4.使用聚合操作对数据异常值检测和过滤
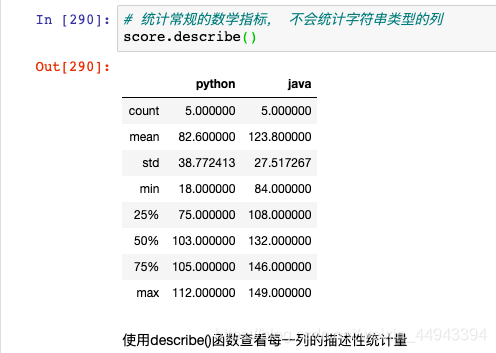
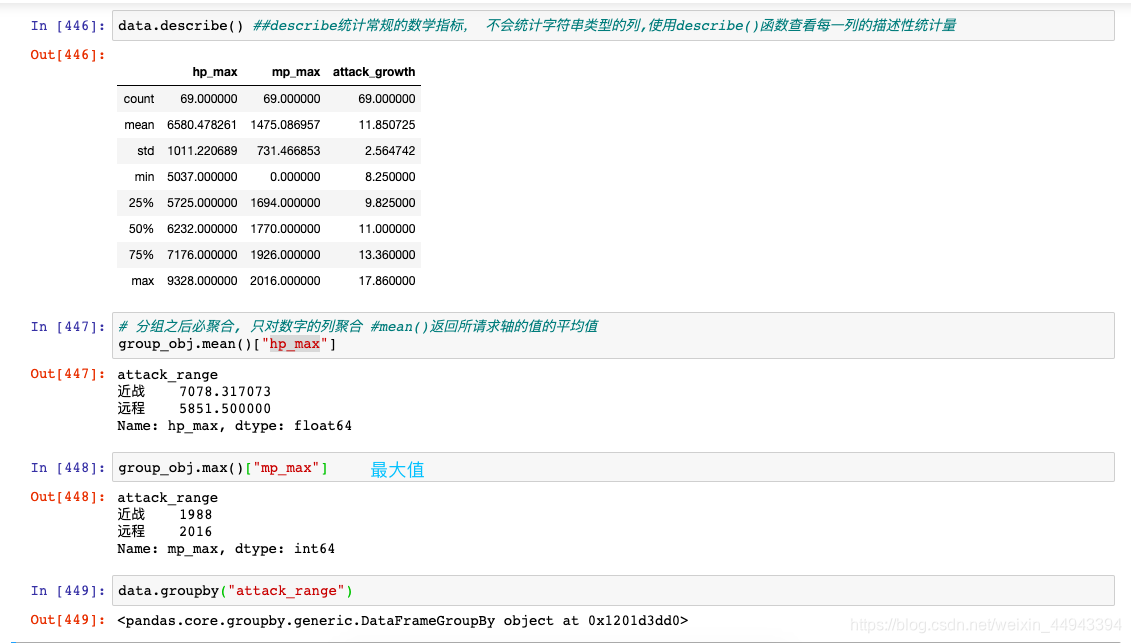
4.1:describe
A.使用函数:DataFrame.describe(self,percentiles = None,include = None,exclude = None )
B.参数解析:

C.实战:
C1.官方例子
C2.
