什么是大数据?
大数据区别于传统的数据。大数据的特征是四个V,即:
- volume 数据体量大
- variety 数据类型丰富
- velocity 处理速度快
- value 价值密度低
目前仍然没有大数据的准确定义。与传统数据库存储形式不同,传统的数据存储一般是结构化存储,便于表之间进行连接操作。而大数据通常是以no-sql的形式进行存储。而no-sql应用最多的是以“key-value”的形式来存储的,其他类型的no-sql还包括文档型数据,列存储数据、图形数据库、xml数据库等。
大数据处理通常需要满足下面几点要求:
- high performance 高并发的读写需求
- huge storage 对海量数据高效率的存储访问
- high scalabity & high availabity 高可扩展性和高可用性
大数据分布式系统CAP定理
- C consistency 一致性:系统强一致性
- A availablity 可用性:每一个请求都能够得到快速响应。
- P partition tolerance 分区容错性:在网络中断、信息丢失的情况下,系统能够照样工作
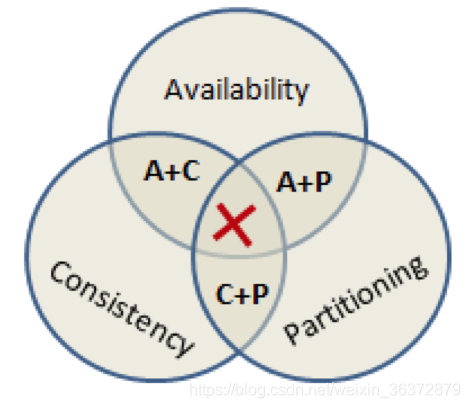
已经被证明,一个系统只能够满足CAP中的两项。
对于互联网应用,通常舍弃C,满足AP,节点大,主机多,节点故障时常态,为了不影响用户使用流程,舍弃C
对于金融领域应用,通常舍弃P,满足CA,因为要保证强一致性,但是如果有机器宕机,系统不可用。
Memcached分布式缓存
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。
数据存储
memcached存储两种形式的数据:key-val数据和sql数据

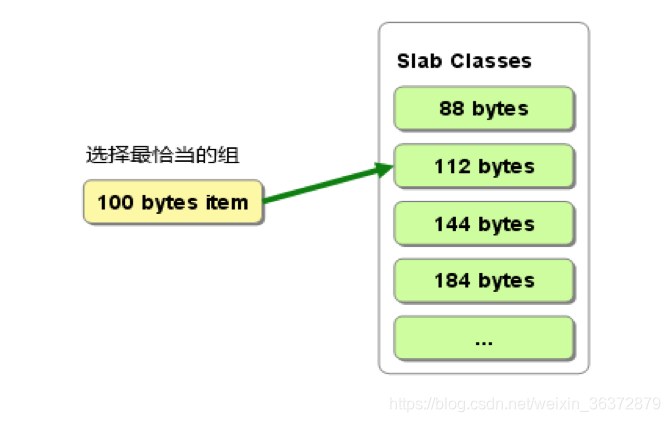
为了防止内存碎片化,使用slab-allocator来分配存储空间。可以看到很多个相同大小的chunck组成一个slab class。
同时采用了惰性的回收机制,记录超时之后,不会释放已经分配的内存,只是客户端看不到该记录,该内存可以重复使用。不需要在过期监视上耗费CPU时间。
Memcached替换策略:
- 优先替换超时的内存
- 如果还存在空间不足的情况,使用LRU机制来替换已有的缓存内容。
Memcached分布式:
Memcached只是web缓存,减少数据库的读取次数,Memcached本身不具有“分布式的功能”,分布式完全又客户端程序库实现。

Memcached采用一致性哈希(consistent hash)算法来进行分布式处理
- 求出服务器节点的hash,映射到0~232的圆上
- 用同样的方法求出存储数据键的hash值,映射到圆上
- 从数据映射到的位置开始顺时针查找,将数据保存在第一台服务器上。
- 如果超过232仍然找不到服务器,就保存在第一台服务器上。
DynamoDB
DynamoDB是分布式数据库,设计成用来解决数据库管理、性能、可扩展性和可靠性等核心问题。开发人员可以创建一个数据库表,该表可以存储和检索任何数量的数据。
DynamoDB改进了Memcached的一致性hash算法
