联合主键表—实体类(JPA)
先创建一个主键类
package com.siid.webapi.device.domain;
import lombok.Data;
import java.io.Serializable;
@Data
public class GeoWayRegionPK implements Serializable {
private int wayId;
private String regionId;
}
再来写它的实体类
package com.siid.webapi.device.domain;
import lombok.Data;
import lombok.EqualsAndHashCode;
import org.hibernate.annotations.DynamicUpdate;
import javax.persistence.*;
import java.io.Serializable;
import java.sql.Timestamp;
@Data
@Entity
@Table(name="geo_way_region")
@IdClass(GeoWayRegionPK.class)//注意将主键类导入
@DynamicUpdate
public class GeoWayRegionEntity {
private int wayId;
private String regionId;
private String addUser;
private Timestamp addTime;
@Id
@Column(name="way_id")
public int getWayId() {
return wayId;
}
public void setWayId(int wayId) {
this.wayId = wayId;
}
@Id
@Column(name="region_id")
public String getRegionId() {
return regionId;
}
public void setRegionId(String regionId) {
this.regionId = regionId;
}
@Basic
@Column(name="add_user")
public String getAddUser() {
return addUser;
}
public void setAddUser(String addUser) {
this.addUser = addUser;
}
@Basic
@Column(name="add_time")
public Timestamp getAddTime() {
return addTime;
}
public void setAddTime(Timestamp addTime) {
this.addTime = addTime;
}
private GeoWayEntity geoWayEntity;
@ManyToOne//这个是外键的写法
@JoinColumn(name="way_id",updatable = false,insertable = false)
public GeoWayEntity getGeoWayEntity() {
return geoWayEntity;
}
public void setGeoWayEntity(GeoWayEntity geoWayEntity) {
this.geoWayEntity = geoWayEntity;
}
}
@Data 注解:
在类名上加@Data注解,导入依赖:lombok.Data。
在另一个类中导入该入参类后,通过activityListParam.是可以点出没有写的Get,Set等方法。
因此,@Data注解在类上时,简化java代码编写,为该类提供读写属性,还提供了equals(),hashCode(),toString()方法。
@IdClass 注解:
使复合主键类成为非嵌入类,使用@IdClass 批注为实体指定一个复合主键类(通常由两个或更多基元类型或 JDK 对象类型组成)。
@DynamicUpdate注解:
动态更新数据库中的数据
跨时间节点、模糊查询(JPA)?
跨时间节点的查询
以下是xxxRepository.java的代码,注意sql语句的写法
package com.siid.webapi.device.repository;
import com.siid.webapi.device.domain.DevicePropertyEntity;
import com.siid.webapi.device.domain.DevicePropertyLogEntity;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import java.sql.Timestamp;
import java.util.List;
public interface DevicePropertyLogRepository extends JpaRepository<DevicePropertyEntity, String> {
List<DevicePropertyLogEntity> findAllById(List<Integer> id);
List<DevicePropertyLogEntity> findAllByDeviceId(List<Integer> id);
@Query("select p from DevicePropertyLogEntity as p where (p.deviceId = ?1)" +
" and (p.name like %?2% or p.dataKey like %?2%)" +
" and (p.lastTime between ?3 and ?4) order by p.lastTime desc")//将查询结果按降序排列
Page<DevicePropertyLogEntity> findByDeviceIdAndKeyword(int deviceId, String queryStr, Timestamp from, Timestamp to, Pageable pageable);
}
以下是在xxxServiceImpl中应用xxxRepository中的方法的代码
@Override
public PagedList<DevicePropertyModel> getHistoryByDeviceId(int deviceId, String queryStr, int page, int pageSize, LocalDateTime from, LocalDateTime to) {
if(from == null && to == null){
from = LocalDateTime.of(2000,1,1,0,0);
to = LocalDateTime.now();
}
if(from.isEqual(to)){
from = LocalDateTime.of(from.getYear(),from.getMonth(), from.getDayOfMonth(),0,0);
to = LocalDateTime.of(from.getYear(),from.getMonth(), from.getDayOfMonth(),23,59);
}
Pageable pageable = PageRequest.of(page-1, pageSize);
Page<DevicePropertyLogEntity> devicePropertyLogEntities = devicePropertyLogRepository.findByDeviceIdAndKeyword(deviceId, queryStr, Timestamp.valueOf(from), Timestamp.valueOf(to), pageable);
