import numpy as np #科学计算基础库,多维数组对象ndarray
import pandas as pd #数据处理库,DataFrame(二维数组)
import matplotlib as mpl #画图基础库
import matplotlib.pyplot as plt #最常用的绘图库
from scipy import stats #scipy库的stats模块
mpl.rcParams["font.family"]="SimHei" #使用支持的黑体中文字体
mpl.rcParams["axes.unicode_minus"]=False # 用来正常显示负号 "-"
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
# % matplotlib inline #jupyter中用于直接嵌入图表,不用plt.show()
import warnings
warnings.filterwarnings("ignore") #用于排除警告
#用于显示使用库的版本
print("numpy_" + np.__version__)
print("pandas_" + pd.__version__)
print("matplotlib_"+ mpl.__version__)
numpy_1.17.4
pandas_0.23.4
matplotlib_2.2.3
一、单变量的样本分布检验
问题: 如何检验数据的抽样的某个维度是符合某种分布的?譬如,是否是正态分布,或,是否与总体的分布相同等?
1.1.用数字特征检验
分布的数字特征是否与理论的数字特征一致?
例:t分布序列数字特征检验
# 例:生成一个t分布序列
import numpy as np
from scipy import stats #scipy库的stats模块
np.random.seed(10) # 先生成一个种子生成器,以后生成的随机数就是一定的,参数为任意数字
x = stats.t.rvs(10, size=10000) #生成服从t分布,自由度为10的10000个随机数(rvs生成随机数)
#display(x)
#计算其数字特征
print(np.min(x), np.max(x),np.mean(x),np.median(x),np.var(x),np.std(x),stats.mode(x))
#最小值,最大值,均值,中位数,方差,标准差,众数及个数
display(stats.describe(x)) #使用stats.describe()做统计
n, (smin, smax), sm, sv, ss, sk = stats.describe(x)
print( n, (smin, smax), sm, sv, ss, sk) #数量,(最小值,最大值),均值,方差,偏度,峰度
-11.589863255656732 5.703833815270785 0.007167368275245448 0.011582997970647449 1.2174942741284087 1.1034012298925575 ModeResult(mode=array([-11.58986326]), count=array([1]))
DescribeResult(nobs=10000, minmax=(-11.589863255656732, 5.703833815270785), mean=0.007167368275245448, variance=1.2176160357319818, skewness=-0.1220063780573783, kurtosis=1.8544784100842557)
10000 (-11.589863255656732, 5.703833815270785) 0.007167368275245448 1.2176160357319818 -0.1220063780573783 1.8544784100842557
#计算理论数字特征---发现随机样本和理论还是存在差异的
m, v, s, k = stats.t.stats(10, moments='mvsk')
print(m,v,s,k)#m均值,v方差,s偏度,k峰度
0.0 1.25 0.0 1.0
1.2. T-test(严格的检验)
t-test检验是检验一个或两个样本之间的均值是否有明显的差别,也就是检验单变量对因变量的影响。
stats.ttest_1samp(x,m) # 用t-test检验来检验样本数据均值和理论均值差异性检验。一组数据与指定均值比较。
stats.ttest_ind(rvs1,rvs2) # 对两个样本进行t检验
#结果分析:p值越小我们拒绝原假设(样本是t分布)
#比较两个样本(比较两组均值)
带参数的假设检验
# 单样本检验
import numpy as np
from scipy import stats
rvs1=stats.norm.rvs(loc=5,scale=10,size=50000) #均值为5,标准差为10的正态分布,随机随机生成50000个样本
display(stats.describe(rvs1)) #输出统计特征值
display(stats.ttest_1samp(rvs1,[1,5])) #单样本与均值=1比较,拒绝原假设(均值存在差异),与均值=5比较,接受原假设(均值不存在差异)
display(stats.ttest_1samp(rvs1,3)) #样本与均值=3比较,p=0.0,拒绝原假设(均值存在差异)
DescribeResult(nobs=50000, minmax=(-36.99682593051555, 46.54608091676229), mean=4.9810497540176195, variance=100.12070769576394, skewness=0.010258428597114096, kurtosis=0.006975059803436157)