采用了虚拟节点的机制改进了一致性hash算法,有Q个虚拟节点,S个物理节点,那么为每一个物理节点分配Q/S个虚拟节点,其中Q>>S,虚拟节点的好处是能够分布不均匀的问题,最大限度减少服务器增减时的缓存重新分布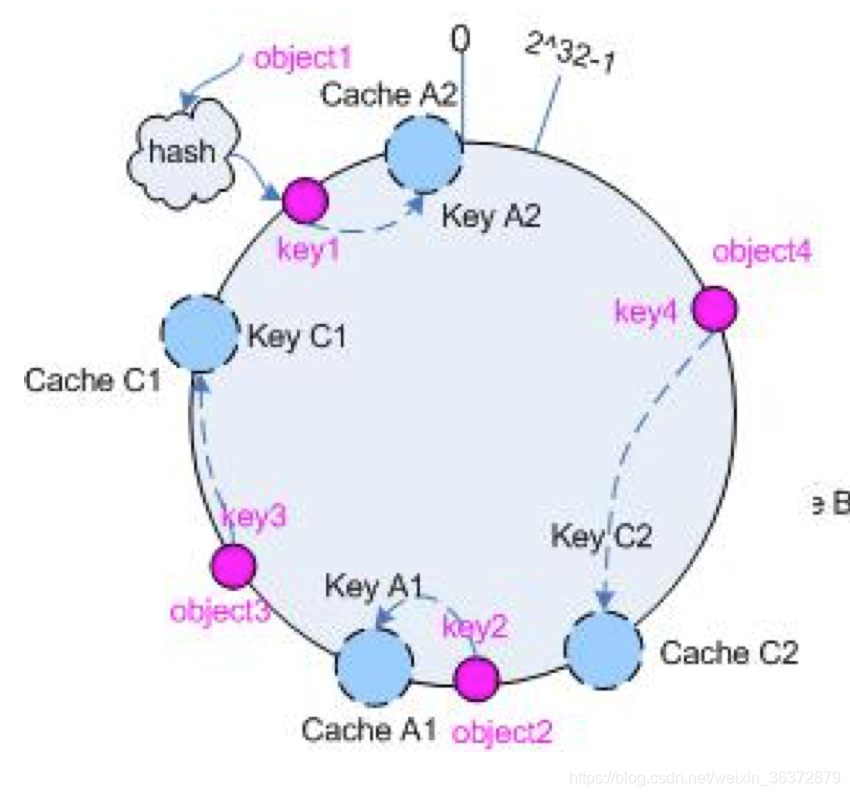
Memcached虚拟节点不固定,虚拟节点位置随机性,如果有新节点加入,则需要扫描所有节点上的所有数据对象,判断是否需要迁移,这种全局扫描会造成很大开销。
DynamoDB固定虚拟节点,只改变虚拟节点和节点的对应关系。
- 当加入节点的时候,从现有节点中拿出等量虚拟节点分配给新节点
- 当节点离开的时候,将此节点的所有虚拟节点平均分配给余下的节点
Quarum机制:
R + W > N的机制能够保证数据的正确性,但是不能保证一致性,如果R=W=N可以保证一致性,但是无疑牺牲了很多可用性
多副本机制
DynamoDB有多副本机制,但是为了达到高的可用性,牺牲了一致性,满足AP,牺牲了C,通常如果有N个副本,那么顺时针找N个节点存放。
preference list
N个副本存放构成一个preference list,但是客户端的请求交给一个节点处理,在其中选择一个节点作为coodinator

写数据流程
- coodinator生成新的数据副本以及vector clock分量
- 向preference list中所有节点发出写请求
- 收到W-1个回复写成功
读数据流程
- coodinator向preference list中所有的节点请求数据版本
- 等到R-1个答复,答复中包括vector clock
- 通过处理vector clock处理有因果关系的副本
- 将不相容的所有数据版本返回给用户
vector clock
DynamoDB通过向量时钟算法来确定时间发生的先后顺序
vector clock无限增长
向量时钟随着时间的推移会无限增长,有两种方案解决问题:
- 采用服务器向量的形式
- 时钟向量减枝
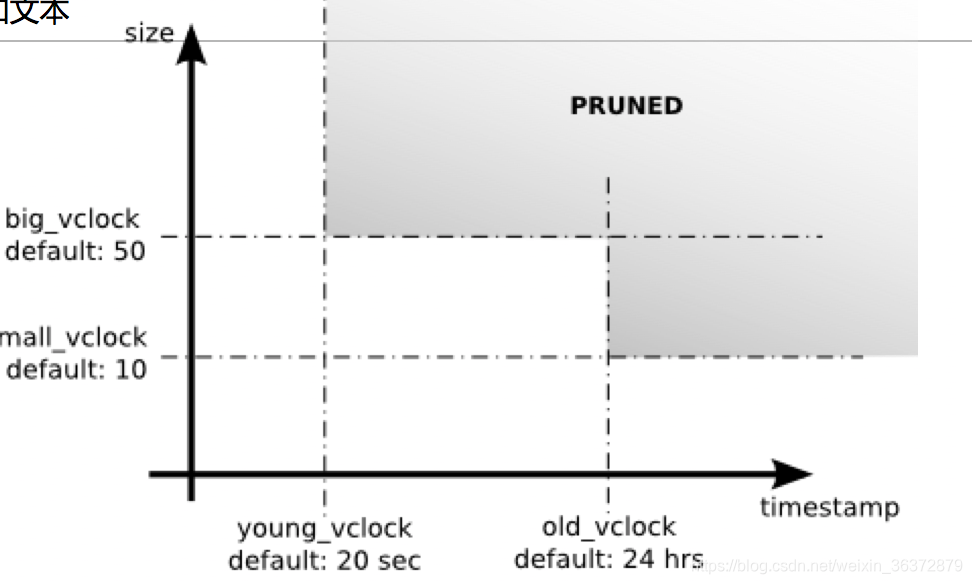
采用服务器向量会丢失数据,向量减枝的方法更优
暗示接力技术(hinted handoff)
DynamoDB针对临时节点失效处理采用了hinted handoff技术,往后找一个节点暂时替代失效的节点,该节点定期的检查故障节点是否恢复。
使用gossip协议进行数据传播
虽然写了W个节点,但是通过gossip节点加上vector clock,能够维持成员的最终一致性。
每个节点每间隔一秒随机选择另外一个节点进行通信,两个节点协调他们保存的成员变动历史
另外采用种子节点来避免逻辑分裂,每一个节点都要与种子节点通信。
副本同步校验merkle tree
当故障发生或者有新节点加入的时候,都涉及到分片的靠背和传输,希望能够快速检查分片中的内容是否相同。
DynamoDB DB采用了merkle tree技术,merkle tree在区块链中也有非常典型的应用,比如想要寻找是否存在某一个交易,那么构造一个认证路径最后比较根节点即可。
- 叶子节点对应每一个数据项,并记录hash值
- 非叶子节点记录所有子节点的hash值
如果根的hash相等,叶子的hash相等,那么节点不需要同步,这样可以解决hash list文件太大的问题。
存储区域网SAN
