概述
用深度学习的方法进行端到端的时间序列预测需要一下几个步骤
1.对数据进行预处理,比如数据清洗,归一化等,然后把时间序列数据转化为监督问题数据。
2.进行基准方法的常识。基准方法可以选择基于常识的和基于简单机器学习的。
3.模型的搭建和与结果的对比
4.不断地调优模型
本文选用的例子为时间序列预测,数据集从这里下载,它由德国耶拿的马克思• 普朗克生物地球化学研究所的气象站记录。在这个数据集中,每10 分钟记录14 个不同的量(比如气温、气压、湿度、风向等),其中包含多年的记录。原始数据可追溯到2003 年,但本例仅使用2009—2016 年的数据。这个数据集非常适合用来学习处理数值型时间序列。我们将会用这个数据集来构建模型,输入最近的一些数据(几天的数据点),可以预测24 小时之后的气温。
数据集的预处理
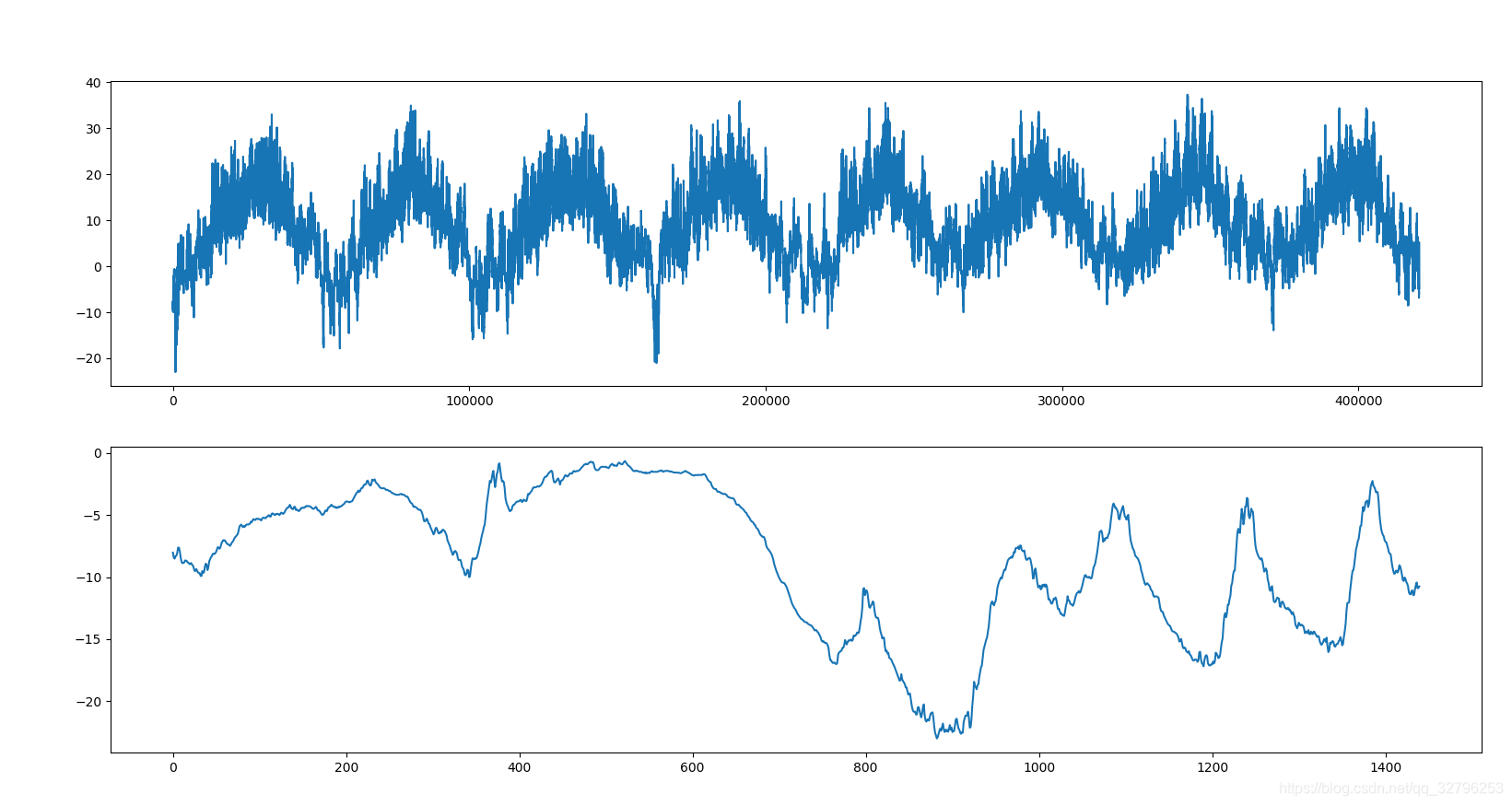
首先用pandas去读取数据并可视化,分别画出全部样本和10天的温度状况
import os
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
lookback = 1440
step = 6
delay = 144
batch_size = 128
data_dir = ''
fname = os.path.join(data_dir, 'jena_climate_2009_2016.csv')
df = pd.read_csv(fname)
print(df.head())
temp = df["T (degC)"].values
#要转化类型
float_data = df.values[:,1:].astype(np.float64)
#可视化样本
fig = plt.figure()
ax = fig.add_subplot(211)
ax.plot(range(len(temp)), temp)
ax2 = fig.add_subplot(212)
ax2.plot(range(1440), temp[:1440])
plt.show()
对数据进行标准化
mean = float_data[:200000].mean(axis=0)
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std
然后很重要的一点,将数据转成监督学习的模式,如果样本数比较大,需要写生成器来进行操作,并对训练集和测试集、验证集进行划分。
参数
lookback = 1440
step = 6
delay = 144
batch_size = 128
本次训练是用前10天的数据预测1天后的数据(1个点),训练是采样频率为1小时,即6个点采一个,训练批量为128.即批量训练的数据为[128,144*10/6,14],标签为[128,1]
def generator(data, lookback, delay, min_index, max_index,
shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(
min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows),
lookback // step,
data.shape[-1]))
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
train_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step,
batch_size=batch_size)
val_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step,
batch_size=batch_size)
test_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step,
batch_size=batch_size)
val_steps = (300000 - 200001 - lookback) // batch_size
基准方法
开始使用黑盒深度学习模型解决温度预测问题之前,我们先尝试一种基于常识的简单方法。它可以作为合理性检查,还可以建立一个基准,更高级的机器学习模型需要打败这个基准才能表现出其有效性。
本例中,我们可以放心地假设,温度时间序列是连续的(明天的温度很可能接近今天的温度),并且具有每天的周期性变化。因此,一种基于常识的方法就是始终预测24 小时后的温度等于现在的温度。我们使用平均绝对误差(MAE)指标来评估这种方法。
def evaluate_naive_method():
batch_maes = []
for step in range(val_steps):
samples, targets = next(val_gen)
preds = samples[:, -1, 1]
mae = np.mean(np.abs(preds - targets))
batch_maes.append(mae)