E.小节练习
5.排序
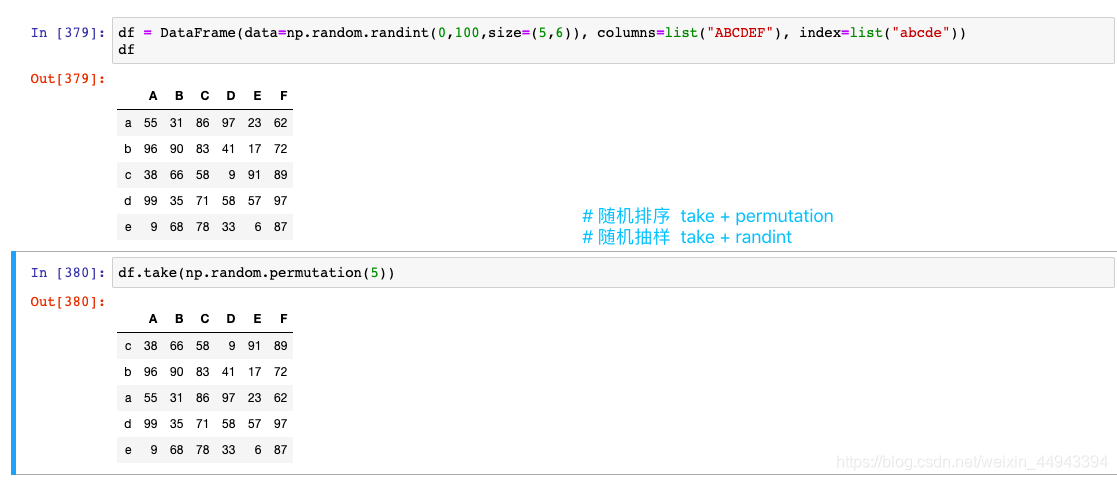
A.使用函数:DataFrame.take(self,index,axis = 0,is_copy = True,** kwargs )沿轴返回给定位置索引中的元素。
-----take()函数接受一个索引列表,用数字表示
-----eg:df.take([1,3,4,2,5])
-----可以借助np.random.permutation()函数随机排序
B.参数解析:

C.实战:
C1.官方链接