组成成分
- RAID阵列
- 光纤通道
通过SCSI命令通信而不是TCP/IP
存储区域网通过块级的数据传输,能够有效的传输爆发性的数据,能够建立高速专用网络,建立服务器,磁盘阵列,磁带库直连
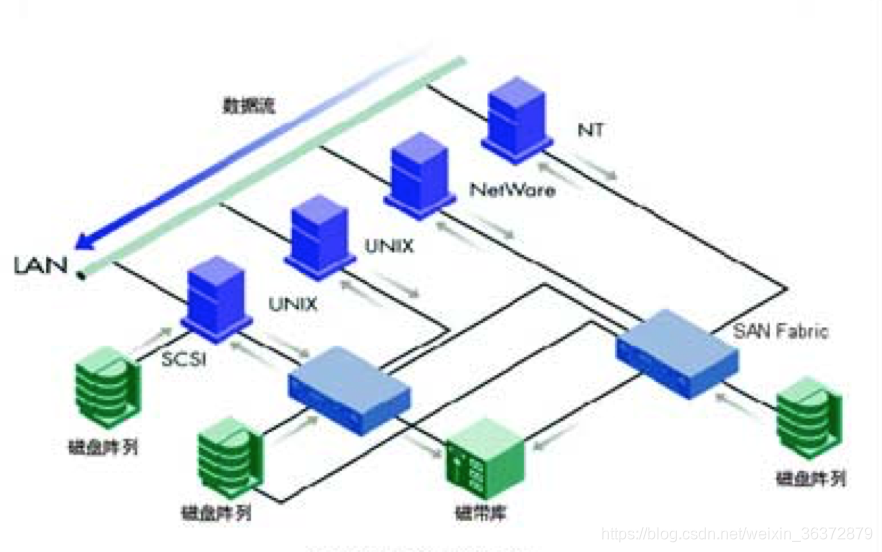
SAN的关键技术
- 光纤通道交换机
- 光纤通道网络协议:FCP(fibre channel protocol)上加载SCSI协议
淘宝TFS
- 两台name server
- 多台data server
集群规模200台PC,文件上亿,系统部署存储容量140TB,实际使用50TB,单台支持随机IOPS200+,流量3MBPS
OceanBase
数据库数据量十分庞大(几十亿,几百亿++)
但是一段时间内修改量不大(通常不超过几千万条到几亿条)
因此数据分类增量数据和基线数据
- 基线数据Chunck server:分布式文件系统
- 增量数据Update server:内存表+SSD用于写数据
- Merge server将chunk和update融合之后返回和分散,用于读取数据
GFS
GFS 也就是 google File System,Google公司为了存储海量搜索数据而设计的专用文件系统。
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务。
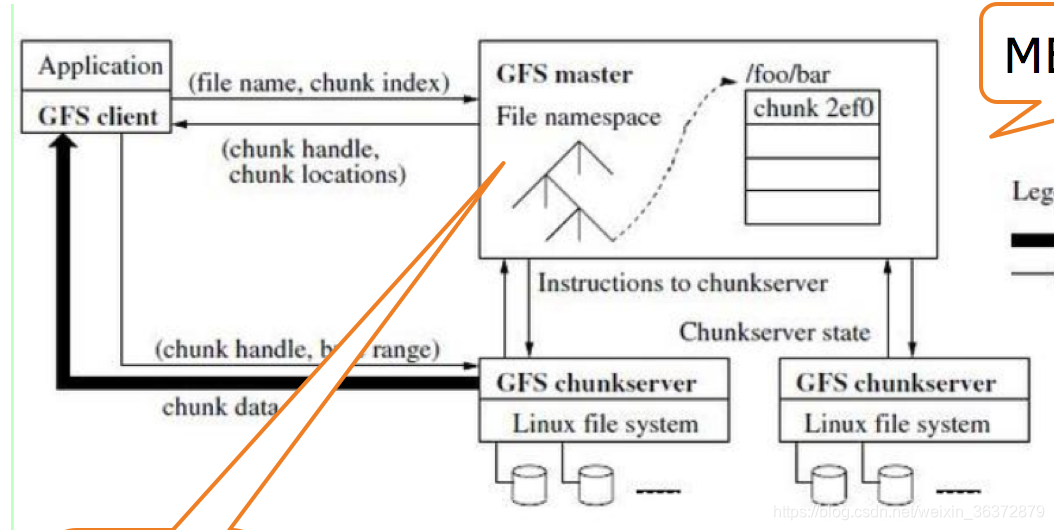
master节点
master节点只存放元数据:
- 文件和chunk命名空间
- 文件和chunk的对应关系
- 每个chunk副本的存放地点
chunk server节点
chunk server节点是数据存放节点,也是数据操作节点,客户端只与master节点交换元数据,数据操作都是在chunck server节点上进行的。
持久保存数据与非持久保存数据
- master持久保存日志数据,日志的序号表示时间
- master非持久保存chunk server的位置信息,只是采用定期轮询的机制,只有chunk服务器才能最终确定某个chunk是否在硬盘上
GFS master复制机制
- 一个逻辑的master采用两台物理主机
- master状态复制,复制操作日志和check point文件
- “影子”master机制
GFS读取数据流程
- 客户端将文件名和程序字节偏移转换成chunk索引,进而把文件名和chunk索引发送给master
- master将chunk标识和副本的位置信息发送给客户端,同时客户端用文件名和chunk索引作为key 缓存,然后发送客户端请求到其中一个副本chunksever(一般最近的)
- 该chunkserver读取chunk数据返回客户端
实际过程中,客户端通常在一次请求中查询多个chunk信息,master节点的回应也可能包含了被请求chunk后续chunk的信息。
GFS写数据流程
租约机制:master建立租约,并将其授权给某个副本作为primary,由primary确定数据修改的顺序,其他的副本照做

- 客户机向master询问哪个节点持有租约,以及其他副本的位置,如果没有chunk是租约,那么就选择其中的一个副本建立租约
