自编码器(Auto-encoder)
Auto-encoder输入前馈神经网络的一种,它借助了稀疏编码的思想,目标是借助抽取到的高阶特征来重构输入,而不只是简单的复制。auto-encoder曾经主要用于降维和特征抽取,现在被扩展到了生成模型。
Auto-encoder的模型架构可以简单地表示为:

实现流程为:

Auto-encoder的思想很简单,下面我们来看一下如何用代码实现,这里使用的是tensorflow2.0。
首先根据auto-encoder的网络模型,我们需要设计一个encoder用于得到latent code,然后再将其做为decoder的输入进行重构,目标是希望重构后的结果和encoder的输入越接近越好。
这里使用tensorflow.keras中的Sequential进行构建模型,同时需要定义编码和解码过程,这样我们便得到了一个基于卷积网络的auto-encoder。
# auto-encoder
class auto_encoder(keras.Model):
def __init__(self,latent_dim):
super(auto_encoder,self).__init__()
self.latent_dim = latent_dim
self.encoder = keras.Sequential([
keras.layers.InputLayer(input_shape = (28,28,1)),
keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'),
keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'),
keras.layers.Flatten(),
keras.layers.Dense(self.latent_dim)
])
self.decoder = keras.Sequential([
keras.layers.InputLayer(input_shape = (latent_dim,)),
keras.layers.Dense(units = 7 * 7 * 32,activation = 'relu'),
keras.layers.Reshape(target_shape = (7,7,32)),
keras.layers.Conv2DTranspose(
filters = 64,
kernel_size = 3,
strides = (2,2),
padding = "SAME",
activation = 'relu'),
keras.layers.Conv2DTranspose(
filters = 32,
kernel_size = 3,
strides = (2,2),
padding = "SAME",
activation = 'relu'),
keras.layers.Conv2DTranspose(
filters = 1,
kernel_size = 3,
strides = (1,1),
padding = "SAME"),
keras.layers.Conv2DTranspose(
filters = 1,
kernel_size = 3,
strides = (1,1),
padding = "SAME",
activation = 'sigmoid'),
])
def encode(self,x):
return self.encoder(x)
def decode(self,z):
return self.decoder(z)
模型定义结束后,我们需要定义它的训练过程,根据模型的思想,这里损失函数使用BinaryCrossentropy即可,通过比较输入和重构后的结果来得到loss,接着将其用于计算梯度,并进行反向传播更新参数,
# training
class train:
@staticmethod
def compute_loss(model,x):
loss_object = keras.losses.BinaryCrossentropy()
z = model.encode(x)
x_logits = model.decode(z)
loss = loss_object(x,x_logits)
return loss
@staticmethod
def compute_gradient(model,x):
with tf.GradientTape() as tape:
loss = train.compute_loss(model,x)
gradient = tape.gradient(loss,model.trainable_variables)
return gradient,loss
@staticmethod
def update(optimizer,gradients,variables):
optimizer.apply_gradients(zip(gradients,variables))
在开始训练后,我们首先读取MNIST数据集中一批次的图像,将其传入compute_gradient()中得到梯度和损失,最后进行参数更近即可。
# begin training
def begin():
train_dataset,test_dataset = load_data(batch_size)
model = auto_encoder(latent_dim)
optimizer = keras.optimizers.Adam(lr)
for epoch in range(num_epochs):
start = time.time()
last_loss = 0
for train_x,_ in train_dataset:
gradients,loss = train.compute_gradient(model,train_x)
train.update(optimizer,gradients,model.trainable_variables)
last_loss = loss
if epoch % 10 == 0:
print ('Epoch {},loss: {},Remaining Time at This Epoch:{:.2f}'.format(
epoch,last_loss,time.time()-start))
end = time.time()
print ('Total time is : %d',(end - start))
实验结果如下:
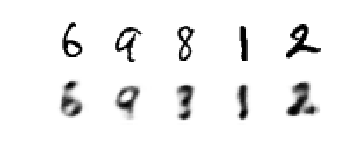

但是auto-encoder的压缩能力仅适用于和训练样本差不多的新样本,同时如果encoder和decoder的能力太强,那么模型完全实现了简单的记忆,而不是希望latent code可以表示输入的重要信息。
Denoising Auto-encoder(DAE)
为了防止模型只是简单的记忆,一种方式便是在输入中加入噪声,通过训练得到无噪声的输入,其中噪声可以是采样自高斯分布中的噪声,也可以是随即丢弃输入层的某个特征,类似于dropout。

