在这篇博客中介绍了基于线性探测解决哈希冲突的哈希表的基本操作。在这种方法中,当哈希表的负载因子较大时,在哈希表中查找数据时的搜索效率就比较低。本文中将介绍根据哈希桶解决哈希冲突的哈希表的一些基本操作。
这种解决哈希冲突的方法又称为开散列。
开散列
又称为链地址法。首先根据哈希函数计算出Key所在的下标位置,将下标相同但Key值不同的元素放在一条链表中,将该链表的头结点或头指针作为哈希表中的元素。这样对于哈希表中的每个元素,都可以视为一条链表。这样一个链表可以视为一个桶,所以这种解决哈希冲突的方法又称为哈希桶。
例如,现在要在哈希表中存放一组数据:1,6,5,12,11,15,25,7。哈希函数为hash(key) = key % m(m取10)。
首先根据哈希函数计算各key值所在的下标位置:
hash(1) = 1 hash(6) = 6 hash(5) = 5 hash(12) = 2
hash(11) = 1 hash(15) = 5 hash(25) = 5 hash(7) = 7
所以在哈希表中的存放为:
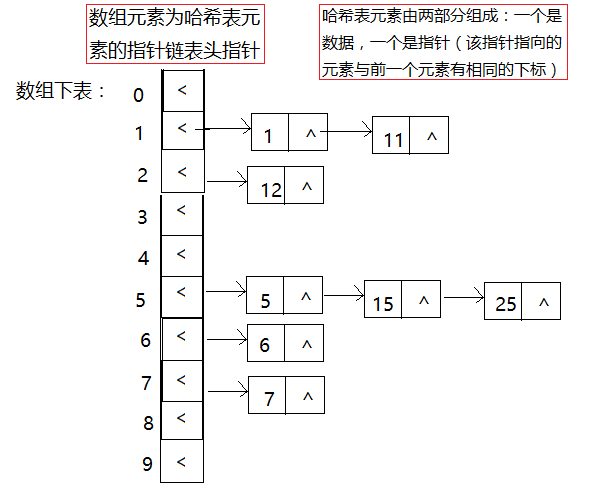
所以基于上述的哈希桶来构建一个哈希表,并进行一些基本操作。
1. 哈希表的结构定义
由上述定义我们知道,该哈希表由数组构成,数组中的元素为哈希表元素的指针。哈希表元素由一个键值对和指向下一个哈希表元素的指针构成。键值对与这篇博客中的类型相同。同时还需要定义哈希表中的实际元素个数(这里的哈希表元素个数与数组元素个数不是同一概念)。最后还需要指定哈希表的下标是由哪个哈希函数计算而得。
#define HASHMAXSIZE 1000//定义数组的最大长度
typedef int KeyType;
typedef int ValType;
//定义哈希表中的元素类型
//哈希表中的数组元素为节点指针类型,一个节点包含一个key,一个value,一个指向下一个节点的指针
typedef struct HashElemNode
{
KeyType key;
ValType value;
struct HashElemNode* next;
}HashElemNode;
typedef size_t (*HashFunc)(KeyType key);
//定义哈希表
typedef struct HashTable
{
HashElemNode* data[HASHMAXSIZE];//哈希表中的数组元素定义
size_t size;//哈希表的实际元素个数
HashFunc func;//哈希函数
}HashTable;
2. 哈希表的初始化
初始时,哈希表中并没有元素。所以,哈希表的成员size应置为0。
数组元素代表的是由相同下标的哈希表元素构成的单链表。因为单链表有带头结点和不带头节点之分。所以数组元素可以是链表的头结点,也可以是链表的头指针。如果是带头结点的单链表,此时需要将头结点的指针域置为NULL,数据域任意。如果不带头结点,此时需要将头指针置为NULL。这两种情况均用来表示空链表。在本文中,采用不带头节点的单链表。即数组元素为链表的头指针。
最后,在初始化时还需指定该哈希表使用哪个哈希函数来计算下标。
初始化代码如下:
//初始化哈希表
void HashInit(HashTable* ht,HashFunc func)
{
if(ht == NULL)
{
//非法输入
return;
}
//哈希表中的元素有两种表示方法:
//1. 直接存放节点的指针,表示不带头节点的链表,此时,初始化时,将所有数组元素即链表头指针置为NULL即可
//2. 存放节点,表示带头节点的链表。初始化时,将头节点的指针域置为NULL,数据域任意
//此处,选用不带头节点的链表
ht->size = 0;
ht->func = func;
size_t i = 0;
for(;i < HASHMAXSIZE;++i)
{
ht->data[i] = NULL;
}
return;
}
2. 向哈希表中插入元素
在向哈希表中插入元素时,如果哈希表元素过多,就会导致每条链表过长,此时,在查找哈希表中的元素时,就会效率过低。所以要控制哈希表中的元素个数。这里规定,当哈希表中每个链表的平均元素个数(哈希表的实际元素个数/数组长度)达到10,就需要扩容或插入失败。这里我们规定,如果达到10,就插入失败。
如果链表平均元素个数没有达到10,则进行下面的操作:
(1)根据哈希函数计算要插入Key值所在的下标
(2)如果该下标处的数组元素为空,即该数组元素所代表的的单链表为空,则创建该元素直接插入链表即可。
(3)如果数组元素不为空,即单链表不为空。此时,在该单链表中查找有无相同的Key值
a)如果有相同的Key值,可以将新Key值对应的Value替换原来的Value,或者将新的Key值也插入链表中,或者认为插入失败。这里我们规定,插入失败
b)如果在链表中没有相同的Key值,则创建新节点,将新的键值对插入到链表中,这里为方便操作,采取头插法进行插入。
(4)最后将哈希表元素个数加1即可。
代码如下:
//向哈希表中插入元素
void HashInsert(HashTable* ht,KeyType key,ValType value)
{
if(ht == NULL)
{
//非法输入
return;
}
//1. 如果哈希表中链表的平均长度大于等于10,则插入失败
if(ht->size >= 10*HASHMAXSIZE)
{
return;
}
//2. 根据key值计算offset
size_t offset = ht->func(key);
//3. 查找offset处的链表中有无要插入的key值,如果有,则插入失败
HashElemNode* to_find = HashFind(ht->data[offset],key);
if(to_find != NULL)//如果在哈希表中存在该元素
{
//插入失败
return;
}
//4. 如果没有,则对该处的链表进行头插
HashElemNode* new_node = CreateNode(key,value);
new_node->next = ht->data[offset];
ht->data[offset] = new_node;
//5. ++size
++ht->size;
return;
}
上述的在链表中查找Key值的代码实现如下:
HashElemNode* HashFind(HashElemNode* head,KeyType key)
{
HashElemNode* cur = head;
while(cur != NULL)
{
if(cur->key == key)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
上的创建节点函数实现如下:
//创建节点
HashElemNode* CreateNode(KeyType key,ValType value)
{
HashElemNode* new_node = (HashElemNode*)malloc(sizeof(HashElemNode));
new_node->key = key;
new_node->value = value;
new_node->next = NULL;
return new_node;
}
3. 在哈希表中查找指定Key处的Value
实现思路如下:
(1)首先如果哈希表中的元素个数为0,则说明哈希表为空,此时查找失败
(2)如果哈希表不为空,则根据指定的Key由哈希函数计算下标
(3)如果该下标处的数组元素为空,说明链表为空,说明要查找的Key不存在,此时查找失败
(4)如果数组元素不为空,则说明链表不为空,此时要对该链表进行查找。
a)如果遍历完链表还没找到指定的Key值,则说明要查找的元素不存在(与(3)可以合并操作)
b)如果在链表中找到了Key,则返回该处的Value值即可
实现代码如下:
//在哈希表中中查找元素
//返回值表示查找成功与否
//*value保存key处的value值
int HashFindEx(HashTable* ht,KeyType key,ValType* value)
{
if(ht == NULL || value == NULL)
{
//非法输入
return 0;
}
if(ht->size == 0)
{
//空表
return 0;
}
//1. 根据key值计算offset值
size_t offset = ht->func(key);
//2. 在offset下标处的链表中查找指定的key值
HashElemNode* to_find = HashFind(ht->data[offset],key);
if(to_find == NULL)
{
return 0;
}
else
{
