(ROC分析图使用第八章集成学习中马疝病毒预测作为示例)
误差(error):学习器的实际预测输出与样本的真实输出之间的差异称为误差。

- 训练 / 测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对结果产生影响。通常采用分层采样。
- 在使用留出法时一般采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
- 通常将数据集D的大约 2/3 ~ 4/5 用于训练,剩余样本用于测试。

- 不受随机样本划分方式的影响;
- 评估结果比较准确(NFL定理同样适用)。
- 数据集比较大时,训练的计算开销可能难以忍受;
- 算法调参复杂。

- 自助法在数据集较小、难以有效划分训练 / 测试集时很有用;
- 能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处。
- 自助法产生的数据集改变了初始数据集的分布,会引入估计偏差。

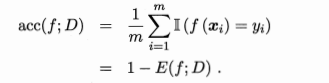
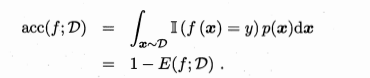
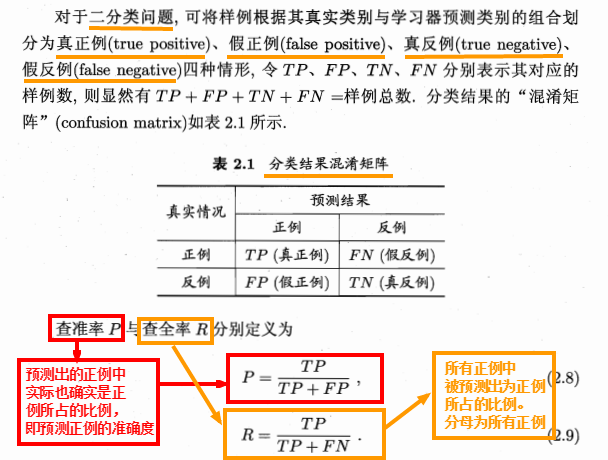
(可理解为查准率是分类为正例的准确率,查全率是正例被找出来的比例,用来判断正例是否都被找出来了,
所以当把所有例都判断为正例时,查准率很低,而查全率为100%。
但是当把所有例都判断为反例,查准率为100%而查全率为0.
因此二者经常是此消彼长。)
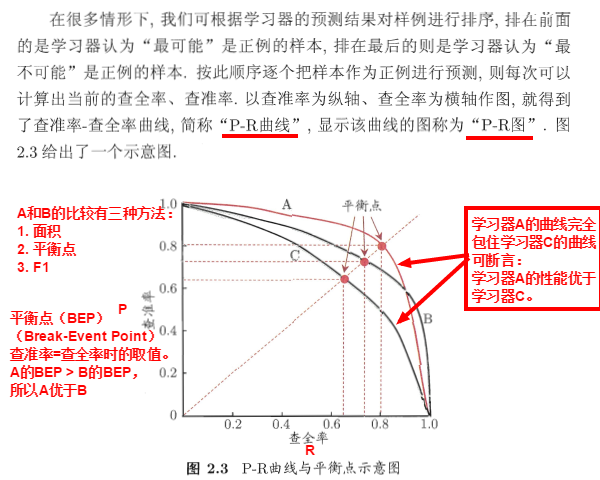