C2.
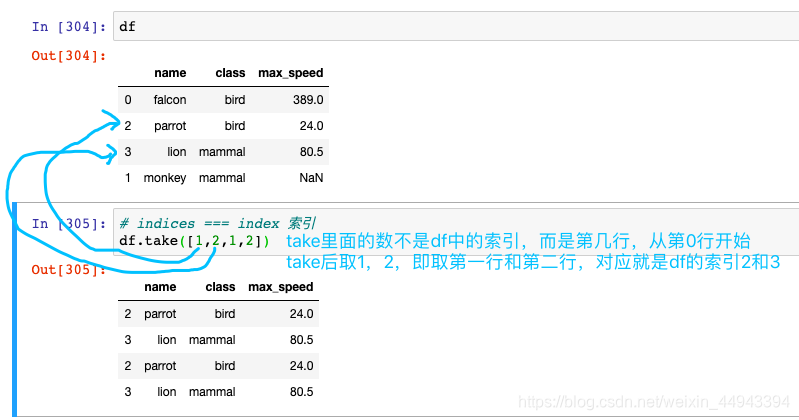
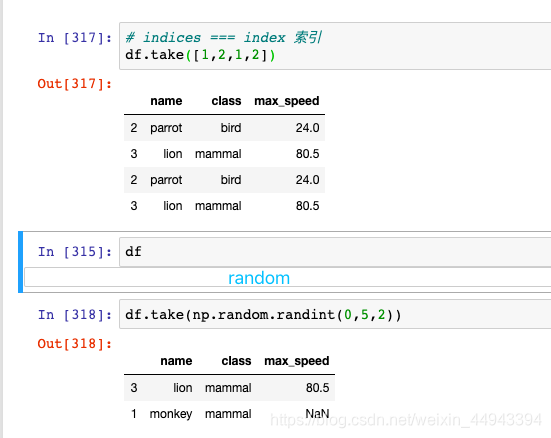
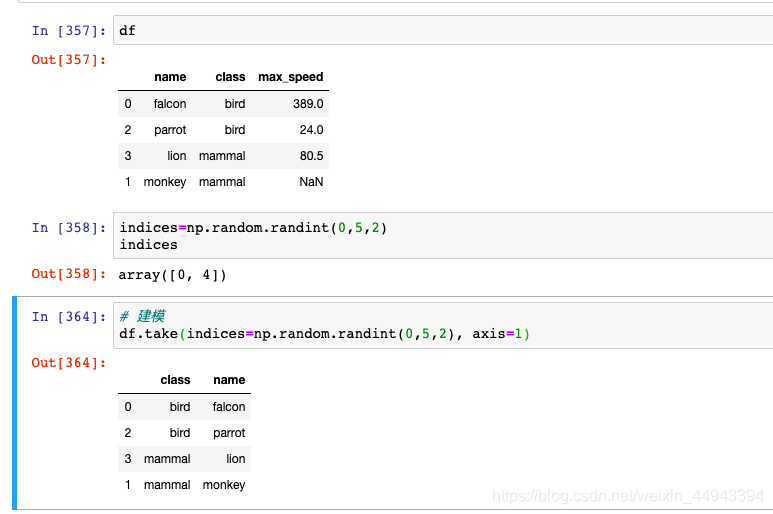
C3.随机排序、抽样
E.小节练习
5.数据分类/组处理groupby高级数据聚合
A.使用函数:Series.groupby(self,by = None,axis = 0,level = None,as_index = True,sort = True,group_keys = True,squeeze = False,观察到的False,** kwargs )
B.参数解析:

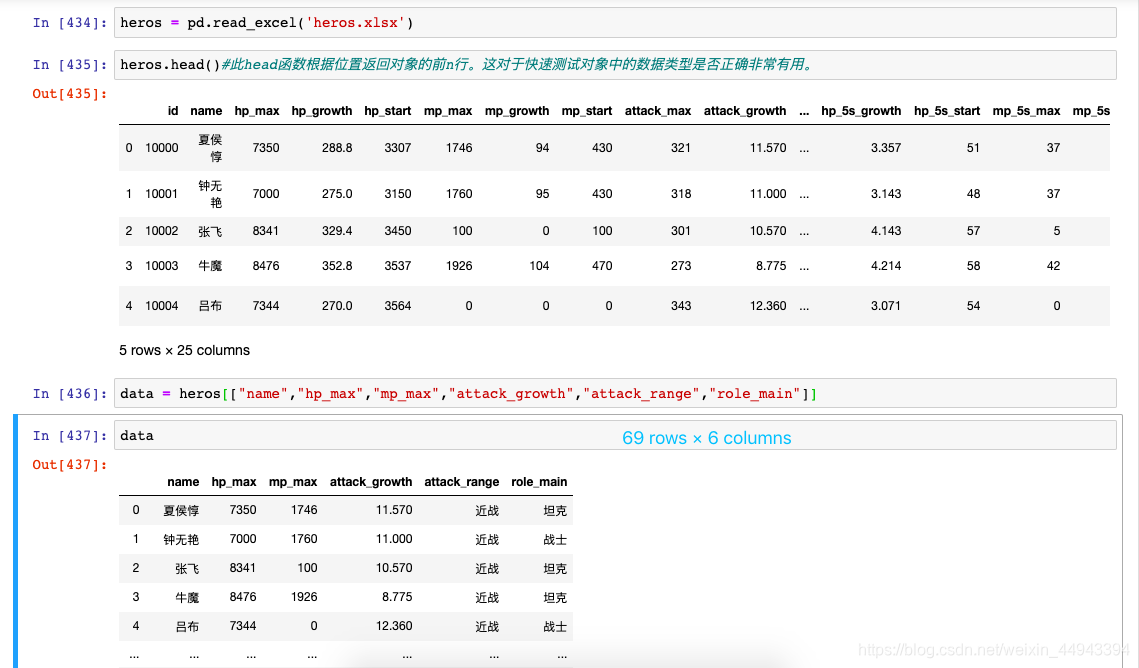
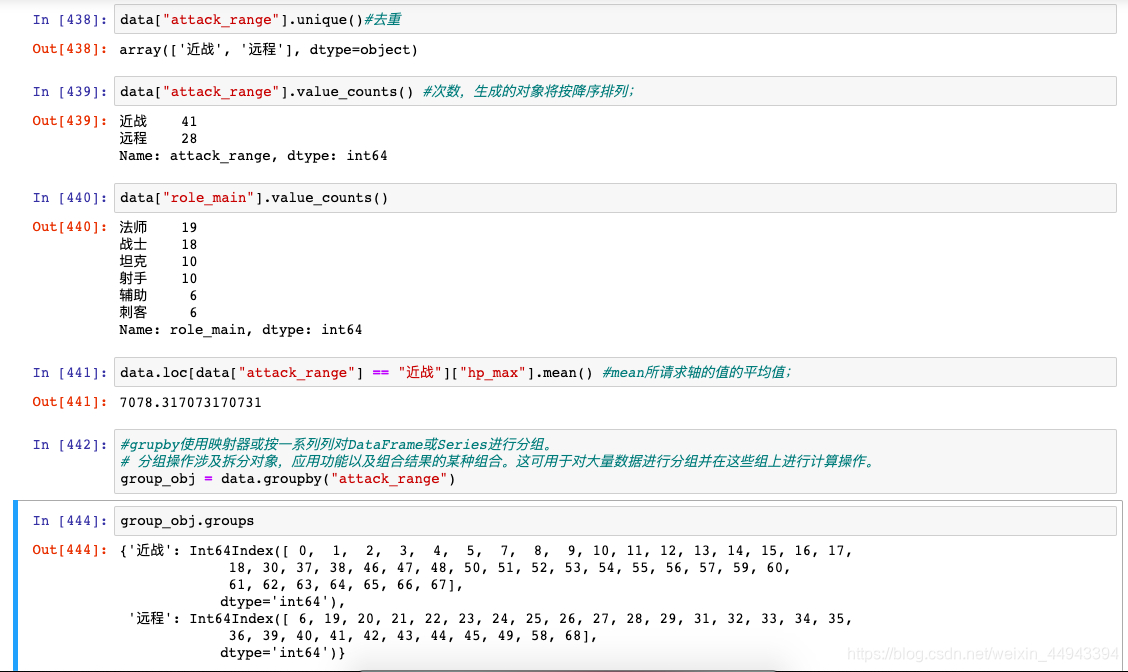
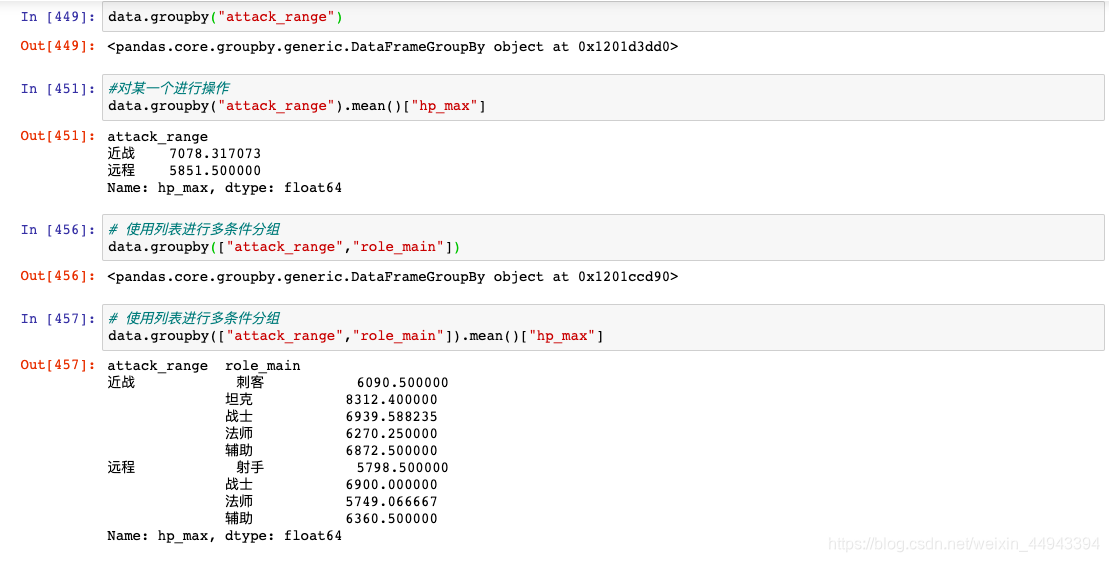
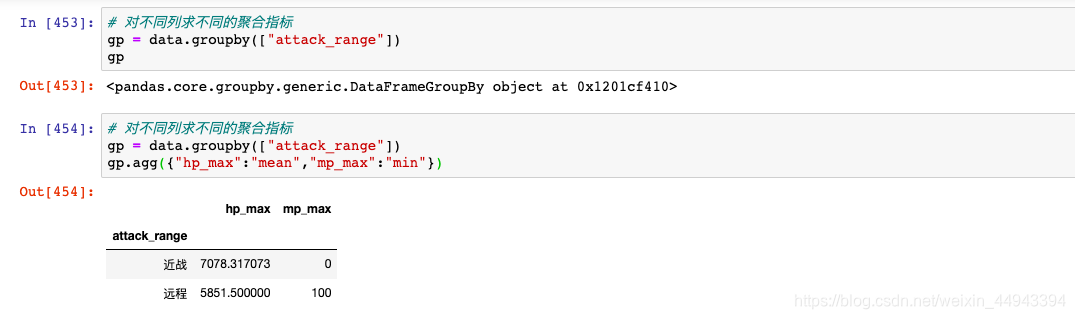
C.例子:
C1.官方例子
C2.