- master将主chunk的标识符以及其他副本(secondary副本)的位置返回给客户机,客户机缓存这些数据
- 客户机将数据推送到所有的副本上(可以按照任意顺序)
- 当所有的副本都确认收到数据后,客户机发送写请求给primary chunk服务器,primary chunk为接收到的所有的操作分配连续的序列号
- 主chunk把写请求传递到二级副本,每个二级副本按照主chunk分配的序列号以相同的顺序进行操作
- 二级副本回复主chunk完成
- 主chunk回复客户机
记录追加 原子性操作
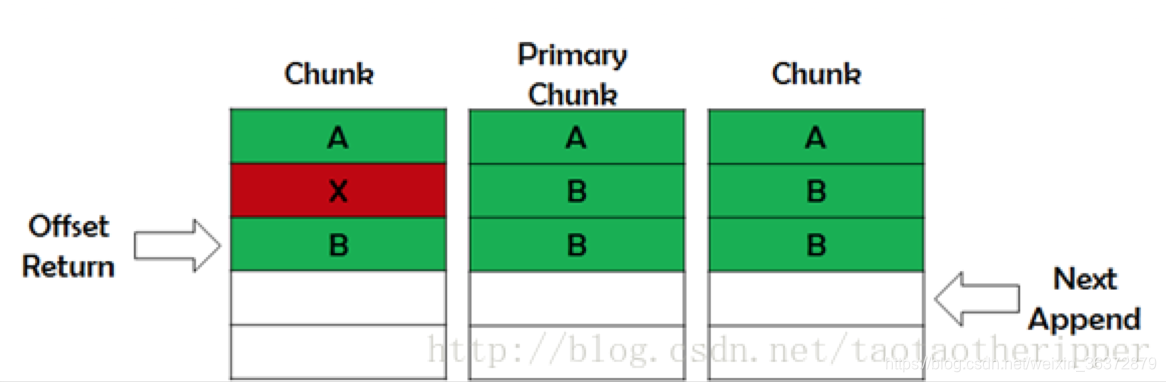
追加操作超过chunk尺寸
- 填充当前chunk
- 通知secondary做同样的操作
- 通知客户机向新的chunk追加
追加操作不会超过chunk尺寸
- 主chunk追加数据
- 通知二级chunk写在相同的位置上
- 如果失败,重新操作,成功则返回偏移
失败的追加操作可能导致chunk间字节不一致,但是最终追加成功之后,所有副本返回的偏移是一致的。
BigTable
map索引
bigtable的数据特征是:一个稀疏的,分布式的,持久化存储的多维度的map
map索引=行关键字+列关键字+时间戳
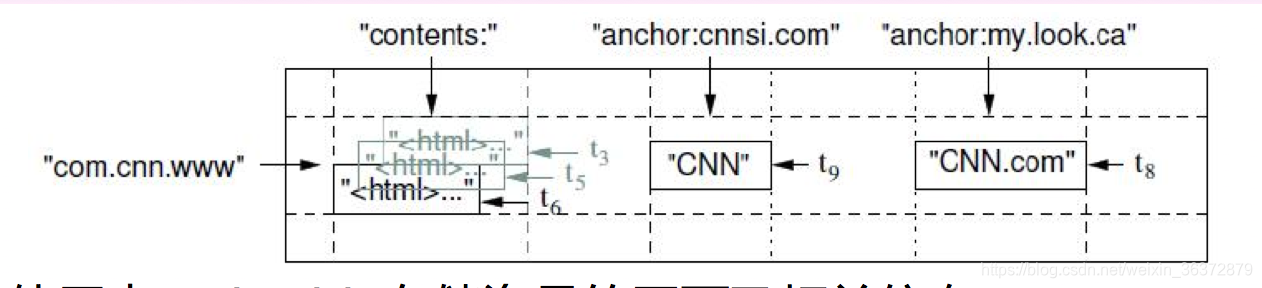
访问控制的最小单位为列族
数据分布和负载均衡的最小单位为tablet
三层寻址
chubby -> root tablet -> metadata tablets -> user tablets
分布式一致性算法paxos & raft
1 paxos算法
paxos算法通过多个监督者来增强可靠性
- 通过监督者投票表决状态变化
- 保证所有数据访问都遵从这种表决
多数派写
客户端写入 W >= N/2 + 1个节点,节点之间平等
多数派读
W + R > N; R >= N/2 + 1
容忍最多(N - 1) / 2个节点损坏
法定集合
将一个超过半数的节点集合成为法定集合。
法定集合的性质:任意两个法定集合,必定存在一个公共成员。
法定集合的性质是paxos算法的有效保障,paxos基于法定集合的原理
安全原则
按照paxos算法,在来自提议N的值v未来或者已经被接受的情况下,不会有一个M>N的提议提出一个不同的值u
paxos ID生成算法
s = m * n + ir
n是节点个数,m是轮数,ir是节点编号,通过增加m,使得后者的ID比前者的ID大
paxos解决活锁问题
id生成算法会造成活锁问题,即一直相互等待,节点的编号越来越大,解决办法是选取一个proposal作为leader,所有的proposal都通过leader提交。
2 Raft算法
分布式系统中的强一致性算法
日志
每一台机器保存一份日志,日志来源于客户请求
raft算法日志内容
- 一条用于状态机的指令
- 从leader收到本日志项的term号
- 在自己本机中的index值
复制状态机
复制状态机会按照日志的顺序执行这些日志
一致性模型
分布式环境下,保证多机的日志一致,从而回放到状态机中的状态是一致的
任期term
每一个任期都是一个选举,选出一个leader,如果没选出,term号自增
Raft日志变更
- 已提交的日志不可改变