|

|

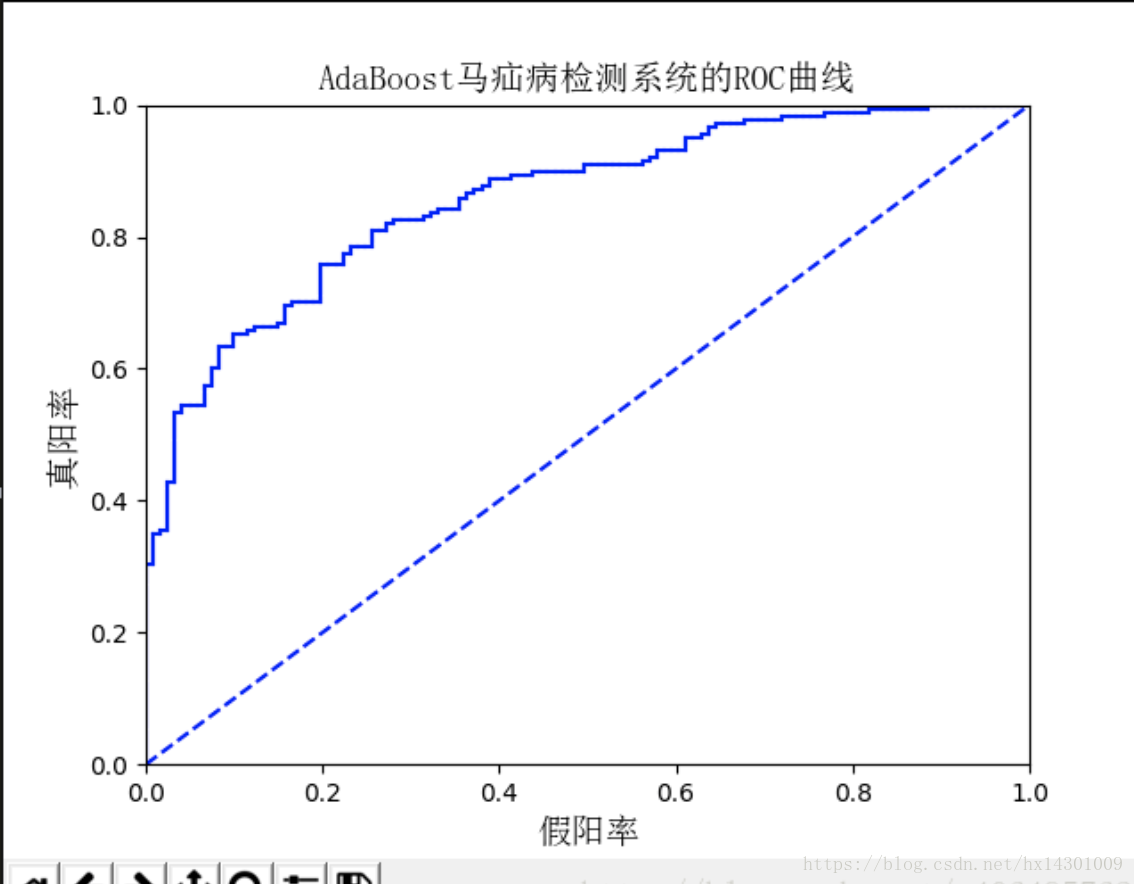
x轴为假正率(FPR):FP/FP+TN
y轴为真正率(TPR):TP/TP+FN
所以左下角(0,0)代表将所有点都判为负类,右上角(1,1)代表将所有点判为正类
完美分类器应该尽可能接近左上角
对ROC进行比较的一个指标就是曲线下围成的面积AUC(Area Under the Curve)
一个完美的分类器他的AUC为1.0
ROC曲线给出的是当阈值变化时假正率和真正率的变化情况。左下角的点所对应的将所有样例判为反例的情况,而右上角的点对应的则是将所有样例判为正例的情况。虚线给出的是随机猜测的结果曲线。
ROC曲线不但可以用于比较分类器,还可以基于成本效益(cost-versus-benefit)分析来做出决策。由于在不同的阈值下,不用的分类器的表现情况是可能各不相同,因此以某种方式将它们组合起来或许更有意义。如果只是简单地观察分类器的错误率,那么我们就难以得到这种更深入的洞察效果了。
在理想的情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在假阳率很低的同时获得了很高的真阳率。例如在垃圾邮件的过滤中,就相当于过滤了所有的垃圾邮件,但没有将任何合法邮件误识别为垃圾邮件而放入垃圾邮件额文件夹中。