D.小节
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
-----分组:先把数据分为几组
-----用函数处理:为不同组的数据应用不同的函数以转换数据
-----合并:把不同组得到的结果合并起来
数据分类处理的核心:
-----groupby()函数
-----groups属性查看分组情况
E.小节练习
6.高级数据聚合
A.使用函数:DataFrame.groupby(self,by = None,axis = 0,level = None,as_index = True,sort = True,group_keys = True,squeeze = False,观察到的False,** kwargs )
B.参数解析:

C.说明:
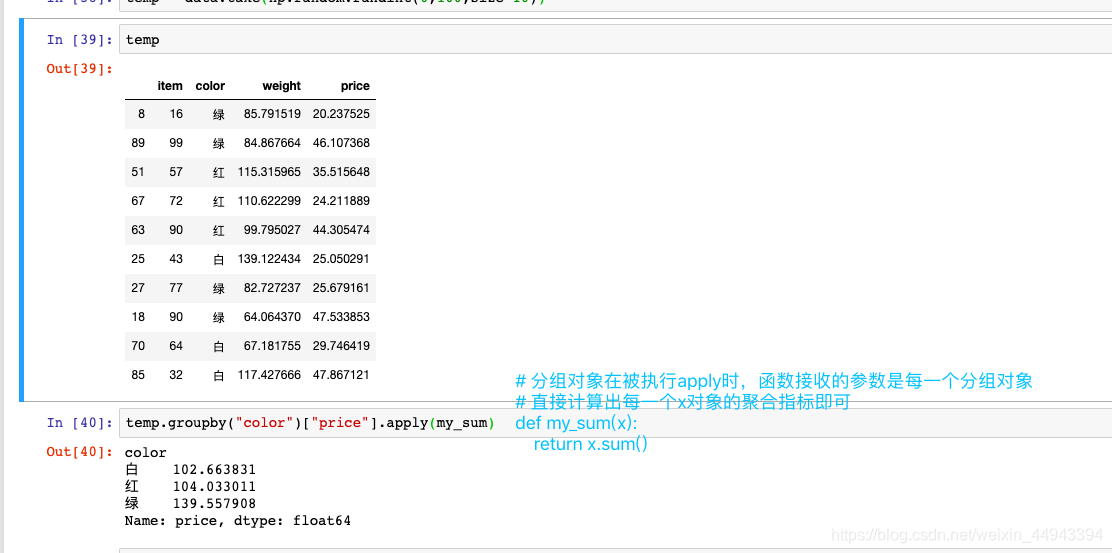
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
----df.groupby(‘item’)[‘price’].sum() 和 df.groupby(‘item’)[‘price’].apply(sum) 差不多
----transform和apply都会进行运算,在transform或者apply中传入函数即可
----transform和apply也可以传入一个lambda表达式
D.实战例子:
D1.百度一篇跟高级数据聚合相关的文章,放此方便观看啦
D2.
