哈希(二)哈希桶
概念
哈希桶又被称作开链法,开散列法。相比于闭散列法哈希桶更为灵活直观,存数据时不会浪费空间,开散列法存数据时由于避免哈希冲突,总会有百分之三十的空间浪费,当存储空间很大时将会造成大量的浪费。同时开散列法造成哈希冲突时不便于查找数据。所以我们有了哈希结构中的哈希桶。
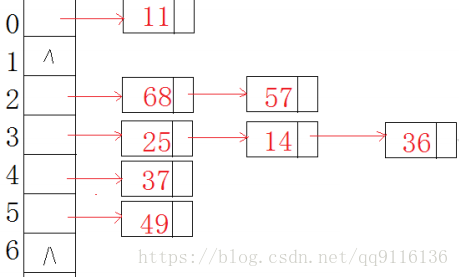
哈希桶与开散列法一样的是需要开一段数组用于映射,不过不一样的是哈希桶的数组存的是指针所以哈希桶是一段指针数组。数组中每一个位置都存着一段链表,当插入数据时不用处理哈希冲突,直接将数据链接在链表即可,哈希桶的结构如下所示。
负载因子
虽然哈希桶不会有哈希冲突,不过当一个桶中存在的数据过多时,也会造成查找的不便。于是我们根据此设计了哈希桶的负载因子,一般是控制在1左右,即size/N=1。当超过负载因子时进行扩容。
哈希桶函数设计
哈希桶函数设计如下:
首先定义哈希桶结构体
typedef int ValueType;
typedef struct HashNode
{
KeyType _key;
ValueType _value;
struct HashNode* _next;
}HashNode;
typedef struct HashTable
{
HashNode** _tables;
size_t _size;
size_t _N;
}HashTable;
- 初始化:由于哈希桶中存的是指针数组,所以我们首先需要在堆上给指针数组开空间,并且每一个指针置空。
{
ht->_N = GetNextPrimeNum(N);
ht->_tables = (HashNode**)malloc(sizeof(HashNode*)*ht->_N);
ht->_size = 0;
for (int i = 0;i < ht->_N;i++)
{
ht->_tables[i] = NULL;
}
}
- 创造节点:这里操作与链表相同,创造节点需要在堆上开空间
HashNode* BuyHashNode(KeyType key, ValueType value)
{
HashNode* newnode;
newnode = (HashNode*)malloc(sizeof(HashNode));
newnode->_key = key;
newnode->_value = value;
newnode->_next = NULL;
return newnode;
}- 扩容:这里扩容与闭散列有所不同,这里直接取下节点的指针连接到新的哈希桶中。
void HashInsertCapacity(HashTable* ht)
{
if (ht->_N == ht->_size)
{
HashTable newht;
HashTableInit(&newht,ht->_N);
for (int i = 0;i < ht->_N;i++)
{
HashNode* ptr = ht->_tables[i];
while (ptr != NULL)
{
HashNode* cur = ptr;
ptr = ptr->_next;
cur->_next = newht._tables[HashFunc(cur->_key,newht._N)];
newht._tables[HashFunc(cur->_key, newht._N)] = cur;
}
}
free(ht->_tables);
ht->_N = newht._N;
ht->_tables = newht._tables;
}
}- 插入:首先检查是否需要扩容,再计算位置头插即可
int HashTableInsert(HashTable* ht, KeyType key, ValueType value)
{
HashInsertCapacity(ht);
int index = HashFunc(key, ht->_N);
HashNode* cur = ht->_tables[index];
while (cur != NULL)
{
if (cur->_key == key)
{
return -1;
}
cur=cur->_next;
}
HashNode* newnode = BuyHashNode(key, value);
newnode->_next = ht->_tables[index];
ht->_tables[index] = newnode;
ht->_size++;
return 0;
}- 查找:这里与闭散列的查找相同,计算位置在链表里进行查找,找到了返回节点,找不到返回空指针。
HashNode* HashTableFind(HashTable* ht, KeyType key)
{
int index = HashFunc(key,ht->_N);
HashNode* cur = ht->_tables[index];
while (cur != NULL)
{
if (cur->_key == key)
{
return cur;
}
}
return NULL;
}- 删除:首先通过hashfunc算出位置,看要删除的是不是第一个元素,是的话直接free第一个元素,链表置空,不是的话给一个prev节点为需要删除的节点的上一个,然后找到要删除的节点,删除后将要删除节点后面的节点连接到prev节点上。
int HashTableRemove(HashTable* ht, KeyType key)
{
int index = HashFunc(key,ht->_N);
HashNode* prev = ht->_tables[index];
HashNode* ptr = ht->_tables[index]->_next;
if (ptr == NULL)
{
if(prev->_key == key)
{
free(prev);
ht->_tables[index] = NULL;
return 0;
}
else
{
return -1;
}
}
while (ptr != NULL)
{
if (ptr->_key == key)
{
prev->_next = ptr->_next;
free(ptr);
ht->_size--;
return 0;
}
ptr = ptr->_next;
}
return -1;
}