Logging
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为
debug(), info(), warning(), error() and critical()5个级别,下面我们看一下怎么用。
最简单用法
import logging
logging.warning("user [alex] attempted wrong password more than 3 times")
logging.critical("server is down")
输出
WARNING:root:user [alex] attempted wrong password more than 3 times
CRITICAL:root:server is down日志级别

实例
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import logging
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt=' %Y/%m/%d %H:%M:%S', filename='myapp.log', filemode='w')
logger = logging.getLogger(__name__)
logging.debug('This is debug message')
logging.info('This is info message')
logging.warning('This is warning message')
日志写到文件里
import logging
logging.basicConfig(filename='example.log',level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
logging.basicConfig(filename='example.log',level=logging.INFO)自定义日志格式
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
输出
12/12/2010 11:46:36 AM is when this event was logged.
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.')
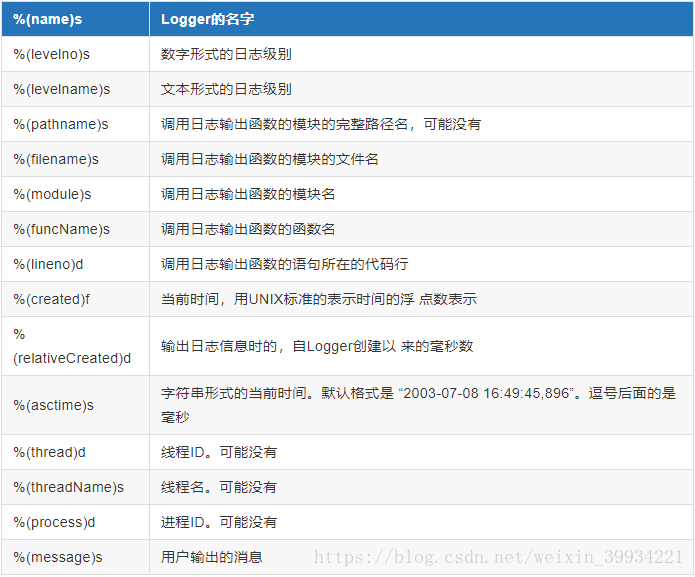
所有支持的格式
os模块
os 模块提供了很多允许你的程序与操作系统直接交互的功能
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() e.g os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext() e.g os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py')
获取路径名:os.path.dirname()
获得绝对路径: os.path.abspath()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取操作系统环境变量HOME的值:os.getenv("HOME")
返回操作系统所有的环境变量: os.environ
设置系统环境变量,仅程序运行时有效:os.environ.setdefault('HOME','/home/alex')
给出当前平台使用的行终止符:os.linesep Windows使用'\r\n',Linux and MAC使用'\n'
指示你正在使用的平台:os.name 对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
获取文件大小:os.path.getsize(filename)
结合目录名与文件名:os.path.join(dir,filename)
改变工作目录到dirname: os.chdir(dirname)