*value = to_find->value;
return 1;
}
}
注意:上述代码中的查找函数使用的还是插入元素时的查找函数。
4. 在哈希表中删除指定Key值
实现思路如下:
(1)如果哈希表中的元素个数为0,即哈希表为空,则删除失败
(2)如果哈希表不为空,则根据指定的Key值计算其所在的下标
a)在该下标处的链表中查找指定的Key值,如果没找到,则删除失败
b)如果找到指定的Key值,就要对该Key处的结点进行删除。在删除时,还要知道该结点的前一个节点。所以,在对Key值进行查找时,同时要记录Key前一个节点的指针,以方便后续的删除操作
如果要删除结点的前一个节点为空,即要删除的是链表的第一个结点,此时直接将数组元素处的指针置为链表的第二个节点指针。
如果要删除结点的前一个节点不为空,即要删除的不是链表的第一个结点,此时直接使前一个结点的指针域指向要删除结点的下一个节点。
最后释放要删除的结点,在令哈希表元素个数减1即可。
代码实现如下:
//在哈希表中删除元素
void HashDelete(HashTable* ht,KeyType key)
{
if(ht == NULL)
{
//非法输入
return;
}
if(ht->size == 0)
{
//空表
return;
}
//1. 根据key计算offset
size_t offset = ht->func(key);
//2. 在offset处找到key值的指针,及其前一个节点处的指针
HashElemNode* cur_node;
HashElemNode* pre_node;
int ret = HashFindEx1(ht->data[offset],key,&cur_node,&pre_node);
if(ret == 0)
{
//没找到
return;
}
if(ret == 1)//如果找到要删除的节点
{
if(pre_node == NULL)//如果要删除的节点为头节点
{
ht->data[offset] = cur_node->next;
}
else
{
pre_node->next = cur_node->next;
}
}
//3. 释放key处的节点
DestroyNode(cur_node);
//--size
--ht->size;
return;
}
上述函数中的查找函数实现如下:
int HashFindEx1(HashElemNode* head,KeyType key,HashElemNode** cur,HashElemNode** pre)
{
HashElemNode* cur_node = head;
HashElemNode* pre_node = NULL;
while(cur_node != NULL)
{
if(cur_node->key == key)
{
*cur = cur_node;
*pre = pre_node;
return 1;
}
pre_node = cur_node;
cur_node = cur_node->next;
}
return 0;
}
5. 销毁哈希表
哈希表中的元素都是由一个个动态申请的结点组成,所以对哈希表进行销毁时,要对这些结点一一遍历进行释放。每个数组元素都表示一条链表,每条链表中都由一个个的结点组成,所以首先要遍历数组的每个元素,遍历到一个元素,在对该元素表示的链表进行遍历,释放节点。
同时还需要将哈希表中的元素个数置为0,哈希函数置为空。
实现代码如下:
//销毁节点
void DestroyNode(HashElemNode* node)
{
free(node);
return;
}
//销毁哈希表
void HashDestroy(HashTable* ht)
{
if(ht == NULL)
{
//非法输入
return;
}
//遍历哈希表中的每个元素所表示的单链表,将各个单链表中的元素节点进行释放
size_t i = 0 ;
for(;i < HASHMAXSIZE;++i)
{
HashElemNode* next = NULL;
HashElemNode* cur = ht->data[i];
while(cur != NULL)
{
next = cur->next;
DestroyNode(cur);
cur = next;
}
}
ht->size = 0;
ht->func = NULL;
return;
}