一. requests基础
1. requets 作用
作用:发送网络请求,返回相应数据
中文文档API:reques介绍
2. requests中解决编码的方法
response.contnet.decode()
response.content.decode('gbk')
response.text
response.encoding = 'utf-8'
3. response.text 和response.content的区别
response.text:
- 类型:str
- 修改编码方式:response.encoding = ‘utf-8’
response.content:
- 类型:bytes
- 修改编码方式:response.content.decode(‘utf-8’)
4. 发送简单的请求
response = requests.get(url)
response的常用方法
response.text
response.content
response.status_code
response.requests.headers
response.headers
5. 下载图片
import requests
response = requests.get('图片url')
with open('name.pan', 'wb') as f:
f.write(response.content)
6. 发送带header请求
为什么要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
header的形式:字典
headers = {''User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6'}
用法:
requests.get(url,headers=header)
7. 发送代参数的请求
什么叫做请求参数
http://www.webkaka.com/tuo/server/2015/1119
https://www.baidu.com/s?wd=python&c=b
参数的形式:字典
kw = {'wd':'zero'}
用法:
requests.get(url,params=kw)
8. 练习
贴吧练习:
面向对象的方法
import requests
class TiebaSpider(object):
def __init__(self, tieba_name):
self.tieba_name = tieba_name
self.url_temp = "http://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
def parse_url(self,url)
'''访问url'''
response = requests.get(url,headers=self.headers)
return response.text
def save_html(self,url_html, page_num)
'''保存页面'''
file_path = "《{}》-第{}页".format(self.tieba_name, page_num)
with open(file_path+'.html','w') as f:
f.write(url_html)
def get_url_list(self):
'''构造url列表'''
#方法1
url_list = [ ]
fro i in range(10):
url_list.append(self.url_temp.format(i*50))
return url_list
# 方法2
return [self.url_temp.format(i*50) for i in range(10)]
def run(self):
'''主要逻辑'''
# 1 构造url
url_list = self.get_url_list()
# 2 访问url
for url in url_list:
url_html = self.parse_url(url)
# 3 保存
page_num = url_list.index(url) + 1 # 获取页码
self.asve_html(url_html, page_num)
if __name__ == '__main__'
name = input('请输入你想要爬取的论坛名称:')
tb_spider = TiebaSpider(name)
tb_spider.run()
二. requests进阶
1.发送post请求
那些地方会用到post请求:
- 登录注册(post比get安全)
- 传输大文本(post请求对数据长度没有要求)
爬虫也需要在这两个地⽅模拟浏览器发送post请求
用法
respons = requests.post(url,data= data,headers= headers)
百度翻译案例
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
data = {
'from': 'en',
'to': 'zh',
'query': 'hello',
'transtype': ' realtime',
'simple_means_flag': ' 3',
'sign': '54706.276099',
'token': 'ae11be6979809815cc7e99bc1b05cb77',
}
post_url = 'https://fanyi.baidu.com/v2transapi'
response = requests.post(post_url,data= data,headers= headers)
print(response.text)
手机版:
import requests
import json
import sys
query_string = sys.argv[1]
headers = {"User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like M
}
post_data = {
#'query':'⼈⽣苦短',
'query':query_string
'from':'zh',
'to':'en'
}
post_url = 'https://fanyi.baidu.com/basetrans'
r = requests.post(post_url,data=post_data,headers=headers)
# print(r)
dict_ret = json.loads(r.content.decode())
ret = dict_ret['trans'][0]['dst']
print(ret)
2.使用代理
问什么需要代理?
- 让服务器以为不是同一个客户端在请求
- 防⽌我们的真实地址被泄露,防⽌被追究
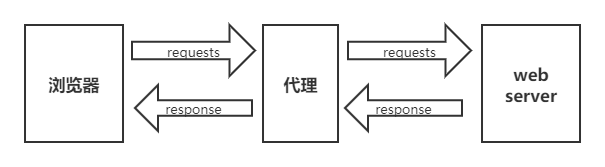
用法:
# proxies的形式:字典
proxies = {
'http':'http://12.34.56.79:9527',
'https':'http://12.34.56.79:9527',
}
requests.get('http://www.baidu.com',proxies = proxies)
案例
import requests
proxies = {'http':'http://117.191.11.112'}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
r = requests.get('http://www.baidu.com',proxies = proxies,headers = headers)
print(r.sratus_code)
使用代理IP
准备⼀堆的IP地址,组成IP池,随机选择⼀个IP来⽤
检查IP的可⽤性
1.可以使⽤requests检查
2.在线代理IP质量检查的⽹站
cookie和session区别
- cookie数据存放在客户端的浏览器上,session数据放在服务器上。
- cookie不是很安全,别⼈可以分析存放在本地的cookie并进⾏cookie欺骗
- session会在⼀定时间内保存在服务器上。当访问增多,会⽐较占⽤你服
务器的性能 - 单个cookie保存的数据不能超过4K,很多浏览器都限制⼀个站点最多保存
20个cookie
爬⾍处理cookie和session
带上cookie、session的好处:能够请求到登录之后的⻚⾯
带上cookie、session的弊端:⼀套cookie和session往往和⼀个⽤户对应请求
太多,请求次数太多,容易被服务器识别为爬⾍
不需要cookie的时候尽量不去使⽤cookie
但是为了获取登录之后的⻚⾯,我们必须发送带有cookies的请求
session用法:
requests提供了⼀个叫做session类,来实现客户端和服务端的会话保持
使⽤⽅法
1 实例化⼀个session对象
2 让session发送get或者post请求
session = requests.session()
response = session.get(url,headers)
请求登录之后的⽹站的思路:
- 实例化session
- 先使用session发送请求,登录对应网站,把cookie保存在session中
- 在使⽤session请求登录之后才能访问的⽹站,session能够⾃动携带登录成功时保存在其中的cookie,进⾏请求
案例 人人网
import requests
session = requests.session()
post_url = "http://www.renren.com/PLogin.do"
post_data = {'email':'[email protected]','password':''}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
session.post(post_url,data=post_data,headers=headers)
r = session.get('http://www.renren.com/474133869/profile',headers = headers)
with open('renren.html.html','w') as f:
f.write(r.text)
使用cookies获取登录后的页面
- cookie过期时间很⻓的⽹站
- 在cookie过期之前能够拿到所有的数据
- 配合其他程序⼀起使⽤,其他程序专⻔获取cookie,当前程序专⻔请求⻚⾯
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
cookie = 'xxxxxxxx'
cookie = {i.split("=")[0]:i.split("=")[1] for i in cookie.split("; ")}
r = requests.get('http://www.renren.com/474133869/profile',headers = headers)
with open('renren2.html','w') as f:
f.write(r.text)
三. requests小技巧
requests小技巧
1 requests.utils.dict_from_cookiejar 把cookie对象转化为字典
2 请求SSL证书验证
response = requests.get('https://www.12306.cn/mormhweb/',verify=False)
3 设置超时
response = requests.get(url,timeout=10)
4 配合状态码判断是否请求成功
assert response.status_code == 200
URL地址的编解码
requests.utils.uunquote() # 解码
requests.utils.quote() # 编码
retrying
import requests
from retrying import retry
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6
@retry(stop_max_attempt_number = 3)}
def _parse_url(url):
print('代码执⾏了⼏次?')
response = requests.get(url,headers=headers,timeout=3)
assert response.status_code == 200
return response.content.decode()
def parse_url(url):
try:
html_str = _parse_url(url)
except:
html_str = None
return html_str
if __name__ == '__main__':
url = 'http://www.baidu.com'
print(parse_url(url))