Ttest_1sampResult(statistic=array([88.96530093, -0.42348487]), pvalue=array([0. , 0.67194336]))
Ttest_1sampResult(statistic=44.27090802960711, pvalue=0.0)
# 两个样本的检验
import numpy as np
from scipy import stats
rvs1=stats.norm.rvs(loc=5,scale=10,size=50000) #均值为5,标准差为10的正态分布,随机随机生成50000个样本
display(stats.describe(rvs1)) #输出统计特征值
rvs2=stats.norm.rvs(loc=5,scale=10,size=50000)
display(stats.ttest_ind(rvs1,rvs2)) #对两个样本进行t检验,pvalue即p值,接受原假设,即样本均值和理论均值不存在差异
rvs3=stats.norm.rvs(loc=8,scale=10,size=50000)
display(stats.ttest_ind(rvs1,rvs3)) #p=0.0,拒绝原假设,即样本均值和理论均值存在差异
DescribeResult(nobs=50000, minmax=(-34.84341762895822, 48.77390861744411), mean=4.913290841946327, variance=99.5744094623477, skewness=-0.0034722709934522345, kurtosis=0.018126574218927605)
Ttest_indResult(statistic=-1.7861203119186366, pvalue=0.07408280895829028)
Ttest_indResult(statistic=-48.627977359124166, pvalue=0.0)
1.3. K-S test (严格的检验)
stats.kstest(x,‘t’,(10,)) #检验样本数据x是否是自由度为10的t分布
K-S test 还可以检验其他分布:正态分布…
stats.kstest(x,‘norm’,(x.mean(),x.std())) #对x进行检验。正态分布有两个参数-均值和期望;分别样本的均值和方差来估计。
使用K-S test对x进行t分布和正态分布检验时,如果都不能拒绝(因为正态分布和t分布在中间的时候非常像,但是尾部有显著差别)。
这时候就用卡方检验…
#如果比较两组分布
Kolmogorov-Smirnov双样本检测ks_2samp
stats.ks_2samp(rvs1,rvs2)
stats.ks_2samp(rvs1,rvs3)
import numpy as np
from scipy import stats
x1 = stats.t.rvs(10, size=100)
x2 = stats.norm.rvs(loc=10,scale=10,size=1000)
display(stats.kstest(x1,'t',(10,))) #x1是否服从自由度为10的t分布,p>0.05接受原假设,服从t分布
display(stats.kstest(x1,'norm',(x1.mean(),x1.std()))) #x1是否服从正态分布,p>0.05接受原假设,服从正态分布
#使用K-S test对x进行t分布和正态分布检验时,如果都不能拒绝(因为正态分布和t分布在中间的时候非常像,但是尾部有显著差别)。 这时候就用卡方检验...
display(stats.kstest(x2,'t',(10,))) #x2是否服从自由度为10的t分布,p<0.05拒绝原假设,不服从t分布
display(stats.kstest(x2,'norm',(x2.mean(),x2.std()))) #x2是否服从正态分布,p>0.05接受原假设,服从正态分布
display(stats.ks_2samp(x1,x2)) #检查两样本之间是否存在差异,p<0.05,拒绝原假设
KstestResult(statistic=0.06866106990810628, pvalue=0.7449808598539311)
KstestResult(statistic=0.04853095923048054, pvalue=0.9725714755831804)
KstestResult(statistic=0.7704367841895967, pvalue=0.0)
KstestResult(statistic=0.014475654942241234, pvalue=0.9848110113960367)
Ks_2sampResult(statistic=0.776, pvalue=2.695396223072419e-49)
1.4. 卡方检验
卡方检验是在给定样本X1,X2,……Xn,观察值x1,x2……xn的情况下,检验总体是否服从有关分布F(X)的一种非参数统计方法。
(1)建立零假设和备择假设:H0:总体分布函数为F(x);H1:总体分布函数不为F(x)。
(2)构造和计算统计量
◆把实轴(-∞,+∞)分成k个不相交的区间(-∞,a1],(a1,a2]……(ak-1,+∞)
●设样本观察值x1,x2,…,xn 落入每个区间的实际频数为fi则实际频率为fi/n
◆当零假设成立时,样本值落在每个区间的概率pi;可以由分布函数F(x)精确计算,则每个区间的理论频数为n*pi
