tmp_series)
df_value_counts = pd.concat(pieces, axis=1)
结果如图所示:
每一列的数值出现的次数都有,如果想知道全表格出现的次数,就求和。

#将NaN填充为0
df = df_value_counts.fillna(0)
#添加新的一行:对每一行求和
df["Total"] =df.apply(lambda x:x.sum(),axis =1)
#只提取index和Total
df = df[['Total']]
# 只显示df的前5行
print(df.head())
# 将结果输出为csv文件
df.to_csv("result_3.csv",mode='a')
结果如下:可知数值221出现在excel表中的数目为132825次,222出现94924次,220出现9276次…

输出结果在Excel中排序,就可以知道数值的多少了
.value_counts()
四、统计多列数据(不同列属性不同 )中重复出现的值
输入:

输出:计数结果

import pandas as pd
import os
os.chdir(r'C:\Users\Administrator\Desktop')
df = pd.read_excel('数据.xls')
def fun(df):
dic = {
}
for i in df.columns:
dic[i] = df[i].value_counts()
return dic
dd = fun(df)
# 写入excel
import xlwt
f = xlwt.Workbook() #创建工作薄
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True) #创建sheet
pattern = xlwt.Pattern()
pattern.pattern = xlwt.Pattern.SOLID_PATTERN
pattern.pattern_fore_colour = 5
style = xlwt.XFStyle()
style.pattern = pattern
al = xlwt.Alignment()
al.horz = 0x02 # 设置水平居中
al.vert = 0x01 # 设置垂直居中
style.alignment = al
# 获取字典的键
list_ = [k for k in dd]
k=0
l=0
for s in range(len(dd)):
l=k+1
# 写入第一行
sheet1.write_merge(0, 1, k, l,list_[s] , style)
# 写入内容
j = 2
for v,h in zip(dd[list_[s]],dd[list_[s]].index):
sheet1.write(j,k,h) #循环写入 竖着写
sheet1.write(j,l,v) #循环写入 竖着写
j=j+1
k=k+3
f.save('统计数据.xls')#保存文件