课程地址:http://www.auto-mooc.com/mooc/detail?mooc_id=BA91C867A68E92651FBF224828ECAE6E&major_id=E1007D8658541BD264785AA3709ADA25
这是笔记!
1.0数据基本算法
1.1聚类算法
类:相似元素的集合。
分类
是事先定义好类别,类别数固定;按照某种标准给队形贴标签,再根据标签来区分归类。
聚类
是没有事先预定的类别,类别数不确定。聚类不需要人工标注和事先训练分类器,类别再聚类过程中自动生成。

K-means聚类算法
K均值聚类算法。


步骤:1、首先随机确定质心,图b;2、计算样本到质心的距离;3、将样本聚类,图c;4、重新计算聚类后,各自的质心,图d;5、执行第2步,循环。

SOM聚类


KNN与K-means区别
参考:https://www.tuicool.com/articles/qamYZv
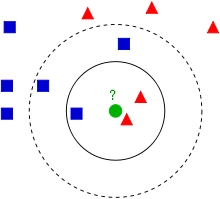
KNN的算法过程是是这样的:
从上图中我们可以看到,图中的数据集是良好的数据,即都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看到,KNN本质是基于一种数据统计的方法!其实很多机器学习算法也是基于数据统计的。

聚类性能度量


距离计算:

马氏距离(雷达的聚类是什么搞得???待会学习一下)
1.2降维算法



协方差矩阵???(待会学习一下)


1.3回归算法