- 未提交的日志可以被更新成其他日志
leader只能在日志中添加新条目,不能覆盖和删除条目
leader选举
- followers只对日志长度大于等于自己的candidate投票
- 只有包含所有已提交日志的candidate才能成为leader
Raft日志广播
- leader发送日志到follower,但不提交
- 多半以上的follower应答后,leader更新自己的commit index,再广播commit index到follower
Raft算法过度配置
不需要将服务器下线,重新配置,上线
过度配置好处
- 让集群在配置转换中依然能够相应服务器的请求
- 允许各个服务器在不影响安全性前提下,各自在不同的时间进行配置转换
过度配置能够保证在配置变更过程中,不会出现两个leader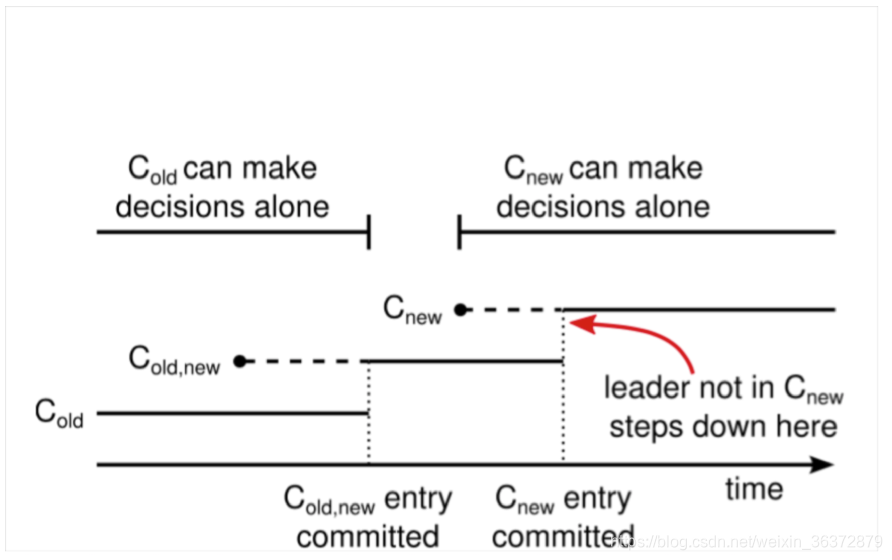
过度配置流程
- leader收到从c(old)到c(new)的请求
- 创建日志c(old-new)
- 广播c(old-new),检查是否达到多数派
- c(old-new)达到多数派,commit
- 创建日志c(new)
- 广播c(new),看是否达到多数派
- c(new)达到多数派,commit
- 不在c(new)状态的节点关闭
图中实线表示已经提交的条目,虚线表示创建之后,没达到多数派,未提交的条目,达到多数派之后,就会提交
在1~3步,c(old)为多数派,只有可能c(old)为leader
在4~6步,只有可能含有c(old-new)配置的节点成为leader
在7~8步,只有可能含有c(new)的节点成为leader
始终保证集群只有一个leader
MapReduce
执行流程
- 创建一个map函数处理一个基于key/value对的数据集合,输出中间数据,并写入磁盘
- 创建一个reduce函数来合并处理中间数据,具有相同key值的value调用被分布到多台机器上
reduce可以分布到多台机器上,例如hash(key) mod R, R为分区数目,一个job包含多个task,每个reduce任务产生一个输出文件,因此有R个输出文件。
实现模型
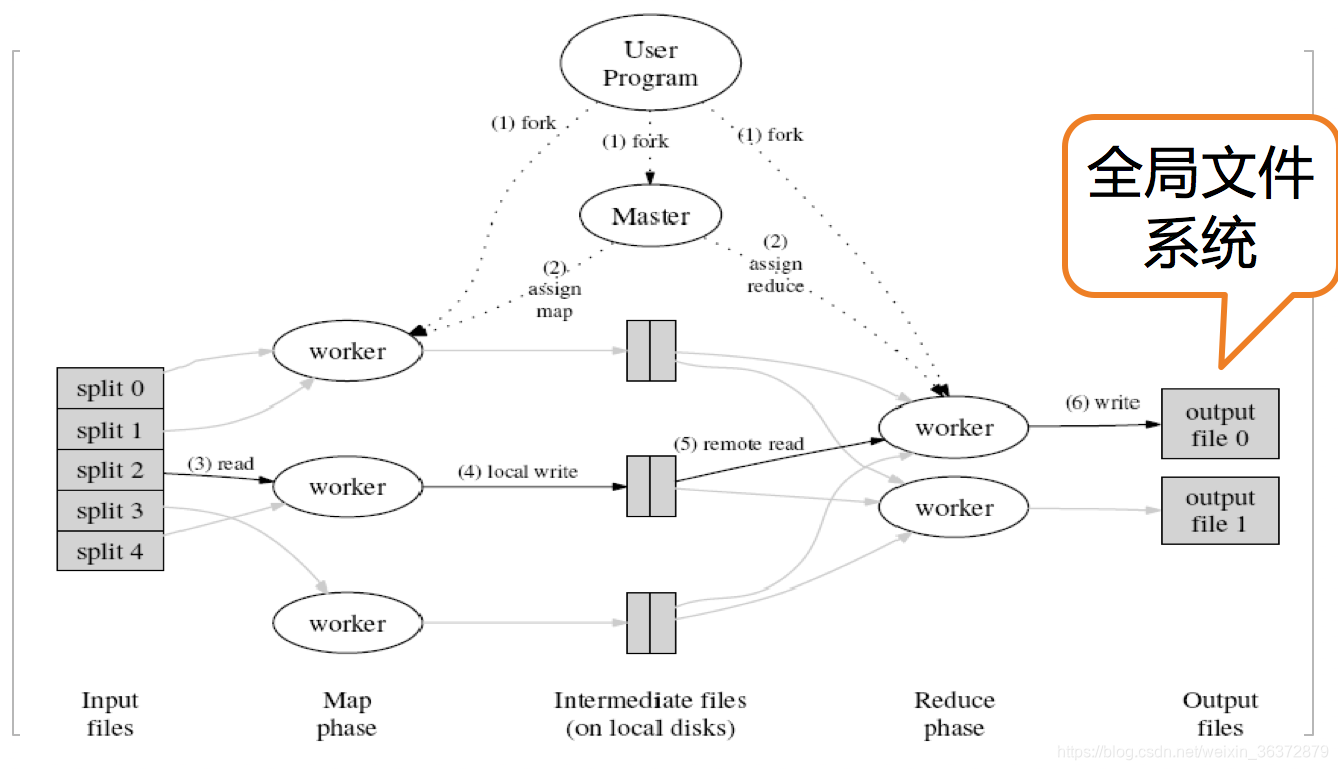
执行过程
- 首先调用MapReduce库,将输入文件分成M个数据片段(split)。用户程序在集群中创建(fork)大量程序副本。
- 程序副本中,有一个特殊的程序(master),其他程序都叫worker
- map任务的workder读取相关的输入数据片段(split),从中解析出key-value对,输出并缓存在内存中
- 缓存中的key-value通过分区函数分成R个区域之后,写入到本地硬盘上,然后将存储位置传递给master
- reduce worker接收到master发来的数据存储位置,使用RPC读取数据,读取之后对key进行排序,是具有相同的key聚合在一起
- reduce worker输出
- master唤醒用户程序,对MapReduce调用返回
master执行了O(M+R)个调度,在内存中保存O(M*R)个状态
Hadoop Haloop
hadoop解决迭代的MapReduce问题,有很多大数据分析需要迭代计算,而MapReduce框架对迭代计算支持度不够
