xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。从结构上,很像HTML超文本标记语言。但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。它被设计用来传输和存储数据,其焦点是数据的内容。那么Python是如何处理XML语言文件的呢?下面一起来看看Python常用内置模块之xml模块吧。
本文主要学习的ElementTree是python的XML处理模块,它提供了一个轻量级的对象模型。在使用ElementTree模块时,需要import xml.etree.ElementTree的操作。ElementTree表示整个XML节点树,而Element表示节点数中的一个单独的节点。
构建XML文件
ElementTree(tag),其中tag表示根节点,初始化一个ElementTree对象。
Element(tag, attrib={}, **extra)函数用来构造XML的一个根节点,其中tag表示根节点的名称,attrib是一个可选项,表示节点的属性。
SubElement(parent, tag, attrib={}, **extra)用来构造一个已经存在的节点的子节点 Element.text和SubElement.text表示element对象的额外的内容属性,Element.tag和Element.attrib分别表示element对象的标签和属性。
ElementTree.write(file, encoding='us-ascii', xml_declaration=None, default_namespace=None, method='xml'),函数新建一个XML文件,并且将节点数数据写入XML文件中。
下面以新建一个网站的sitemap.xml文件为例进行代码示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from
xml.etree
import
ElementTree as ET
def
build_sitemap():
urlset
=
ET.Element(
"urlset"
)
#设置一个根节点,标签为urlset
url
=
ET.SubElement(urlset,
"url"
)
#在根节点urlset下建立子节点
loc
=
ET.SubElement(url,
"loc"
)
loc.text
=
"http://www/baidu.com"
lastmod
=
ET.SubElement(url,
"lastmod"
)
lastmod.text
=
"2017-10-10"
changefreq
=
ET.SubElement(url,
"changefreq"
)
changefreq.text
=
"daily"
priority
=
ET.SubElement(url,
"priority"
)
priority.text
=
"1.0"
tree
=
ET.ElementTree(urlset)
tree.write(
"sitemap.xml"
)
if
__name__
=
=
'__main__'
:
build_sitemap()
|
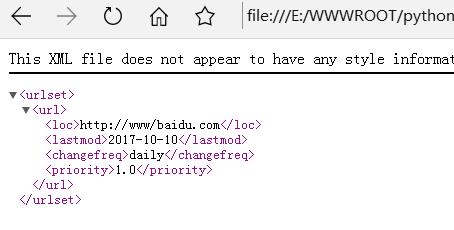
结果如下图所示:
解析和修改XML文件
ElementTree.parse(source, parser=None),将xml文件加载并返回ElementTree对象。parser是一个可选的参数,如果为空,则默认使用标准的XMLParser解析器。
ElementTree.getroot(),得到根节点。返回根节点的element对象。
Element.remove(tag),删除root下名称为tag的子节点 以下函数,ElementTree和Element的对象都包含。
find(match),得到第一个匹配match的子节点,match可以是一个标签名称或者是路径。返回个element findtext(match,default=None),得到第一个配置的match的element的内容 findall(match),得到匹配match下的所有的子节点,match可以是一个标签或者是路径,它会返回一个list,包含匹配的elements的信息 iter(tag),创建一个以当前节点为根节点的iterator。
还是以上面创建的sitemap.xml为例,对其进行一定的修改,代码示例如下:
|
1
2
3
4
5
6
7
8
9
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from
xml.etree
import
ElementTree as ET
tree
=
ET.parse(
"sitemap.xml"
)
url
=
tree.find(
"url"
)
for
rank
in
tree.
iter
(
'loc'
):
rank.text
=
"http://www.adminba.com"
tree.write(
"sitemap.xml"
)
|
以上的代码将url修改为http://www.adminba.com了。另外,节点还有set(设置节点属性)、attrib(删除节点属性)方法。
xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。从结构上,很像HTML超文本标记语言。但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。它被设计用来传输和存储数据,其焦点是数据的内容。那么Python是如何处理XML语言文件的呢?下面一起来看看Python常用内置模块之xml模块吧。
本文主要学习的ElementTree是python的XML处理模块,它提供了一个轻量级的对象模型。在使用ElementTree模块时,需要import xml.etree.ElementTree的操作。ElementTree表示整个XML节点树,而Element表示节点数中的一个单独的节点。
构建XML文件
ElementTree(tag),其中tag表示根节点,初始化一个ElementTree对象。
Element(tag, attrib={}, **extra)函数用来构造XML的一个根节点,其中tag表示根节点的名称,attrib是一个可选项,表示节点的属性。
SubElement(parent, tag, attrib={}, **extra)用来构造一个已经存在的节点的子节点 Element.text和SubElement.text表示element对象的额外的内容属性,Element.tag和Element.attrib分别表示element对象的标签和属性。
ElementTree.write(file, encoding='us-ascii', xml_declaration=None, default_namespace=None, method='xml'),函数新建一个XML文件,并且将节点数数据写入XML文件中。
下面以新建一个网站的sitemap.xml文件为例进行代码示例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from
xml.etree
import
ElementTree as ET
def
build_sitemap():
urlset
=
ET.Element(
"urlset"
)
#设置一个根节点,标签为urlset
url
=
ET.SubElement(urlset,
"url"
)
#在根节点urlset下建立子节点
loc
=
ET.SubElement(url,
"loc"
)
loc.text
=
"http://www/baidu.com"
lastmod
=
ET.SubElement(url,
"lastmod"
)
lastmod.text
=
"2017-10-10"
changefreq
=
ET.SubElement(url,
"changefreq"
)
changefreq.text
=
"daily"
priority
=
ET.SubElement(url,
"priority"
)
priority.text
=
"1.0"
tree
=
ET.ElementTree(urlset)
tree.write(
"sitemap.xml"
)
if
__name__
=
=
'__main__'
:
build_sitemap()
|
结果如下图所示:
解析和修改XML文件
ElementTree.parse(source, parser=None),将xml文件加载并返回ElementTree对象。parser是一个可选的参数,如果为空,则默认使用标准的XMLParser解析器。
ElementTree.getroot(),得到根节点。返回根节点的element对象。
Element.remove(tag),删除root下名称为tag的子节点 以下函数,ElementTree和Element的对象都包含。
find(match),得到第一个匹配match的子节点,match可以是一个标签名称或者是路径。返回个element findtext(match,default=None),得到第一个配置的match的element的内容 findall(match),得到匹配match下的所有的子节点,match可以是一个标签或者是路径,它会返回一个list,包含匹配的elements的信息 iter(tag),创建一个以当前节点为根节点的iterator。
还是以上面创建的sitemap.xml为例,对其进行一定的修改,代码示例如下:
|
1
2
3
4
5
6
7
8
9
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from
xml.etree
import
ElementTree as ET
tree
=
ET.parse(
"sitemap.xml"
)
url
=
tree.find(
"url"
)
for
rank
in
tree.
iter
(
'loc'
):
rank.text
=
"http://www.adminba.com"
tree.write(
"sitemap.xml"
)
|
以上的代码将url修改为http://www.adminba.com了。另外,节点还有set(设置节点属性)、attrib(删除节点属性)方法。