此外还有很多类型的auto-encoder,例如Contrative Auto-encoder(CAE)、Stacked Auto-encoder(SAE)以及其他网络和auto-encoder结合的模型。
完整实现代码:
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 3 23:53:28 2019
@author: dyliang
"""
from __future__ import absolute_import,print_function,division
import tensorflow as tf
import tensorflow.keras as keras
import numpy as np
import matplotlib.pyplot as plt
import time
import plot
# auto-encoder
class auto_encoder(keras.Model):
def __init__(self,latent_dim):
super(auto_encoder,self).__init__()
self.latent_dim = latent_dim
self.encoder = keras.Sequential([
keras.layers.InputLayer(input_shape = (28,28,1)),
keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'),
keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'),
keras.layers.Flatten(),
keras.layers.Dense(self.latent_dim)
])
self.decoder = keras.Sequential([
keras.layers.InputLayer(input_shape = (latent_dim,)),
keras.layers.Dense(units = 7 * 7 * 32,activation = 'relu'),
keras.layers.Reshape(target_shape = (7,7,32)),
keras.layers.Conv2DTranspose(
filters = 64,
kernel_size = 3,
strides = (2,2),
padding = "SAME",
activation = 'relu'),
keras.layers.Conv2DTranspose(
filters = 32,
kernel_size = 3,
strides = (2,2),
padding = "SAME",
activation = 'relu'),
keras.layers.Conv2DTranspose(
filters = 1,
kernel_size = 3,
strides = (1,1),
padding = "SAME"),
keras.layers.Conv2DTranspose(
filters = 1,
kernel_size = 3,
strides = (1,1),
padding = "SAME",
activation = 'sigmoid'),
])
def encode(self,x):
return self.encoder(x)
def decode(self,z):
return self.decoder(z)
# training
class train:
@staticmethod
def compute_loss(model,x):
loss_object = keras.losses.BinaryCrossentropy()
z = model.encode(x)
x_logits = model.decode(z)
loss = loss_object(x,x_logits)
return loss
@staticmethod
def compute_gradient(model,x):
with tf.GradientTape() as tape:
loss = train.compute_loss(model,x)
gradient = tape.gradient(loss,model.trainable_variables)
return gradient,loss
@staticmethod
def update(optimizer,gradients,variables):
optimizer.apply_gradients(zip(gradients,variables))
# hpy
latent_dim = 100
num_epochs = 10
lr = 1e-4
batch_size = 1000
train_buf = 60000
test_buf = 10000
# load data
def load_data(batch_size):
mnist = keras.datasets.mnist
(train_data,train_labels),(test_data,test_labels) = mnist.load_data()
train_data = train_data.reshape(train_data.shape[0],28,28,1).astype('float32') / 255.
test_data = test_data.reshape(test_data.shape[0],28,28,1).astype('float32') / 255.
train_data = tf.data.Dataset.from_tensor_slices(train_data).batch(batch_size)
train_labels = tf.data.Dataset.from_tensor_slices(train_labels).batch(batch_size)
train_dataset = tf.data.Dataset.zip((train_data,train_labels)).shuffle(train_buf)
test_data = tf.data.Dataset.from_tensor_slices(test_data).batch(batch_size)
test_labels = tf.data.Dataset.from_tensor_slices(test_labels).batch(batch_size)
test_dataset = tf.data.Dataset.zip((test_data,test_labels)).shuffle(test_buf)
return train_dataset,test_dataset
# begin training
def begin():
train_dataset,test_dataset = load_data(batch_size)
model = auto_encoder(latent_dim)
optimizer = keras.optimizers.Adam(lr)
for epoch in range(num_epochs):
start = time.time()
last_loss = 0
for train_x,_ in train_dataset:
gradients,loss = train.compute_gradient(model,train_x)
train.update(optimizer,gradients,model.trainable_variables)
last_loss = loss
# if epoch % 10 == 0:
print ('Epoch {},loss: {},Remaining Time at This Epoch:{:.2f}'.format(
epoch,last_loss,time.time()-start))
plot.plot_AE(model, test_dataset)
if __name__ == '__main__':
begin()