MapReduce产生的问题
- 每次执行都需要重新装在数据,重新处理,但迭代过程中,有动态数据和静态数据两类,静态数据处理带来额外的开销
- 迭代终止稳定点的判断过程在每次迭代中需要额外的MapReduce计算
MapReduce局限性
- 任务调度开销
- 磁盘读取开销
- 网络传输开销
Hadoop解决思路
- 对于任务调度的开销:把循环体控制在job内,避免多次重复启动(Loop Control模块)
- 对于磁盘读取开销:实现了MapReduce静态数据缓存(Task Scheduler促成数据本地化调度)
- 对于网络传输开销:将终止条件的判断变得稳定和高效
寻找多跳邻居算法来理解Hadoop
多跳邻居算法数学表示
F表是邻居表,MR1是表的连接操作和表的投影操作,很容易理解
MR2是过滤老朋友的操作,例如Eric的两跳邻居可以从Eric到Allice再回到Eric,因此需要把之前的重复朋友去掉,防止寻找的朋友回到了之前迭代的结果,因此需要减掉,避免在中间结果的地方一致迭代。
Hadoop代码形式main函数
Main:
Job job = new Job()
job.AddMap(MapJoin, 1)
job.AddReduce(ReduceJoin, 1) #MR1
job.AddMap(MapDistinct, 2)
job.AddReduce(ReduceDistinct, 2) #MR2
job.setDistanceMeasure(ResultDistance)#由ResultDistance函数控制迭代结束
job.setFixedPointThreshold(1) #ResultDistance函数的结果小于1的时候停止迭代
job.setMaxNumOfIteration(2)#寻找2跳邻居,迭代两轮
job.setInput(IterationInput)#每一轮迭代的输入
job.setStepInput(StepInput)#一个MapReduce任务每一个步骤的输入
job.AddInvariantTable(#1) #不变的表1
job.SetReducerInputCache(true) #输入缓存
job.summit()
MapJoin
使用的是Si.name2也就是values进行的连接操作,初始的时候,输出的是F表#1,后期输出的是Si-1表#2
Input:Key k, Value v, int interation
if v from F
then output(v.name1, v.name2, #1)
else
output(v.name2, v.name1, #2)#Si-1的value为name1,后面进行输出
end if
ReduceJoin
做笛卡尔积运算
输出同一个name1或者name2的姓名以及间接关联的邻居姓名
Input:Key key, set values, set invariantValues, int iteration
output(product(values, invariantValues))
MapDistinct
输出为U Sj的两个姓名以及迭代下标
Input: Key key, value v, int iteration