print(np.mean(batch_maes))
evaluate_naive_method()
然后我们常识基于简单神经网络的方式来计算
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Flatten(input_shape=(lookback // step, float_data.shape[-1])))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=3,
validation_data=val_gen,
validation_steps=val_steps)
model.save('tem_f.h5')
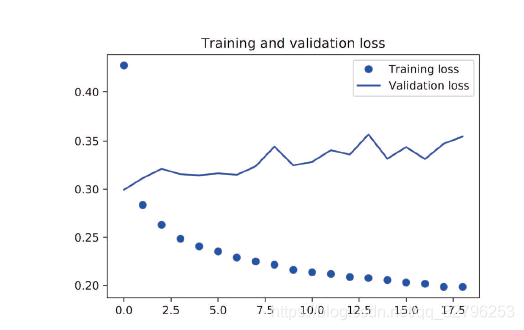
发现并不比常识好 ,这就证明了我们的常识中包含了大量有价值的信息,而机器学习模型并不知道这些信息,而且很难寻找。
用GRU去做,注意layers.GRU(32, input_shape=(None, float_data.shape[-1]))中32说的是这个层的隐藏神经元个数,就是几个门的权重的维度。
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.GRU(32, input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
发现效果好一点:

调优
增加dropout层
发现网络过拟合严重,就选用了dropout层
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.GRU(32,
dropout=0.2,
recurrent_dropout=0.2,
input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=40,
validation_data=val_gen,
validation_steps=val_steps)
结果如下:

发现没有过拟合了,但是结果没有太大提高。
增加网络深度
为了提高性能,我们选择增加网络容量。这是机器学习的通用工作流程:增加网络容直到过拟合变成主要的障碍(假设你已经采取基本步骤来降低过拟合,比如使用dropout)。只要过拟合不是太严重,那么很可能是容量不足的问题。
增加网络容量的通常做法是增加每层单元数或增加层数。
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.GRU(32,
dropout=0.1,
recurrent_dropout=0.5,
return_sequences=True,
input_shape=(None, float_data.shape[-1])))
model.add(layers.GRU(64, activation='relu',
dropout=0.1,
recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=40,
validation_data=val_gen,
validation_steps=val_steps)
我们发现过拟合仍然不是很严重,所以可以继续扩容,但计算成本提高,而且效果几乎没有。
小结和补充
有一步骤比较关键,就是时间序列转监督化的过程,这是预测和分类训练时最大差别。常见的序列转监督有两种,一种是直接转,另一种是用生成器,超长时间序列推荐用生成器。上文提到的就是生成器法,一些参量和感悟在这里少许分析一下。那么另一种直接法怎么写呢?就是一个函数
def create_dataset(dataset, look_back=1, delay):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1-delay):
a = dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back + delay])
return numpy.array(dataX), numpy.array(dataY)
对比一下生成器
def generator(data, lookback, delay, min_index, max_index,
shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(
min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows),
lookback // step,
data.shape[-1]))
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
使用生成器,在训练的时候,需要用函数model.fit_generator(),那么在验证的时候就要用对应的model.predict_generator(),注意在使用model.predict_generator(),一定要注意step这个参量,就是测试样本数/batch;