List<DevicePropertyModel> devicePropertyModels = devicePropertyLogEntities.stream().map(p -> {
DevicePropertyModel dpm = new DevicePropertyModel();
dpm.setId(p.getId());
dpm.setDeviceId(p.getDeviceId());
dpm.setDataKey(p.getDataKey());
dpm.setDataValue(p.getDataValue());
dpm.setLastTime(p.getLastTime());
dpm.setName(p.getName());
dpm.setPropertyId(p.getPropertyId());
return dpm;
}).collect(Collectors.toList());
PagedList<DevicePropertyModel> devicePropertyPages = new PagedList<>(devicePropertyLogEntities.getTotalElements(), page, pageSize);
devicePropertyPages.setItems(devicePropertyModels);
return devicePropertyPages;
}
以下是xxxService在xxxController服务接口中应用,注意怎么传递时间参数的
@ApiOperation(value = "获取设备历史数据", response = DevicePropertyModel.class, responseContainer = "PagedList")
@GetMapping(value = "/history/{deviceId}", produces = "application/json")
public PagedList<DevicePropertyModel> getHistoryProperty(@PathVariable("deviceId") int deviceId,
@RequestParam(required = false, defaultValue = "") String queryStr,
@RequestParam(required = false, defaultValue = "1") int page,
@RequestParam(required = false, defaultValue = "20") int pageSize,
@RequestParam(required = false) @DateTimeFormat(iso = DateTimeFormat.ISO.DATE_TIME) LocalDateTime from,
@RequestParam(required = false) @DateTimeFormat(iso = DateTimeFormat.ISO.DATE_TIME) LocalDateTime to) {
return devicePropertyService.getHistoryByDeviceId(deviceId, queryStr, page, pageSize, from, to);
}
模糊查询——like %?2%
以下是xxxRepository.java的代码
package com.siid.webapi.device.repository;
import com.siid.webapi.device.domain.DeviceDetailEntity;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import java.util.List;
import java.util.Optional;
public interface DeviceRepository extends JpaRepository<DeviceDetailEntity, Integer> {
// Page<DeviceDetailEntity> findByDeviceTypeId(int positionTypeId, Pageable pageable);
Page<DeviceDetailEntity> findByModelId(int modelId, Pageable pageable);
Optional<DeviceDetailEntity> findOneByModelIdAndName(int modelId, String name);
@Query(value = "select p from DeviceDetailEntity as p where (p.modelId=?1 or ?1=0) and (p.name like %?2% or p.description like %?2%)")
Page<DeviceDetailEntity> findByModelIdAndKeyword(int modelId, String keyword, Pageable pageable);
DeviceDetailEntity getByName(String name);
}
?2是表示应该带入方法参数列表中传递的第二个参数。
构造PagedList<>()数据结构
以下是一个xxxServiceImp的代码实例
@Override
public PagedList<Device> getAllByModel(String queryStr, int model, int page, int pageSize) {
Pageable pageable = PageRequest.of(page-1, pageSize);
Page<DeviceDetailEntity> deviceEntities = deviceRepository.findByModelIdAndKeyword(model, queryStr, pageable);
List<Device> devices = deviceEntities.stream().map(p ->
{
Device device = new Device(p.getId(), p.getModelId(), p.getName(), p.getDescription(), p.getPositionId(),p.getAddUser());
device.setError(p.isError());
device.setOnline(p.isOnline());
device.setPoint(new GeoPoint(p.getLng(), p.getLat()));
return device;
}).collect(Collectors.toList());
PagedList<Device> devicePage = new PagedList<>(deviceEntities.getTotalElements(), page, pageSize);
devicePage.setItems(devices);
return devicePage;
}
findByModelIdAndKeyword(model, queryStr, pageable)这个方法是在Jpa中自定义的,所以返回结果是一个Page。所以,要直接在xxxServiceImp接口中返回PagedList<>()对象,需要在JPA自定义一个方法,返回Page对象,用Page对象的getTotalElements()方法来获取totla参数值,有参构造PagedList<>().