output(v.name1, v.name2, iteration)
ReduceDistinct
统计U Sj,也就是T3,并且用T2-T3
Input:Key key, set values, int iteration
for name in values
if name.iteration < iteration
then set_odd.add(name)
else
set_new.add(name)
end for
output(product(key, distinct(set_new-set_odd)))
InterationInput
MR1的输入
Input:int iteration
if iteration == 1 then
return F U ^S0
else
return ^Siteration-1
StepInput
MR2的输入
Input:int step
if step == 2
return U ^Sj
Spark
Hadoop框架存在的问题
- JobTracker是MapReduce的集中处理点,存在单点故障的问题
- 以MapReduce task数目作为资源的表示比较简单,没有考虑CPU和内存占用情况
- 任务集中导致源代码复杂,增加bug修复和系统维护的难度
RDD
RDD(Resilient Distributed Dataset)是一个可读的、可分区的分布式数据集,任何数据在spark中都可以被表示为RDD
Spark应用程序
把需要处理的数据转为RDD,然后对RDD进行一系列的变换和操作
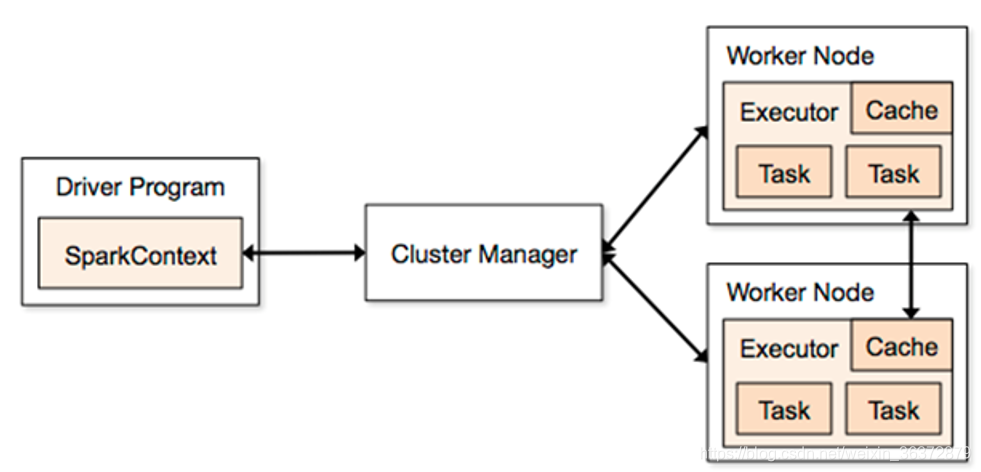
Driver Program程序入口,运行App的main,创建SparkContext
Cluster Manager:在集群上获取资源的外部服务
Workder Node:可以运行application代码的节点
Executor:一个进程,该进程负责运行task
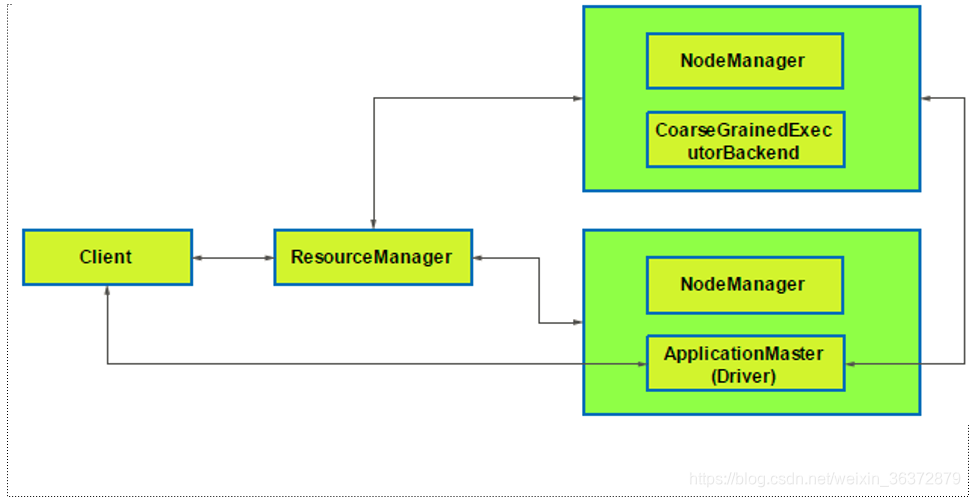
Spark on yarn-cluster框架
Yarn的基本思想
Yarn的基本思想是将JobTracker的资源管理和作业调度分离
- 资源管理:ResourceManager
- 作业调度:ApplicationMaster创建SparkContext
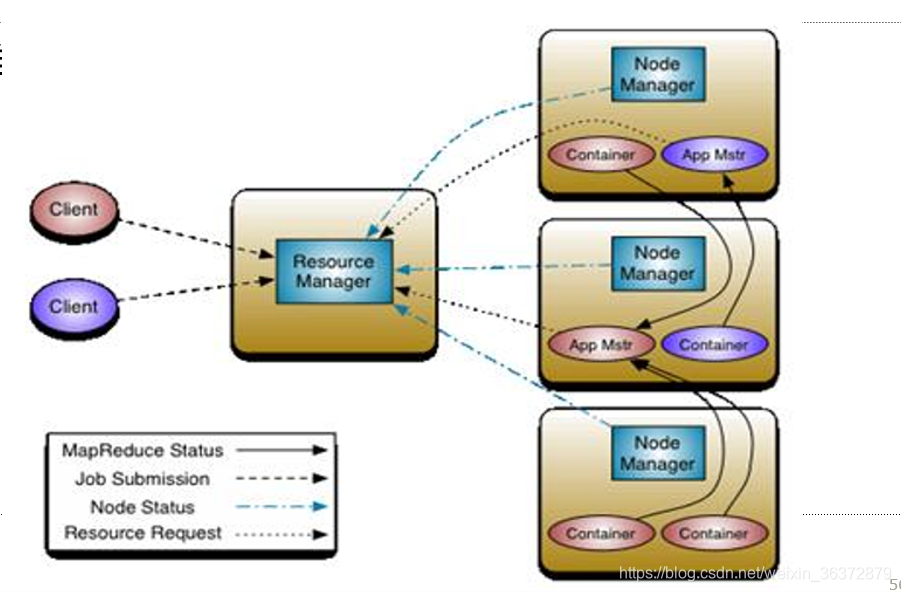
ResourceManager
负责资源管理与调度,资源管理的基本单位:task
NodeManager
节点代理,负责:
- 启动container/executor
- 监控资源使用情况给RM
Application Master
负责作业调度
- 是第一个container
- 启动SparkContext
SparkContext
- 向RM注册
- 向RM申请资源
- 启动executor等待task
- 分配task给NM上的executor
- 监控task的运行情况
Spark on yarn-cluster流程
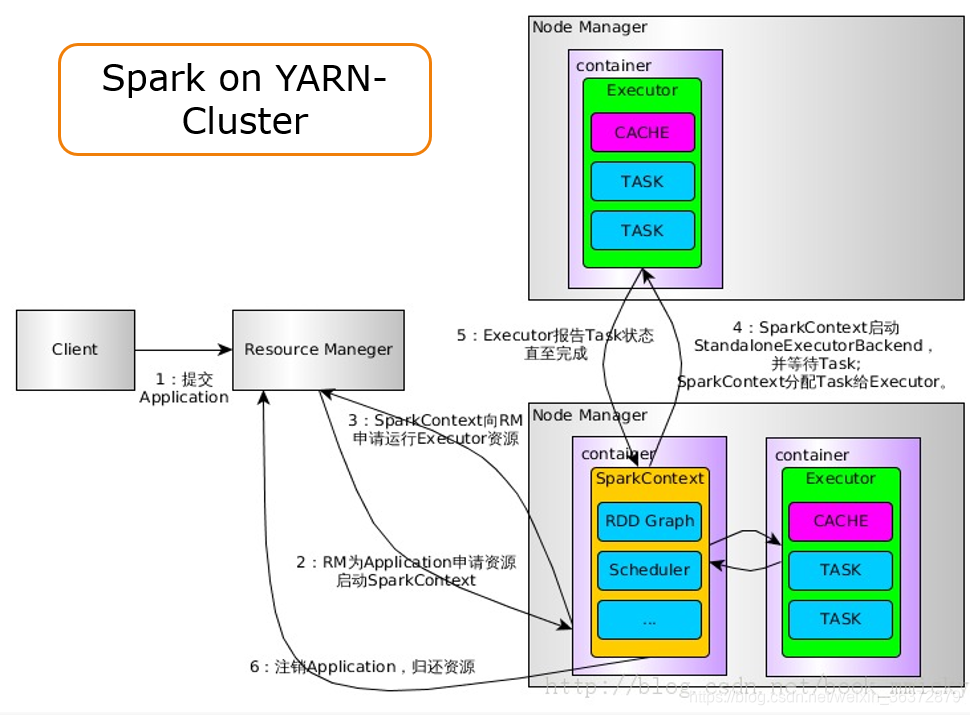
- 提交Application给RM