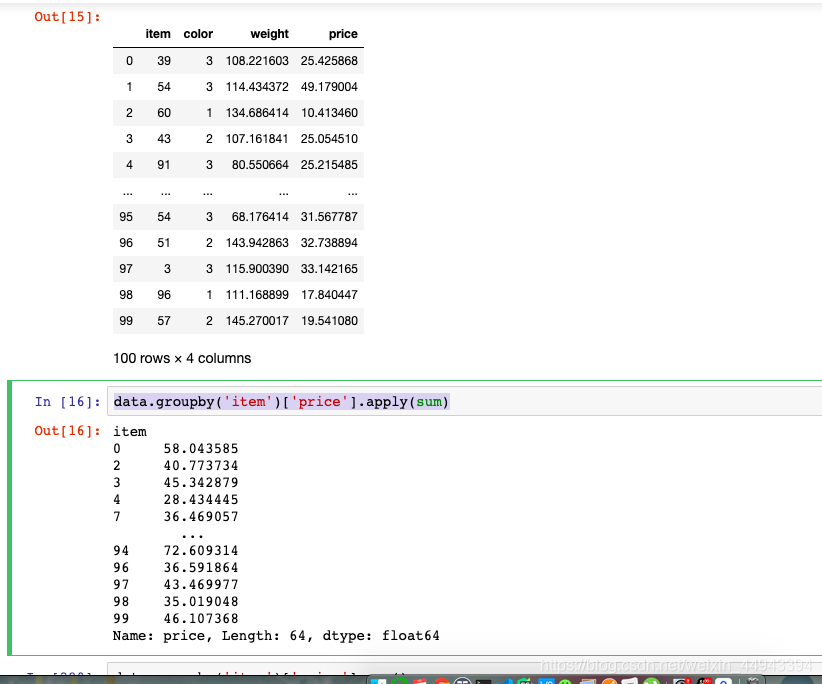
data.groupby(‘item’)[‘price’].apply(sum)
按照item分组,取price列,求每组的price的sum
apply
transform
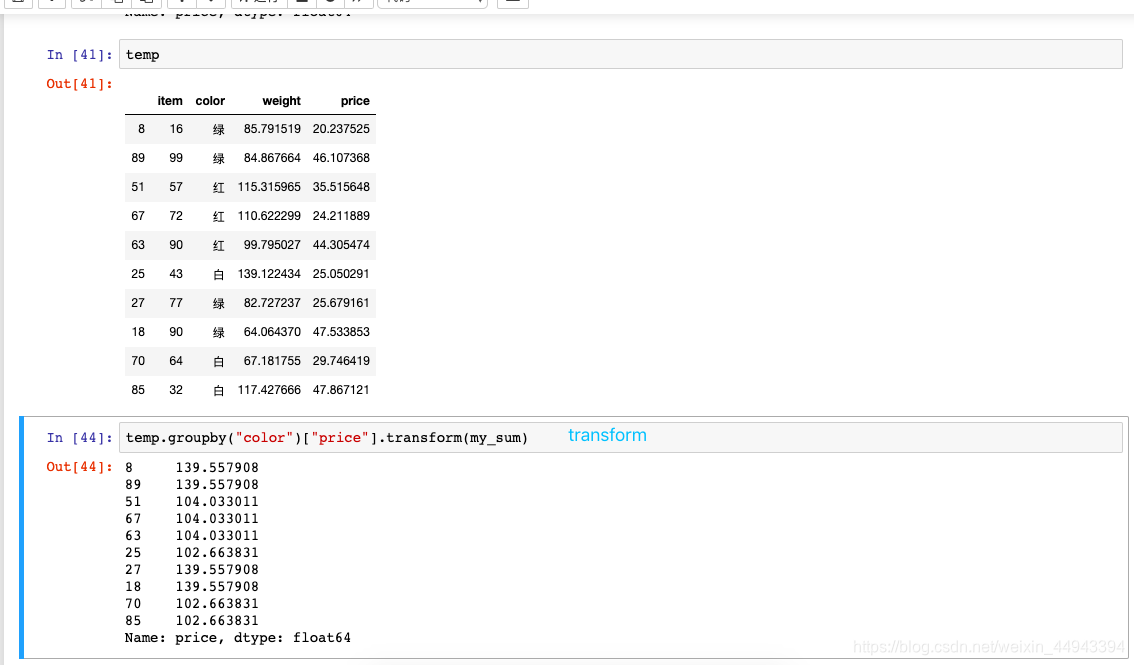
**transform 会自动匹配列索引返回值,不去重;apply 会根据分组情况返回值,去重。
编者寄:内容源于学习资料整理;
文章面向小白也可能会被行业前辈看到,为避免知识误导,若文章有错误,还请过路朋友指出,末学好及时更正,评论区见~