或者直接用Jpa的方法返回List<>()对象,用它的size()方法获取total参数。
模糊查询(JAP)
public interface DeviceRepository extends JpaRepository<DeviceDetailEntity, Integer> {
@Query(value="select p from DeviceDetailEntity as p where " +
"(p.name like concat(concat('%',?1),'%')) and" +
"(p.id=?2) order by p.id")
DeviceDetailEntity findByName(String queryStr,int deviceId);
}
concat是用来拼接%与查询参数的。
设计多对多关系的数据表
第一种可以在一张表中设置双主键,即可实现多对多的关系。但是表中的数据会变得冗余,且查询数据表的效率会降低。
第二种就是设置外键,在做增删改查时将两张表联立即可,但是在新增和删除操作时要注意外键的限制条件。在新增时,先插主表,再插子表。在删除时,先删子表,再删主表。这里的主表就是指该表的主键,被设置为另一张表中的外键限制条件。这里的子表是指该表有外键限制条件,子表的外键是主表的主键。
第三种就是设置中间表,即是新建一张表,在这个中间表中有另外两张表的主键。即是在中间表中体现那两张表的多对多关系。这样就可让关联的那两张表没有冗余的数据存在,但是在增删改查时较为麻烦,因要不断对中间表进行操作。
查询条件包含null or not null(JAP)
查询出数据库中表某个字段为null或不为null的所有记录
以下为代码示例:
@Query(value = "select p from DeviceDetailEntity as p where (p.name = ?1) and (p.customerId=?2 or ?2 is null)")
DeviceDetailEntity getByName(String name,Integer customerId);
加入这条限制条件:?2 is null or p.customerId=?2
传参是线性表(JAP)
第一种直接更改方法名即可以在jpa中实现传参为数组的查询:
List<DeviceModelPropertyEntity> findByModelIdIn(List<Integer> deviceModelIds);
第二种直接书写sql语句:
@Query(value="select p from DeviceDetailEntity as p where (p.positionId=?1)" +
"and (p.modelId in ?2) and (p.customerId=?3 or ?3 is null)")
List<DeviceDetailEntity> findByPositionIdAndModelIdInAndCustomerId(int positionId, List<Integer> modelId,Integer customerId);
p.modelId in ?2这句实现传参为数组时条件查询,即是让线性表modelId中每个值在表中遍历查询。
联立表格查询(JPA)?