◆当假设成立时,理论频数np,与实际频数fi,应该相差很小
◆构造统计量
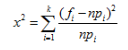
(3)设定显著性水平和确定否定域
◆给定显著性水平a。
◆在零假设成立时,x^2统计量服从自由度为k-1的卡方分布。
◆
(4)做出统计决策
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ffNwuKzc-1581155876675)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200208180158879.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY4NTM4OA==,size_16,color_FFFFFF,t_70) 参考文献:https://wenku.baidu.com/view/cc9209a3760bf78a6529647d27284b73f342365f.html
参考文献:https://wenku.baidu.com/view/cc9209a3760bf78a6529647d27284b73f342365f.html
#4、卡方检验
import numpy as np
import pandas as pd
from scipy import stats
x=stats.t.rvs(10,size=1000)
""" 用自定义的区间来做,强调了尾部,把中间当作一个,虽然中间数多但
是权重小,跟其他区间的权重是一样的,将相对明显的差别单列出来,以后
分析数据的时候都可以这样做,就比较某一段。"""
quantiles=[0.0,0.01,0.05,0.1,1-0.10,1-0.05,1-0.01,1.0] #分位数对应的百分比--概率分布函数。
crit=stats.t.ppf(quantiles,10) #确定理论的分为数在哪。分位数对应的百分比序列输入后,对应生成一个服从自由度为10的t分布的分位数。
#cdf:累计分布函数; ppf:分位点函数(CDF的逆)
print(crit)
print(np.histogram(x,bins=crit))#数据x落入到分位数确定的隔段中,以及分位数形成的隔段。
plt.hist(x,bins=crit) #数据x落在分位数确定的隔段中的直方图
n_sample=x.size #样本x数量
np.histogram(x,bins=crit) #数据x落入到分位数确定的隔段中,以及分位数形成的隔段。
print(np.histogram(x,bins=crit))
freqcount=np.histogram(x,bins=crit)[0] #数据x落入每段的数量--实际值。
tprob=np.diff(quantiles) #分位数百分比前后作差形成每段的概率。
tprob*n_sample #理论上落入每段的数量--理论值。(这个值一般和实际值freqcount进行比较,感性认识下差别)
nprob=np.diff(stats.norm.cdf(crit))#假设是正态分布,进行构造。stats.norm.cdf():正态分布累计概率密度函数.
nprob*n_sample #正态分布的理论值 (这个值一般和实际值freqcount进行比较,感性认识下差别)
"""
卡方检验。 每一块理论上应该落多少个,其实就是二项分布,在中心极限定
理中:本来有多少概率落在里面,与实际落进去的有误差的,这个误差是受二
项分布影响的,当二项分布数比较大的时候可以将他构造成一个正态分布,标
准化后进行平方和,也就是每一块理论上都有一个概率值落在里面,但是和实
际值有差别,这个差别我们认为是服从正态分布的。每一个构造为:
[(理论值N0-实际值N)/sqrt(二项分布的误差nprob)]~N(0,1),将其平
方和,然后将每段都加起来,构造的随机变量服从卡方分布。
"""
tch,tpval=stats.chisquare(freqcount,tprob*n_sample) #卡方检验。(判断p值是否拒绝原假设:数据为卡方分布)
print(tch,tpval)
nch,npval=stats.chisquare(freqcount,nprob*n_sample) #看看是否符合正态分布
print(nch,npval)
"""最终结果是:不能拒绝它是来自t分布,但是拒绝它是来自正态分布的。
为什么要用卡方分布呢:对尾部特别感兴趣的时候,就需要检验下。卡方检验
完全是自己构造,对于区间完全是自己选的,尾部有多少自己来定。非常强大的
比k-s还要强大。卡方检验是根据(每个区间的)分布函数来算的,每段理论有多
少个和实际多少个进行比较的。还有一种是根据样本来估计一些数字特征来检验。"""
#基于样本估计的数字特征进行卡方检验
tdof,tloc,tscale=stats.t.fit(x) #用t分布去模拟数据,输出最好的变量:自由度,期望,方差。
nloc,nscale=stats.norm.fit(x) #用正态分布去模拟现在的样本
tprob=np.diff(stats.t.cdf(crit,tdof,loc=tloc,scale=tscale)) #这个是用理论值算出来的,刚才的是分位数算出来的。
nprob=np.diff(stats.norm.cdf(crit,loc=nloc,scale=nscale))
tch,tpval=stats.chisquare(freqcount,tprob*n_sample)
print(tch,tpval)
nch,npval=stats.chisquare(freqcount,nprob*n_sample)
print(nch,npval)
"""两种结果可能都不能拒绝,这种方法也不是太好。为什么不如直接刚才的尾部卡方检验好呢?