- RM向NodeManager申请第一个container给Application Master,Application Mater初始化SparkContext
- SparkContext向RM注册,并且申请运行executor的资源
- SparkContext和NodeManager通信,启动executor,SparkContext分配task给executor执行
- executor报告task的状态,直至完成
- 注销Application,归还资源
流数据处理strom
在2011年Storm开源之前,由于Hadoop的火红,整个业界都在喋喋不休地谈论大数据。Hadoop的高吞吐,海量数据处理的能力使得人们可以方便地处理海量数据。但是,Hadoop的缺点也和它的优点同样鲜明——延迟大,响应缓慢,运维复杂。
有需求也就有创造,在Hadoop基本奠定了大数据霸主地位的时候,很多的开源项目都是以弥补Hadoop的实时性为目标而被创造出来。而在这个节骨眼上Storm横空出世了。
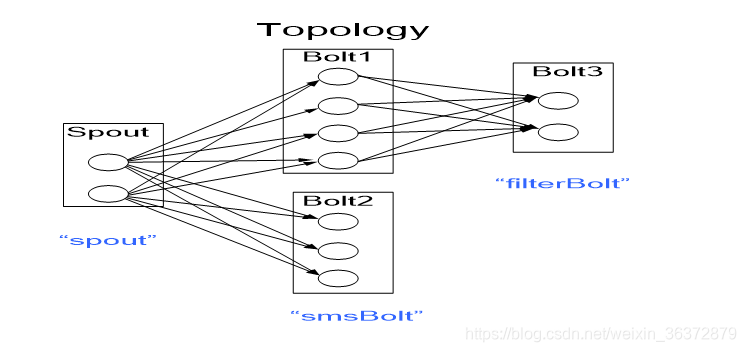
一个计算任务成为一个Topology(拓扑逻辑),由多个spout和多种bolt组成
stream:数据流,是时间无上界的tuple元祖序列
Tuple:一次消息传递的基本单元,可以被理解为键值对
task:逻辑线程,是不会变的,由代码决定
executor:物理线程,每一个executor执行多个task,executor是动态分配的,和整个集群相关。通常一个集群不止有一个job,当所有的executor用完时,新提交的job只能等待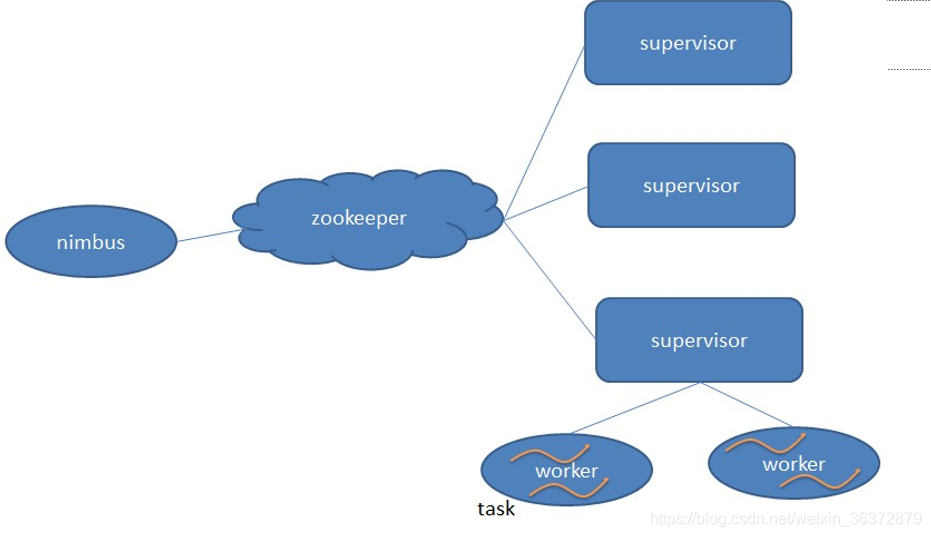
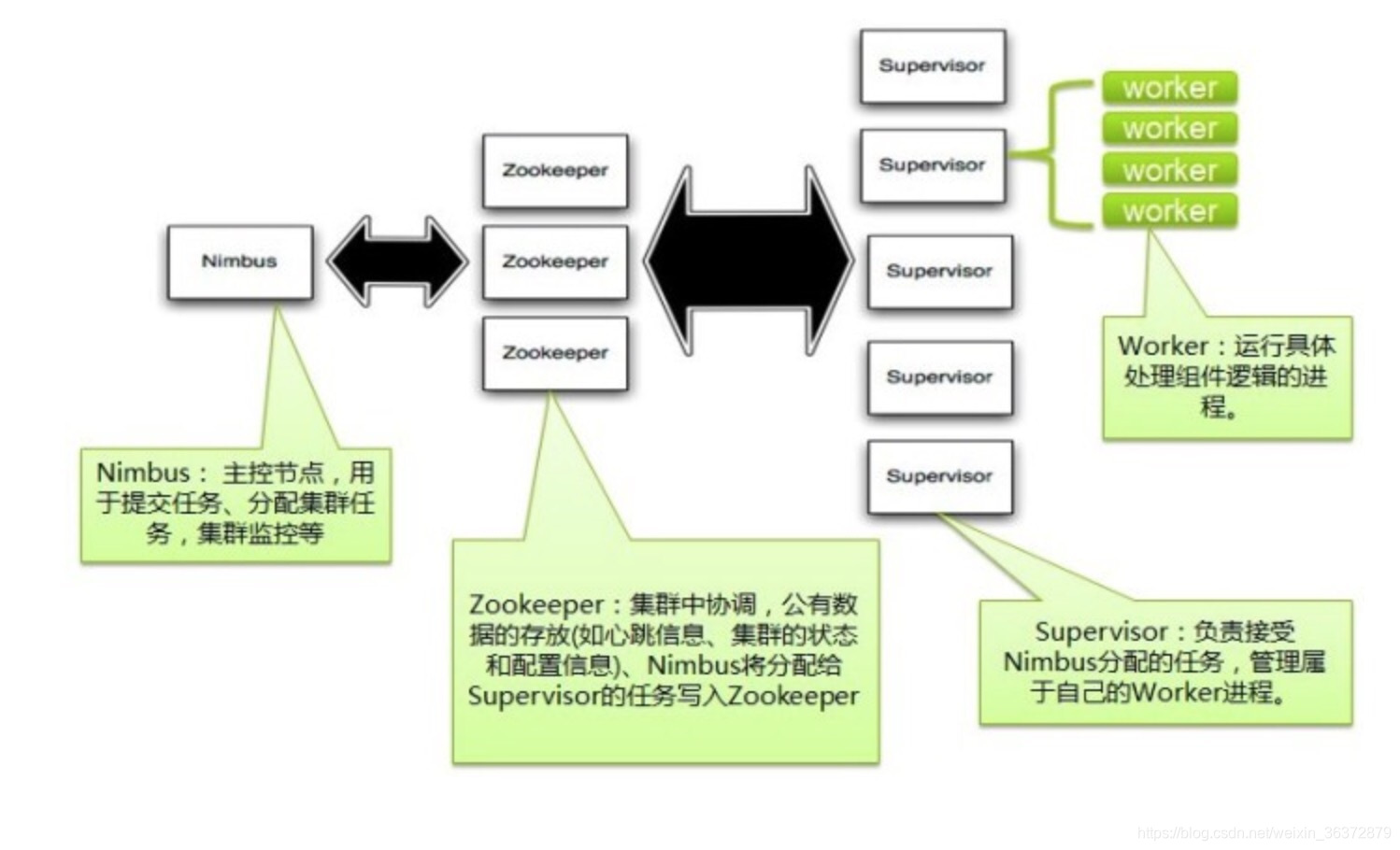
nimbus:总控节点
supervisor:工作节点,负责监听从nimbus分配的任务,据此启动或停止工作进程(worker)
supervisor节点包含多个worker占位槽,集群中的所有topology共用。
zookeeper集群:Zookeeper是Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。zooker保存所有的元数据
nimbus和zookeeper通信,zookeeper和supervisor通信,nimbus和supervisor不直接通信
zookeeper:
- task文件夹保存task信息
- assignment文件夹保存任务代码
- workerbeats文件夹保存所有worker的心跳信息
一个supervisor对应N个worker节点
一个worker节点启动N个executor
一个executor对应N个task
消息保证机制
每个topology有一个超时设置,如果strom在超时时间内检测不到某tuple是否成功,则标记失败,重新发送
strom分布式
- task之间的并行
- 先后task之间的流水线并行
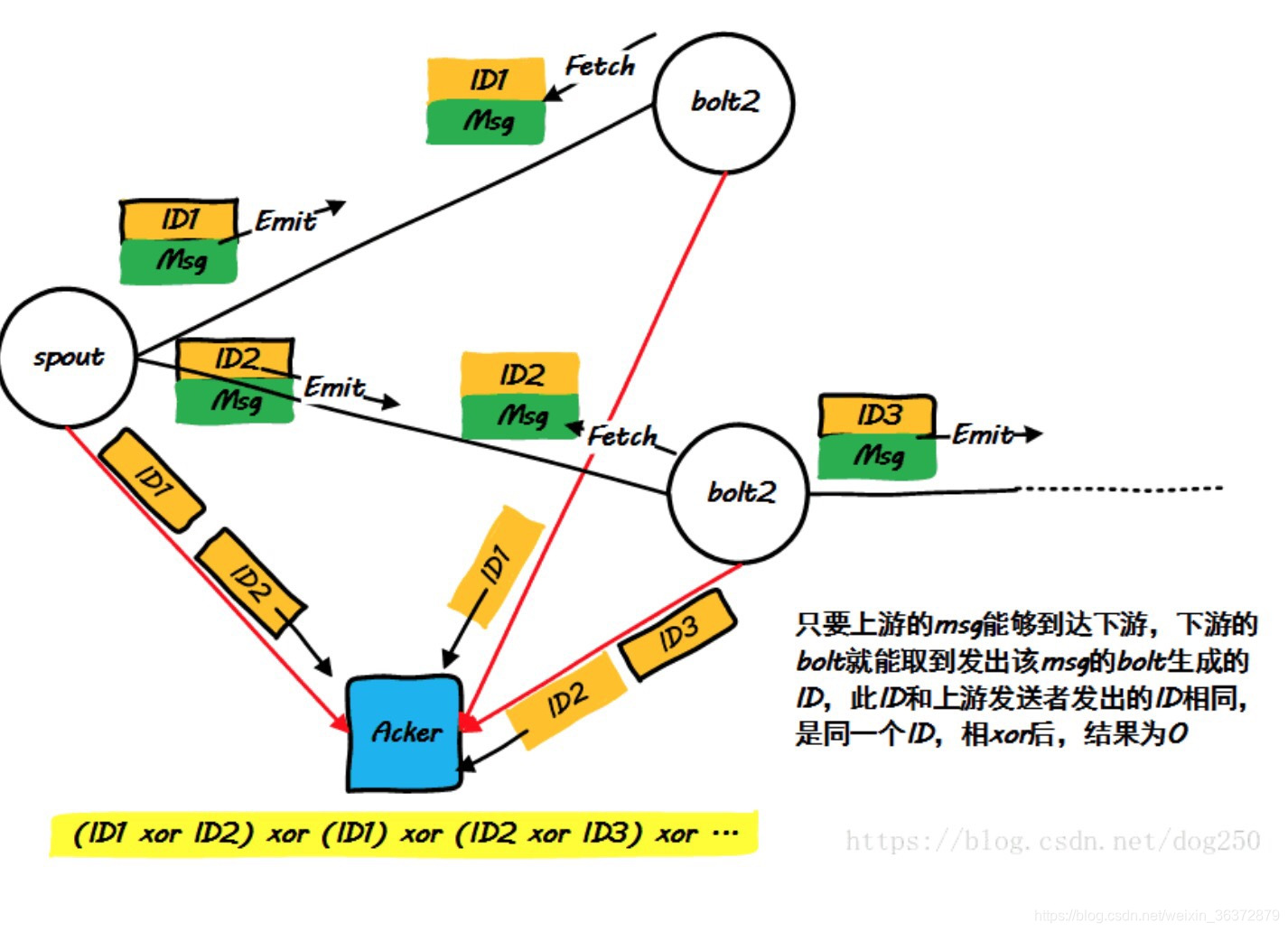
Acker 异或算法
原理:收集所有的spout和bolt接受ID和发送ID,然后异或,如果为0,说明记录正确