@Query(value = "select SUBSTRING(p.regionId, 1, ?6*2), count(d.id), p1.name, p1.lng, p1.lat " +
"from DevicePositionEntity as p " +
"inner join DeviceDetailEntity as d on p.id = d.positionId " +
"inner join DeviceModelEntity as m on d.modelId = m.id " +
"inner join GeoRegionEntity as p1 on SUBSTRING(p.regionId, 1, ?6*2)=p1.id " +
"where (m.deviceTypeId = ?5) " +
"and (p.lng between ?1 and ?2) " +
"and (p.lat between ?3 and ?4)" +
"and (p.customerId=?7 or ?7 is null) " +
// "and exists(select p2 from DeviceDetailEntity as p2 inner join DeviceModelEntity as p3 on p2.modelId=p3.id where p2.positionId=p.id and p3.deviceTypeId = ?5) " +
"group by SUBSTRING(p.regionId, 1, ?6*2), p1.name, p1.lng, p1.lat")
List<Object[]> countByBoundsDeviceAndLevelGroupByRegion(BigDecimal lng1, BigDecimal lng2, BigDecimal lat1, BigDecimal lat2, int deviceType, int level,Integer customerId);
注意返回的类型是一个List<Object[]>,抽象对像的线性表集合。
在获取查询结果集的数据时可以这么来获取,实例代码:
@Override
//level:地区行政级别
public List<PositionSumByRegion> countBoundsByRegion(BoundsDevice boundsDevice, int level,Integer customerId) {
GeoBounds bounds = boundsDevice.getBounds();
BigDecimal lng1 = bounds.getSw().getLng();
BigDecimal lng2 = bounds.getNe().getLng();
BigDecimal lat1 = bounds.getSw().getLat();
BigDecimal lat2 = bounds.getNe().getLat();
List<Object[]> counts = null;
if (boundsDevice.getDeviceType() > 0) { //限设备类型
counts = positionRepository.countByBoundsDeviceAndLevelGroupByRegion(lng1, lng2, lat1, lat2, boundsDevice.getDeviceType(), level,customerId);
} else {//不限
counts = positionRepository.countByBoundsAndLevelGroupByRegion(lng1, lng2, lat1, lat2, level,customerId);
}
List<PositionSumByRegion> sumByRegions = counts.stream().map(p ->{
PositionSumByRegion positionSumByRegion=new PositionSumByRegion(p[0].toString(), p[2].toString(),
((Long)p[1]).intValue(), new GeoPoint((BigDecimal)p[3], (BigDecimal)p[4]));
positionSumByRegion.setCustomerId((Integer) p[5]);
return positionSumByRegion;
}).collect(Collectors.toList());
return sumByRegions;
}
p[i](i在此处就是从0到5的整数)来获取查询结果集的一条数据的某个字段数据,如在sql的select语句中p.customerId是第五个字段,则可以用p[5]来获取,再转为正确的数据类型即可。