获取当前终端的大小: os.get_terminal_size()
杀死进程: os.kill(10884,signal.SIGKILL)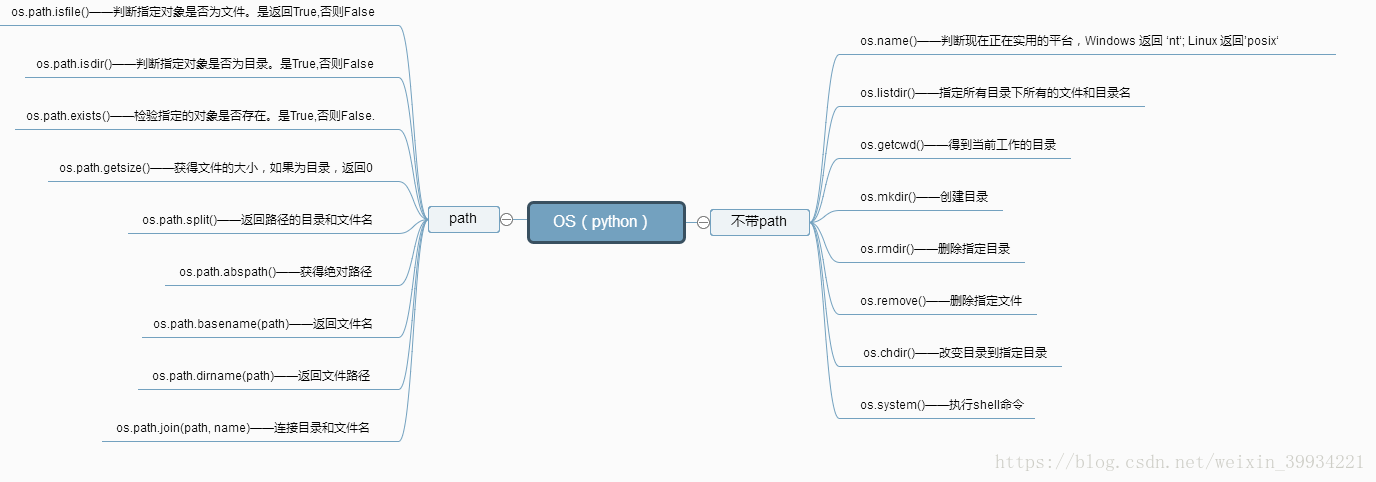
commands模块
Linux下独有的模块,用来执行linux命令的。cmd代表系统命令
commands.getoutput(cmd)
返回结果为cmd命令执行完的结果
status, output = commands.getstatusoutput(cmd)commands.getstatusoutput(cmd)的返回结果是一个tuple,第一个值是shell执行的结果,如果shell执行成功,返回0,否则,为非0,第二个是一个字符串,就是我们shell命令的执行结果,python通过一一对应的方式复制给status和output,这个就是python语言的额巧妙之处。
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
val = sys.stdin.readline()[:-1] #标准输入
sys.getrecursionlimit() #获取最大递归层数
sys.setrecursionlimit(1200) #设置最大递归层数
sys.getdefaultencoding() #获取解释器默认编码
sys.getfilesystemencoding #获取内存数据存到文件里的默认编码random模块
程序中有很多地方需要用到随机字符,比如登录网站的随机验证码,通过random模块可以很容易生成随机字符串
>>> random.randomrange(1,10) #返回1-10之间的一个随机数,不包括10
>>> random.randint(1,10) #返回1-10之间的一个随机数,包括10
>>> random.randrange(0, 100, 2) #随机选取0到100间的偶数
>>> random.random() #返回一个随机浮点数
>>> random.choice('abce3#$@1') #返回一个给定数据集合中的随机字符
'#'
>>> random.sample('abcdefghij',3) #从多个字符中选取特定数量的字符
['a', 'd', 'b']
#生成随机字符串
>>> import string
>>> ''.join(random.sample(string.ascii_lowercase + string.digits, 6))
'4fvda1'
#洗牌
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> random.shuffle(a)
>>> a
[3, 0, 7, 2, 1, 6, 5, 8, 9, 4]hashlib
Hash,一般翻译做“散列”,也有直接音译为”哈希”的,就是把任意长度的输入(又叫做预映射,pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,他把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值.也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系
MD5
什么是MD5算法 MD5讯息摘要演算法(英语:MD5 Message-Digest
Algorithm),一种被广泛使用的密码杂凑函数,可以产生出一个128位的散列值(hash
value),用于确保信息传输完整一致。MD5的前身有MD2、MD3和MD4。 MD5功能
输入任意长度的信息,经过处理,输出为128位的信息(数字指纹); 不同的输入得到的不同的结果(唯一性);
MD5算法的特点
压缩性:任意长度的数据,算出的MD5值的长度都是固定的 容易计算:从原数据计算出MD5值很容易
抗修改性:对原数据进行任何改动,修改一个字节生成的MD5值区别也会很大
强抗碰撞:已知原数据和MD5,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
MD5算法是否可逆?