因为在中间核心的部分,正态分布和t分布还是比较像的,只是在尾部比较像的,全体的去考虑,
用一个拟合曲线去考虑,尾部的区别被中间相同性掩盖了。"""
[ -inf -2.76376946 -1.81246112 -1.37218364 1.37218364 1.81246112
2.76376946 inf]
(array([ 10, 35, 50, 817, 42, 36, 10], dtype=int64), array([ -inf, -2.76376946, -1.81246112, -1.37218364, 1.37218364,
1.81246112, 2.76376946, inf]))
(array([ 10, 35, 50, 817, 42, 36, 10], dtype=int64), array([ -inf, -2.76376946, -1.81246112, -1.37218364, 1.37218364,
1.81246112, 2.76376946, inf]))
2.666249999999988 0.8494173678927932
37.95236071494776 1.1477081193011593e-06
2.1367205239473317 0.9067045984049802
14.020935348692674 0.029403176707172213

1.5. 正态分布检验
stats.normaltest(x) #检验x字段样本是否符合正态分布
#5、正态分布检验
import numpy as np
import pandas as pd
from scipy import stats
x=stats.t.rvs(10,size=1000)
stats.normaltest(x) #结果是拒绝的。
NormaltestResult(statistic=61.25169685165855, pvalue=5.0045268662821025e-14)
案例:
数据源:https://download.csdn.net/download/weixin_41685388/12144418
# import... 略(见文章头部)
'''
某餐厅顾客消费记录.
解释数据结构:
total_bill:消费,tip:小费,sex:服务员性别,
smoker:是否抽烟,day:星期几,time:午餐/晚餐,size:本桌人数
'''
tips = pd.read_csv(r"E:\tips.csv",encoding='utf-8') #导入csv格式数据
display(tips.sample(5)) #随机抽样5行
print("tips['tip']:",stats.normaltest(tips['tip'])) #结果拒绝
tips['tip_pct']=tips['tip']/tips['total_bill']
plt.hist(tips['tip_pct'],bins=50) #视图感性分析:很像正态分布
plt.title("tips['tip']/tips['total_bill']分布直方图")
print("tips['tip']/tips['total_bill']:",stats.normaltest(tips['tip_pct'])) #结果拒绝
"""但是结果比较奇怪,猜测是图像右边尾巴的异常点引起的。"""
print(tips[tips['tip_pct']>0.3]) #查看异常点,只有三个
tips1=tips.drop([67,172,178]) #异常点太少也不好分析,直接去除
stats.normaltest(tips1['tip_pct']) #结果接受原假设
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 166 | 20.76 | 2.24 | Male | No | Sun | Dinner | 2 |
| 161 | 12.66 | 2.50 | Male | No | Sun | Dinner | 2 |
| 238 | 35.83 | 4.67 | Female | No | Sat | Dinner | 3 |
| 147 | 11.87 | 1.63 | Female | No | Thur | Lunch | 2 |
| 219 | 30.14 | 3.09 | Female | Yes | Sat | Dinner | 4 |
tips['tip']: NormaltestResult(statistic=79.37862574074785, pvalue=5.796294322907102e-18)
tips['tip']/tips['total_bill']: NormaltestResult(statistic=220.8879728815828, pvalue=1.0833932598440914e-48)
total_bill tip sex smoker day time size tip_pct
67 3.07 1.00 Female Yes Sat Dinner 1 0.325733
172 7.25 5.15 Male Yes Sun Dinner 2 0.710345
178 9.60 4.00 Female Yes Sun Dinner 2 0.416667
NormaltestResult(statistic=0.7724869721322898, pvalue=0.6796050311777623)

1.6.帕累托分布
帕累托分析依据的原理是20/80定律,80%的效益常常来自于20%的投入,而其他80%的投入却只产生了20%的效益,这说明,同样的投入在不同的地方会产生不同的效益。
帕累托分布图的绘制过程是按照贡献度从高到低依次排列,并绘制累积贡献度曲线。当样本数量足够大时,贡献度通常会呈现20/80分布。
在帕累托分布中,如果X是一个随机变量, 则X的概率分布如下面的公式所示:
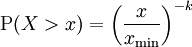
其中x是任何一个大于xmin的数,xmin是X最小的可能值(正数),k是为正的参数。帕累托分布曲线族是由两个数量参数化的:xmin和k。分布密度则为
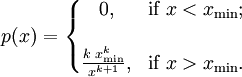

#帕累托分布
#P(X>x)=(x/xmin)**(-k)
#E(P)=xmin*k/(k-1)
#构造一组帕累托分布,均值为50,k值(shape为1.2),且具有大于1000的点
#size为多少才有把我里面有大于1000的数
x=stats.pareto.rvs(b=1.2,loc=50,size=1000)
p=1-stats.pareto.cdf(1000,b=1.2,loc=50)
print(p)
#0.0002671355417115384 不存在
print(1-stats.binom.cdf(1,20000,p))
#0.9696783490389687
plt.plot(-np.sort(-x),"ro")
plt.show()