group by
概述:“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
原始表
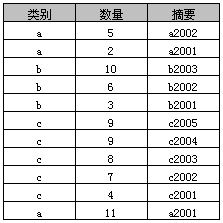
示例1
select 类别, sum(数量) as 数量之和
from A
group by 类别
返回结果如下表,实际上就是分类汇总。
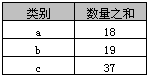
findByIdStatsWith与findByIdStartingWith(JPA)
首先这两个方法都是依据一张表中的id做一个依据传过来参数的模糊查询
这是在xxxRepository中的使用这两种查询方法时,查询的结果集是相同的
List<GeoRegionEntity> findByIdStartingWith(String id);
List<GeoRegionEntity> findByIdStartsWith(String id);
这是等同于数据库中这条sql语句:
SELECT * FROM smartcity_test.geo_region where id like '1201%';
查询的结果集都为
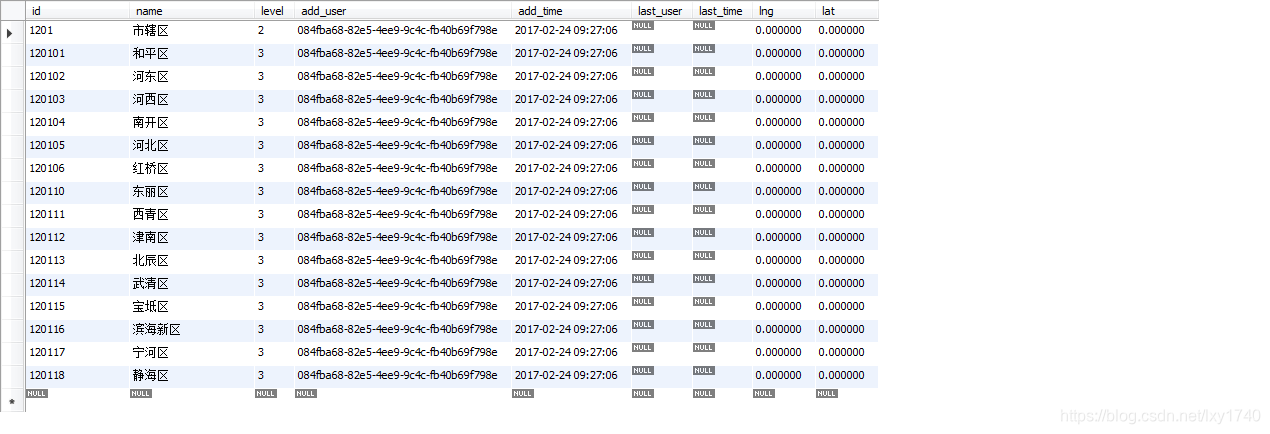
JPA&Hibernate
JPA本身是一种规范,它的本质是一种ORM规范(不是ORM框架,因为JPA并未提供ORM实现,只是制定了规范)因为JPA是一种规范,所以,只是提供了一些相关的接口,但是接口并不能直接使用,JPA底层需要某种JPA实现,JPA现在就是Hibernate功能的一个子集
Hibernate 从3.2开始,就开始兼容JPA。Hibernate3.2获得了Sun TCK的 JPA(Java Persistence API) 兼容认证。
JPA和Hibernate之间的关系,可以简单的理解为JPA是标准接口,Hibernate是实现,并不是对标关系,借用下图可以看清楚他们之间的关系,Hibernate属于遵循JPA规范的一种实现,但是JPA是Hibernate遵循的规范之一,Hibernate还有其他实现的规范
所以它们的关系更像是JPA是一种做面条的规范,而Hibernate是一种遵循做面条的规范的汤面,他不仅遵循了做面条的规范,同时也会遵循做汤和调料的其他规范,他们之间并不是吃面条和吃米饭的关系
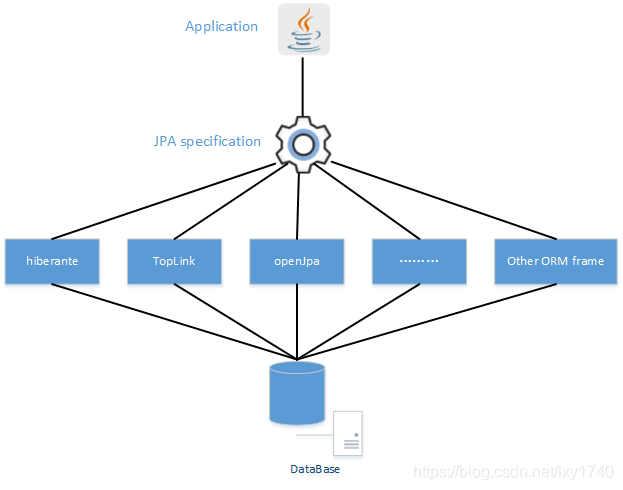
JPA
JPA全称: Java Persistence API,JPA通过JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
JPA的出现有两个原因:
其一,简化现有Java EE和Java SE应用的对象持久化的开发工作;
其二,Sun希望整合对ORM技术,实现持久化领域的统一。
Sun之所以提出JPA规范,其目的是以官方身份来统一各种ORM框架的规范,包括著名的Hibernate、TopLink等
不过JPA规范给开发者带来了福音:开发者面向JPA规范的接口,但底层的JPA实现可以任意切换:觉得Hibernate好的,可以选择Hibernate JPA实现;觉得TopLink好的,可以选择TopLink JPA实现……这样开发者可以避免为使用Hibernate学习一套ORM框架,为使用TopLink又要再学习一套ORM框架
JPA提供的技术:
(1) ORM映射元数据
JPA支持XML和JDK 5.0注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持
久化到数据库表中;
(2) JPA 的API
用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和SQL代码中解
脱出来。
(3) 查询语言
通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合
Hibernate
JPA是需要Provider来实现其功能的,Hibernate就是JPA Provider中很强的一个。
例如:
(1) 实体对象的状态,在Hibernate有自由、持久、游离三种,JPA里有new,managed,detached,removed,而这些状态都是一一对应的。
(2) flush方法,都是对应的,
(3) Query query = manager.createQuery(sql),它在Hibernate里写法上是session,而在JPA中变成了 manager
JPA和Hibernate之间的关系
可以简单的理解为JPA是标准接口,Hibernate是实现。
那么Hibernate是如何实现与JPA 的这种关系的呢?