MD5不可逆的原因是其是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
MD5用途
防止被篡改:
比如发送一个电子文档,发送前,我先得到MD5的输出结果a。然后在对方收到电子文档后,对方也得到一个MD5的输出结果b。如果a与b一样就代表中途未被篡改。
比如我提供文件下载,为了防止不法分子在安装程序中添加木马,我可以在网站上公布由安装文件得到的MD5输出结果。
SVN在检测文件是否在CheckOut后被修改过,也是用到了MD5.
防止直接看到明文:
现在很多网站在数据库存储用户的密码的时候都是存储用户密码的MD5值。这样就算不法分子得到数据库的用户密码的MD5值,也无法知道用户的密码。(比如在UNIX系统中用户的密码就是以MD5(或其它类似的算法)经加密后存储在文件系统中。当用户登录的时候,系统把用户输入的密码计算成MD5值,然后再去和保存在文件系统中的MD5值进行比较,进而确定输入的密码是否正确。通过这样的步骤,系统在并不知道用户密码的明码的情况下就可以确定用户登录系统的合法性。这不但可以避免用户的密码被具有系统管理员权限的用户知道,而且还在一定程度上增加了密码被破解的难度。)
防止抵赖(数字签名):
这需要一个第三方认证机构。例如A写了一个文件,认证机构对此文件用MD5算法产生摘要信息并做好记录。若以后A说这文件不是他写的,权威机构只需对此文件重新产生摘要信息,然后跟记录在册的摘要信息进行比对,相同的话,就证明是A写的了。这就是所谓的“数字签名”。
SHA-1
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard
DSS)里面定义的数字签名算法(Digital Signature Algorithm
DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。
SHA是美国国家安全局设计的,由美国国家标准和技术研究院发布的一系列密码散列函数。
由于MD5和SHA-1于2005年被山东大学的教授王小云破解了,科学家们又推出了SHA224, SHA256, SHA384,
SHA512,当然位数越长,破解难度越大,但同时生成加密的消息摘要所耗时间也更长。目前最流行的是加密算法是SHA-256 .
MD5与SHA-1的比较
由于MD5与SHA-1均是从MD4发展而来,它们的结构和强度等特性有很多相似之处,SHA-1与MD5的最大区别在于其摘要比MD5摘要长32
比特。对于强行攻击,产生任何一个报文使之摘要等于给定报文摘要的难度:MD5是2128数量级的操作,SHA-1是2160数量级的操作。产生具有相同摘要的两个报文的难度:MD5是264是数量级的操作,SHA-1
是280数量级的操作。因而,SHA-1对强行攻击的强度更大。但由于SHA-1的循环步骤比MD5多80:64且要处理的缓存大160比特:128比特,SHA-1的运行速度比MD5慢。
Python的 提供的相关模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...")
print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass
def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass
'''
import hashlib
# ######## md5 ########
hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest())
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest())
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest())
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest())
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())StringIO模块和BytesIO模块
在平时开发过程中,有些时候我们可能不需要写在文件中,我们可以直接通过StringIO模块直接写入到系统内存中,如果不用了,可以直接清除就可以了。StringIO主要是用来在内存中写入字符串的,及字符串的缓存。他的接口和文件操作的接口是一致的,基本所有关于文件的方法都可以
常用的方法和文件的方法是一样的,接受几个特殊的:
s.getvalue() 此函数没有参数,无论读写位置在哪里,都能够返回对象s中的所有数据。
s.truncate(0) 参数为0,表示清空所有写入的内容
s.flush() 刷新内部缓冲区。
b)BytesIO模块
StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。
from io import StringIO
f = StringIO()
f.write("hello world")
print(f.getvalue())