1 概述
Apache Kafka 是一个分布式高吞吐量的流消息系统,Kafka建立在ZooKeeper同步服务之上。它与Apache Storm和Spark完美集成,用于实时流数据分析,与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,数据副本和高度容错功能,因此非常适合大型消息处理应用场景。
Kafka架构简介请查看:https://my.oschina.net/feinik/blog/1806488
2 部署图
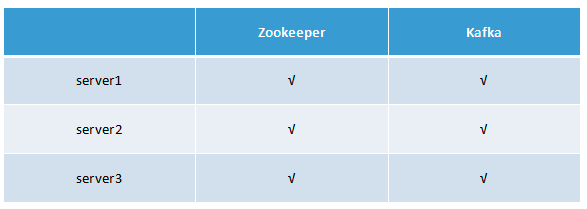
3 Kafka集群部署前环境准备
3.1 安装Java
推荐安装Java 8,请自行安装。
3.2 部署Zookeeper集群
3.2.1 下载Zookeeper安装包
这里部署的zk版本是:zookeeper-3.4.9.tar.gz
3.2.2 安装
1、首先在server1中安装
(1)解压:tar -zxvf zookeeper-3.4.9.tar.gz
(2)cd zookeeper-3.4.9/conf
(3)cp zoo_sample.cfg zoo.cfg
(4)修改zoo.cfg配置文件,内容如下
tickTime=2000
# zk数据目录
dataDir=/home/hadoop/app/zookeeper/data
# 客户端连接端口配置
clientPort=2181
initLimit=10
syncLimit=5
# 服务地址,2888为集群内个节点通信的端口,3888为leader选举时使用的端口
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:38882 、拷贝相同的一份zookeeper-3.4.9到server2、server3服务器中
3、 配置Zookeeper的环境变量并分别启动即可完成zk集群的部署
4 部署Kafka集群
4.1 安装并配置
这里安装的版本为:kafka_2.12-1.1.0.tgz
注:先在server1中安装,然后在拷贝一份至server2、server3服务器中
(1)解压
$tar -zxvf kafka_2.12-1.1.0.tgz -C /home/app(2)重命名
$mv kafka_2.12-1.1.0 kafka(3)配置Kafka的环境变量
(4)修改Kafka配置文件server.properties,修改如下配置项
- 修改broker(代理)id标识,集群中需要保证唯一
broker.id=1
- 修改日志存储目录配置
log.dirs=/home/app/kafka/log-data
- 修改Zookeeper的连接地址,Kafka自带了Zookeeper,但是这里我们配置成自己的zk集群地址
zookeeper.connect=server1:2181,server2:2181,server3:2181
(5)拷贝server1中部署好的kafka包到server2、server3服务器中
(6)修改server2中kafka的server.properties配置文件
broker.id=2
(7)修改server3中kafka的server.properties配置文件
broker.id=3
5 启动集群
5.1 先启动Zookeeper集群
分别在server1、server2、server3中使用如下命令启动
$zkServer.sh start注:也可以通过脚本来启动Zookeeper集群,前提是需要配置无密登录,脚本内容如下
#!/bin/bash if(( $# != 1 )) ; then echo "Usage: zk.sh {start|stop}"; exit; fi cuser=`whoami`; for i in {server1,server2,server3}; do echo ---------- $i---------------; ssh $cuser@$i "cd /home/app/zookeeper; ./bin/zkServer.sh $@"; done
5.2 启动Kafka集群
分别在server1、server2、server3中使用如下命令启动
$kafka-server-start.sh -daemon /home/app/kafka/config/server.properties注:也可以通过脚本来启动Kafka集群,脚本内容如下
#!/bin/bash cuser=`whoami`; for i in {server1,server2,server3}; do echo ---------- $i--------------; ssh $cuser@$i "/home/app/kafka/bin/kafka-server-start.sh -daemon /home/app/kafka/config/server.properties"; echo "start complate!" done
5.3 查看集群启动情况
通过jps命令来查看服务启动进程,server1、server2、server3都包含Kafka、QuorumPeerMain服务进程表示集群启动成功
$jps
5506 Kafka
5733 Jps
5212 QuorumPeerMain6 Kafka Java API访问
6.1 生产者发送消息
public class ProducerClient {
private Producer<String, String> producer;
@Before
public void init() {
Properties props = new Properties();
/**
* broker地址列表,无需指定集群中的所有broker地址,Producer会从给定的broker中找到其他broker的地址信息,
* 推荐这里配置两个,可以防止broker宕机产生无法连接的问题
*/
props.put("bootstrap.servers", "server1:9092,server2:9092");
/**
* 指定key的序列化方式,Kafka 默认提供了常用的几种Java对象类型的序列化类
*/
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<>(props);
}
@Test
public void send() throws Exception {
//此处未指定key,那么发送的多条消息会被均匀的分布在Topic的所有可用分区中
ProducerRecord<String, String> record = new ProducerRecord<>("test",
"hello word");
//消息的异步发送
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println("消息发送完成!");
}
});
}
@After
public void close() {
producer.close();
}
}注:消息的发送有三种方式:同步发送、异步发送、fire-and-forget(发送完并不关心发送结果)
同步发送:调用send方法后,返回Future对象,通过调用Future的get方法来同步等待消息的发送结果。
异步发送:调用send方法的时候指定一个回调函数,broker在接收成功消息后会回调该函数
fire-and-forget:调用send方法后并不关心发送的结果处理
6.2 消费者订阅并消费消息
public class ConsumerClient {
private Consumer<String, String> consumer;
@Before
public void init() {
Properties props = new Properties();
props.put("bootstrap.servers", "server1:9092,server2:9092");
//指定消费者群组标识
props.put("group.id", "g1");
//key与value的反序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
}
@Test
public void consume() {
//订阅主题为test的消息
consumer.subscribe(Collections.singletonList("test"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
String value = record.value();
System.out.println("接收到消息:" + value);
}
}
}
@After
public void close() {
consumer.close();
}
}7 总结
本文主要介绍了Kafka的分布式集群部署方式,以及Kafka依赖的第三方组件Zookeeper的集群部署,最后通过Kafka Java API来演示了生产者发送消息与消费者消费消息的示例代码,关于Kafka的其他使用细节,请查阅官网:http://kafka.apache.org/