Hibernate主要是通过三个组件来实现的,及hibernate-annotation、hibernate-entitymanager和hibernate-core。
(1) hibernate-annotation是Hibernate支持annotation方式配置的基础,它包括了标准的JPA annotation以及 Hibernate自身特殊功能的annotation。
(2) hibernate-core是Hibernate的核心实现,提供了Hibernate所有的核心功能。
(3) hibernate-entitymanager实现了标准的JPA,可以把它看成hibernate-core和JPA之间的适配器,它并不直接提供ORM的功能,而是对hibernate-core进行封装,使得Hibernate符合JPA的规范。
总的来说,JPA是规范,Hibernate是框架,JPA是持久化规范,而Hibernate实现了JPA。
数据库配置
MYSQL数据库的连接,在.yml文件中的配置
spring.jpa.database=mysql
spring.datasource.url = jdbc:mysql://172.18.6.132:3306/smartcity_test?characterEncoding=UTF-8&useSSL=false
spring.datasource.username = smartcity
spring.datasource.password = dQ8$d8hK
H2数据库的配置
spring.jpa.database=h2
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:mem:smartcity;MODE=MySQL;DB_CLOSE_DELAY=-1;DATABASE_TO_UPPER=FALSE
spring.datasource.initialization-mode=always
left join、right join、inner join
left join(左联接) 返回包括左表中的所有记录和右表中关联字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中关联字段相等的记录
inner join(等值连接) 只返回两个表中关联字段相等的行
表A记录如下:
aID aArea
1 北京
2 上海
3 广州
4 深圳
5 香港
表B记录如下:
bID bName
1 小王
2 小张
3 小李
4 小陈
8 小黄
left join
sql语句如下:
select * from A left join B on A.aID = B.bID
结果如下:
aID aArea bID bName
1 北京 1 小王
2 上海 2 小张
3 广州 3 小李
4 深圳 4 小陈
5 香港 NULL NULL
left join是以左边的A表的记录为基础的,也就是说,左表(A)的记录会全部展示出来,而右表(B)只会展示符合搜索条件的记录。
right join
sql语句如下:
select * from A right join B on A.aID = B.bID
结果如下:
aID aArea bID bName
1 北京 1 小王
2 上海 2 小张
3 广州 3 小李
4 深圳 4 小陈
NULL NULL 8 小黄
right join是以右边边的B表的记录为基础的,也就是说,右表(B)的记录会全部展示出来,而左表(A)只会展示符合搜索条件的记录。
inner join
sql语句如下:
select * from A innerjoin B on A.aID = B.bID
结果如下:
aID aArea bID bName
1 北京 1 小王
2 上海 2 小张
3 广州 3 小李
4 深圳 4 小陈
这里只展示了A.aID = B.bID的记录.说明inner join并不以谁为基础,它只显示符合条件的记录.
sql脚本执行update,delete报错:using safe update mode …disable safe mode
具体报错信息:You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode
报错原因:在delete或者update的时候,都可能会出现这种警告/报错,这主要是因为版本较新的MySQL是在safe-updates模式下进行sql操作的,这个模式会导致在非主键条件下无法执行update或者delete。
修改方式:单独执行一条SQL带有主键限制
如要修改device_detail表中某条记录,使用主键id来做限制条件
update smartcity_test.device_detail set position_id=null where id=1
取消安全模式
set sql_safe_updates=0;/*取消安全模式*/
UPDATE `smartcity_test`.`device_detail` SET `parent_id`=null,`position_id`=null/*修改多个字段,字段之间用逗号隔开*/
WHERE (`name`='10000020' or `name` like '1000001%')
or (`name`='40000020' or `name` like '4000001%');
在where中使用主键做限制
delete from _table where content='I'm fool' and id>0
