前言
上一节介绍了,Zookeeper是一种分布式的、开放源码的分布式应用程序协调服务,该服务用于维护配置信息、提供分布式同步以及分组等事务。
Zookeeper简介
Zookeeper为其他集群提供服务,比如服务的主从选举、客户端的注册监听,Zookeeper内部也是一个集群,且通常节点的数目是奇数个(划重点),只要有半数以上的节点存活,Zookeeper就能为分布式程序(Client)提供服务,故其可靠性极高。
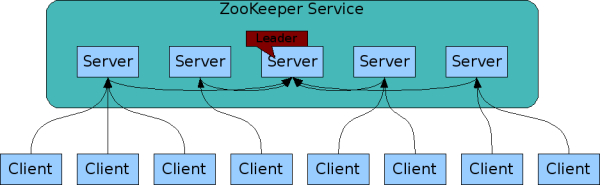
应用场景
- 主从协调(选举master);
- 服务器节点动态上下线;
- 统一配置管理;
- 分布式共享锁;
- 统一名称服务等;
实质作用
- 管理client的状态信息(描述性信息,非实业务数据);
- 为client程序提供数据节点监听;
选举方式
- 方式一(初次启动)
以五台节点构成的Zookeeper集群为例,这五台节点名分别为server1、server2、server3、server4、server5,id分别为1、2、3、4、5,假设这五台节点配置一致且都是第一次启动,那么他们的主从选举过程应该是这样的:
- server1率先启动并向集群发送了一条报告,稍作等待后server1没有收到任何来自集群内的回应,它的选举状态便保持着LOOKING(选举状态)状态;
- server2启动之后也向集群发送了一条报告,得到了server1的回复,于是server2与server1建立通信,这时候的投票结果是server1选自己,并把选自己的消息告诉了server2,server2也选自己,并把选自己的消息告诉了server1,这个时候根据之前设定的id来看,server1的id是1,server2的id是2,故本次选举server2获胜,但是由于该结果只有server1和server2两台机器认可,没有达到五台节点的半数以上的标准,因此两台机器的状态,继续保持为LOOKING。
- server3启动并向集群发送报告后,server1选自己,server2选自己,server3选自己,但是由于server3的id最大,因此server3胜出,这个结果目前server1、server2、server3军认同,且投认同票数已经占了集群节点半数以上,故server3变成leader。
- server4和server5启动后,Zookeeper集群已经产生leader,因此server4、server5只能和server1、server2一样充当随从服务。
- 方式二(宕机选举)
上述选举过程server3是主节点,运行一段时间后,主节点server3宕机,现在集群没有主节点,需要重新进行选举,介绍选举过程之前我们介绍三个概念:
需要加入Zxid数据id、leader id和逻辑时钟。
Zxid:即数据id,数据越新的节点其Zxid越大,原则上数据每次更新都会更新Zxid;
Serverid:搭建zookeeper集群时,我们会为每个几点设定一个id,在这里server1的id为1,server2的id为2,以此类推;
Epoch:即逻辑时钟,逻辑时钟的值从0开始递增,每次选举对应一个值,相同的Epoch值代表着各个节点处于同一批选举过程,每个节点除了维护自身的Epoch值外,在选举过程中还会收到别的节点发来的Epoch值信息,根据对比结果,执行不一样的操作(逻辑时钟小的节点将作废自我选票,重新投票并修改自己的逻辑时钟,直到与其他节点的逻辑时钟保持一致,即所有几点均处于同一轮选举);
这时候它的选举过程是这样的:
- 第一轮投票,server1投自己并告诉[server2,server4,server5],server2投自己并告诉[server1,server4,server5],server4投自己并告诉[server1,server2,server5],server5投自己并告诉[server1,server2,server4],同时各节点更新自己的Epoch值,与其他节点传来的Epoch值做比较,如果有有节点发现自己的Epoch值小于其他节点,则该节点重新投票并更新自己的Epoch值,如此调整直到所有节点(除宕机的server3)的Epoch值统一;
- Epoch值统一之后,比对Zxid即数据id,Zxid大的被选为leader。
- 若存在Epoch值统一,Zxid相同的情况下,则Serverid大的节点当选leader。
脑裂问题
之前我们介绍,zookeeper的节点个数设定为奇数个,之所以设定为奇数个是为了防止脑裂问题。
- 何谓之脑裂?
即一个主从集群里理论上只会存在一个master,如果出现两个及以上master的话,就会存在脑裂问题。比如server3为主节点,因为网络抖动等原因,server3与其他从节点的心跳超时陷入假死,其他节点以为master挂掉了,遂又进行选举,选举过后产生一个新的master节点server5,这时候陷入假死状态的server3恢复了,Zookeeper集群就存在两个Master:server3、server5。 - 为何会发生脑裂?
server5当选新的master之后,作为client会获得master切换的消息,但因为Zookeeper需要一个个去通知,所以会有一些延时,这时候可能就存在即有client去连接sever3这个老master,也有client去连接server5这个新master,这就会导致很严重的问题。 - Zookeeper是如何预防脑裂问题的?
- 节点数目大于等于3且为奇数台,节点数大于等于3且为奇数台是因为ZooKeeper规定集群内节点存活半数以上(不包含半数)集群就是可用的,如果节点数为2,宕掉一台之后集群就不可用;如果节点数为3,宕掉一台后,存活的两台仍大于整个集群的几点数半数以上,所以仍然可以选举出master;如果节点数为4,宕掉一台后,存活节点剩下3个仍能选举master,如果宕掉两台,则不能再选举master(不大于半数),可见4台节点与3台节点的容忍度是一样的,所以我们建议设定奇数台;
- 冗余通信的方式,添加冗余的心跳线,例如双线条线。尽量减少“裂脑”发生机会;
- 设定共享磁盘锁,通过锁的机制让脑裂的两台节点中只能有一台节点能够访问共享磁盘。
跳转
【大数据入门笔记系列】写在前面
【大数据入门笔记系列】第一节 大数据常用组件
【大数据入门笔记系列】第二节 Zookeeper简介
【大数据入门笔记系列】第三节 Hdfs写数据处理流程