对不同的ROC曲线进行比较的一个指标是曲线下的面积(Area Under the Curve,AUC)。AUC给出的是分类器的平均性能值,当然它并不能完全代替对整条曲线的观察。一个完美分类器的AUC为1.0,而随机猜测的AUC则为0.5。
这个ROC曲线是怎么画的呢?
对于分类器而言,都有概率输出的功能,拿逻辑回归来举例,我们得到的是该样本属于正样本的概率和属于负样本的概率,属于正样本的概率大,那么就判为正类,否则判为负类,那么实质上这里的阈值是0.5。
现在假设我们已经得到了所有样本的概率输出(属于正样本的概率),我们根据每个测试样本属于正样本的概率值从大到小排序。如下图所示:
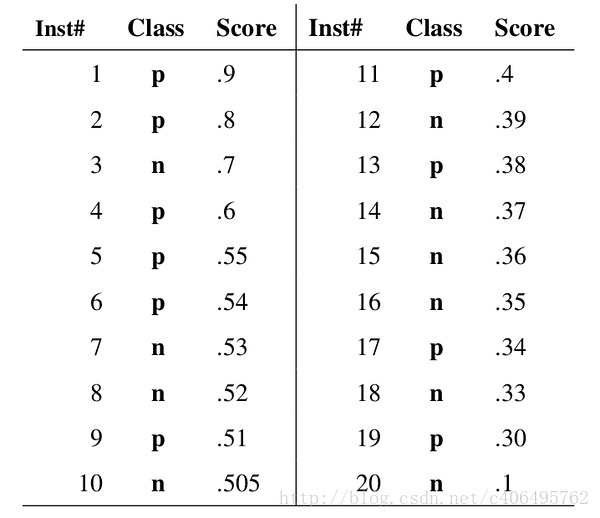
图中共有20个测试样本,“Inst”一栏表示样本编号,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。其中,一共10个正样本,10个负样本。接下来,我们从高到低,依次将“Score”值作为阈值,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。
举例来说:
- 当阈值为0.9时,样本1的“Score”值为0.9,大于等于阈值,那么样本1为正类,其余为负类,则TPR=TP/(TP+FN)=1/10=0.1,FPR=FP/(FP+TN)=0/10=0;
- 当阈值为0.8时,样本1的“Score”值为0.9,样本2的“Score”值为0.8,大于等于阈值,那么样本1,2为正类,其余为负类,则TPR=2/10=0.2,FPR=0/10=0;
- 当阈值为0.7时,样本1,2,3的”Score”值大于等于阈值,那么样本1,2,3为正类,其余为负类,则TPR=2/10=0.2,FPR=1/10=0.1;
- 当阈值为0.6时,样本1,2,3,4的”Score”值大于等于阈值,那么样本1,2,3,4为正类,其余为负类,则TPR=3/10=0.3,FPR=1/10=0.1;
- ———以此类推,此处省略一系列求解———
- 当阈值为0.1时,所有样本的”Score”值大于等于阈值,那么所有样本均为正类,则TPR=10/10=1,FPR=10/10=1。
将它们的结果画出来,就构成了下图:
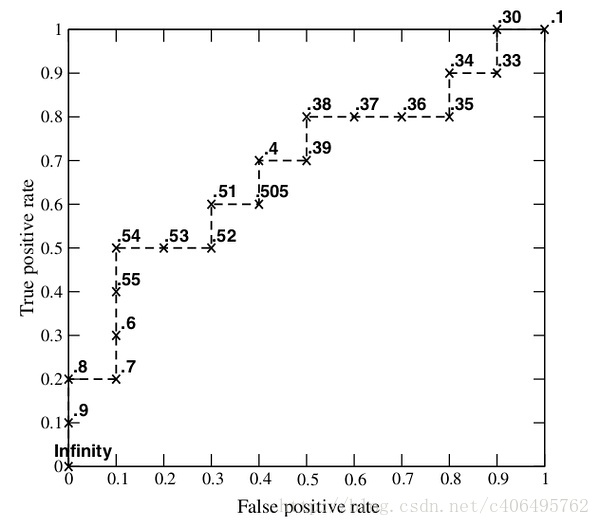
也许你已经发现了这样一个规律:多了一个TP,向Y轴移动一步,多了一个FP,向X轴移动一步。现在回头看一看绘制ROC曲线的程序吧,你会发现程序中也是如此计算的,只不过区别在于,程序是从<1.0,1.0>这个点开始画的。
AUC又是如何计算的呢?很简单,这些小矩形的宽度都是固定的xStep,因此先对所有矩形的高度进行累加,即ySum,最后面积就是ySum*xStep。