[提前声明]
文章由作者:张耀峰 结合自己生产中的使用经验整理,最终形成简单易懂的文章
写作不易,转载请注明,谢谢!
代码案例地址: ?https://github.com/Mydreamandreality/sparkResearch
一文读懂系列:Kafka基本概念
- 我们一般学习一个新的技能,都会经历如下这么一个阶段:
这是个什么玩意啊,它能做什么啊,怎么做啊,为什么它就能做啊,哦这样啊.好厉害啊~- 我就按照这个顺序把kafka和spark,es给你们讲明白咯
什么是kafka?
- Kafka准确的说是
分布式消息系统 - 要理解什么是
分布式消息系统,我们要先了解它的应用场景何在
kafka的应用场景
-
可以这么说,我们生活在一个数据大爆炸的时代,各行各业的数据大量的增长,给我们的业务带来了很大的压力,但是同时,巨大的数据也给我们带来了巨大的隐形财富
-
那么这个时候我们就面临一个巨大的挑战
- 如何把巨大的业务数据接入到我们的大数据分析平台,
- 其次就是如何分析收集到的信息
-
欸,这个时候kafka就应运而生啦
-
kafka是专为分布式高吞吐量系统设计的
-
它的主要特性如下:
- 应用解耦,异步消息,流量削峰,高性能,高可用,高容错,内置分区等等
-
目前主流的分布式消息队列还有很多,比如:
- ActiveMQ
- RabbitMQ
- ZeroMQ
- 等等
- [目前各方面综合性能最好的理论上讲是RabbitMQ]
-
如上不同的分布式消息队列各自的适用场景都不同,它们之间详细的比较可以查看其它博主的文章
- 我在这里举一个kafka的生产应用场景
- 日志处理 [逻辑如下图]
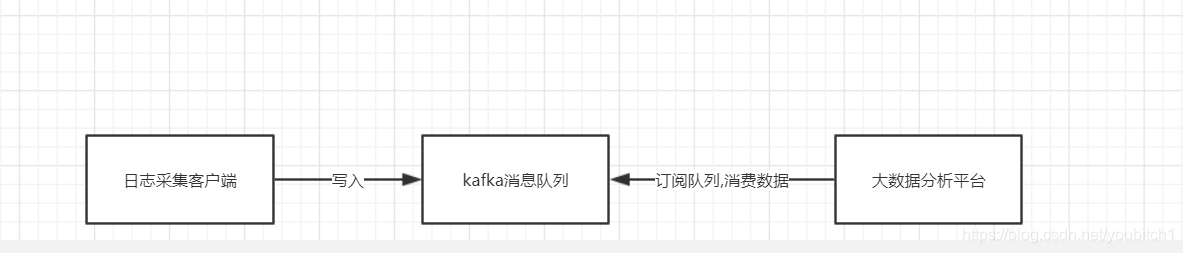
- 首先我们有一个日志采集客户端,负责采集我们服务器的日志,每天定时的写入kafka队列中
- kafka则负责日志数据的接受,存储,转发
- 我们的大数据分析平台负责 订阅并且消费kafka队列中的日志数据
分布式消息系统
那么我们知道kafka的应用场景后,就很好理解分布式消息系统了
- 分布式消息系统就是把数据从一个应用传递到另一个应用中,这样我们的程序就可以专注于数据,而不用额外的关注数据是如何共享的
- 我们的消息[
也就是数据]在应用程序和消息系统之间是异步队列
消息模式
- 在kafka中,我们有两种类型的消费模式
- 一:点对点模式
- 二:发布:订阅[
PUB-SUB]模式
点对点模式
-
消息生产者把消息存到队列中,然后消费者从队列中消息消息,
-
但是此处要注意的是:
- 消息被消费后,队列中就不再存储这条被消费的消息
-
点对点支持存在多个消费者,但是对一个
消息而言,只会有一个消费者可以消费 -
举个简单的例子:比如在淘宝的订单系统中:
- 商家是消息生产者:它告诉消息队列还有多少个库存
- 我们就是消息消费者,我们去购买商家的商品
- 这个时候一个商家订单会对应到我们每个消费者
- 我们都可以消费这条消息,但是我消费完后你就无法再重复消费了
点对点如下图所示:

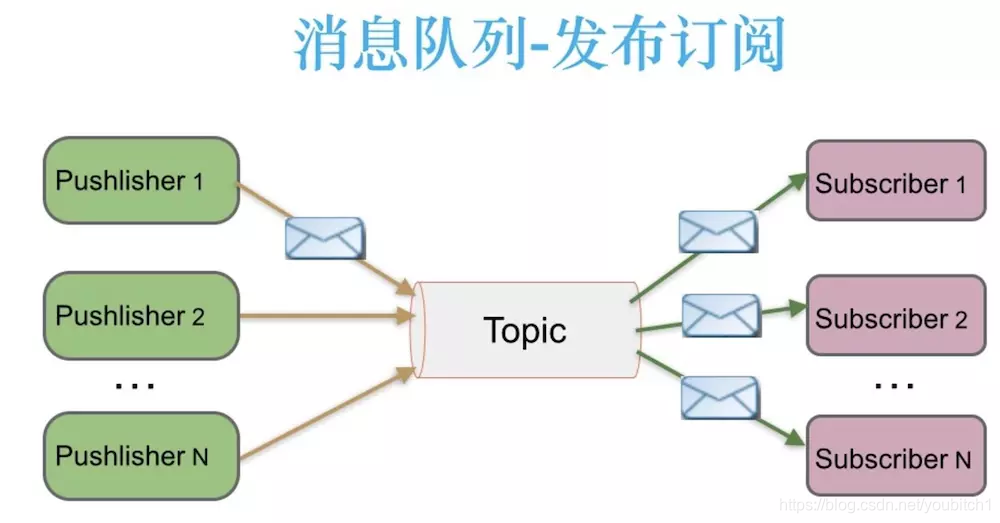
发布-订阅[pub-sub]
- 消息发布者把消息发布到主题[topic]中,同时可以有多个,订阅该主题的消费者进行消费,和点对点不同的是,发布订阅一个消息可以有多个消费者一起消费
发布-订阅如下图所示
kafka的优势
- 如下是几个kafka的优势,[当然还不止这些]
- 可靠性:Kafka是分布式,分区,复制和容错的
- 高可用:Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的
- 性能:Kafka对于发布和订阅消息都具有高吞吐量,就算我们是TB级别数据,它也保持稳定的性能,Kafka非常快,并保证零停机和零数据丢失
后续更新下kafka在java中的应用 以及和spark大数据框架整合的代码案例
